Ceph浅析
Ceph是统一存储系统,支持三种接口。
- Object:有原生的API,而且也兼容Swift和S3的API
- Block:支持精简配置、快照、克隆
- File:Posix接口,支持快照
Ceph也是分布式存储系统,它的特点是:
- 高扩展性:使用普通x86服务器,支持10~1000台服务器,支持TB到PB级的扩展。
- 高可靠性:没有单点故障,多数据副本,自动管理,自动修复。
- 高性能:数据分布均衡,并行化度高。对于objects storage和block storage,不需要元数据服务器。
-
组件
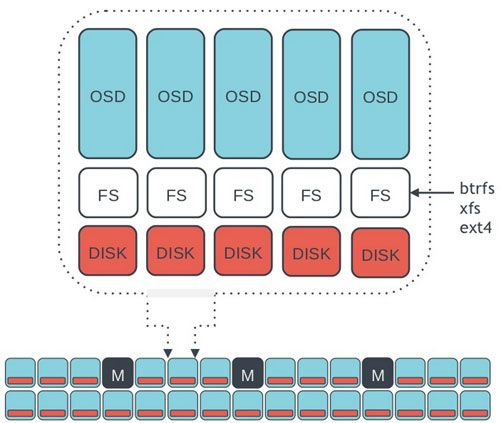
Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”。 RADOS由两个组件组成:
- OSD: Object Storage Device,提供存储资源。
- Monitor:维护整个Ceph集群的全局状态。
RADOS具有很强的扩展性和可编程性,Ceph基于RADOS开发了
Object Storage、Block Storage、FileSystem。Ceph另外两个组件是:- MDS:用于保存CephFS的元数据。
- RADOS Gateway:对外提供REST接口,兼容S3和Swift的API。
映射
Ceph的命名空间是 (Pool, Object),每个Object都会映射到一组OSD中(由这组OSD保存这个Object):
(Pool, Object) → (Pool, PG) → OSD set → Disk
Ceph中Pools的属性有:
- Object的副本数
- Placement Groups的数量
- 所使用的CRUSH Ruleset
在Ceph中,Object先映射到PG(Placement Group),再由PG映射到OSD set。每个Pool有多个PG,每个Object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD(OSD的个数由Pool 的副本数决定),第一个OSD是Primary,剩下的都是Replicas。
数据映射(Data Placement)的方式决定了存储系统的性能和扩展性。(Pool, PG) → OSD set 的映射由四个因素决定:
- CRUSH算法:一种伪随机算法。
- OSD MAP:包含当前所有Pool的状态和所有OSD的状态。
- CRUSH MAP:包含当前磁盘、服务器、机架的层级结构。
- CRUSH Rules:数据映射的策略。这些策略可以灵活的设置object存放的区域。比如可以指定 pool1中所有objecst放置在机架1上,所有objects的第1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务器B上。 pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的服务器上,第2个副本分布在机架3的服 器上,第3个副本分布在机架4的服务器上。
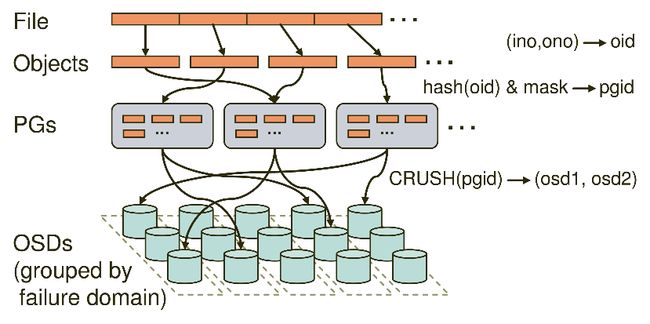
Client从Monitors中得到CRUSH MAP、OSD MAP、CRUSH Ruleset,然后使用CRUSH算法计算出Object所在的OSD set。所以Ceph不需要Name服务器,Client直接和OSD进行通信。伪代码如下所示:
locator = object_name obj_hash = hash(locator) pg = obj_hash % num_pg osds_for_pg = crush(pg) # returns a list of osds primary = osds_for_pg[0] replicas = osds_for_pg[1:]
这种数据映射的优点是:
- 把Object分成组,这降低了需要追踪和处理metadata的数量(在全局的层面上,我们不需要追踪和处理每个object的metadata和placement,只需要管理PG的metadata就可以了。PG的数量级远远低于object的数量级)。
- 增加PG的数量可以均衡每个OSD的负载,提高并行度。
- 分隔故障域,提高数据的可靠性。
强一致性
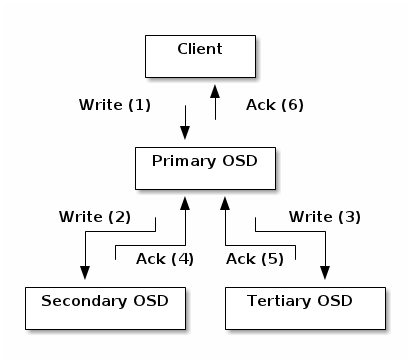
- Ceph的读写操作采用Primary-Replica模型,Client只向Object所对应OSD set的Primary发起读写请求,这保证了数据的强一致性。
- 由于每个Object都只有一个Primary OSD,因此对Object的更新都是顺序的,不存在同步问题。
- 当Primary收到Object的写请求时,它负责把数据发送给其他Replicas,只要这个数据被保存在所有的OSD上时,Primary才应答Object的写请求,这保证了副本的一致性。
容错性
在分布式系统中,常见的故障有网络中断、掉电、服务器宕机、硬盘故障等,Ceph能够容忍这些故障,并进行自动修复,保证数据的可靠性和系统可用性。
- Monitors是Ceph管家,维护着Ceph的全局状态。Monitors的功能和zookeeper类似,它们使用Quorum和Paxos算法去建立全局状态的共识。
- OSDs可以进行自动修复,而且是并行修复。
故障检测:
OSD之间有心跳检测,当OSD A检测到OSD B没有回应时,会报告给Monitors说OSD B无法连接,则Monitors给OSD B标记为down状态,并更新OSD Map。当过了M秒之后还是无法连接到OSD B,则Monitors给OSD B标记为out状态(表明OSD B不能工作),并更新OSD Map。
备注:可以在Ceph中配置M的值。
故障恢复:
- 当某个PG对应的OSD set中有一个OSD被标记为down时(假如是Primary被标记为down,则某个Replica会成为新的Primary,并处理所有读写 object请求),则该PG处于active+degraded状态,也就是当前PG有效的副本数是N-1。
- 过了M秒之后,假如还是无法连接该OSD,则它被标记为out,Ceph会重新计算PG到OSD set的映射(当有新的OSD加入到集群时,也会重新计算所有PG到OSD set的映射),以此保证PG的有效副本数是N。
- 新OSD set的Primary先从旧的OSD set中收集PG log,得到一份Authoritative History(完整的、全序的操作序列),并让其他Replicas同意这份Authoritative History(也就是其他Replicas对PG的所有objects的状态达成一致),这个过程叫做Peering。
- 当Peering过程完成之后,PG进 入active+recoverying状态,Primary会迁移和同步那些降级的objects到所有的replicas上,保证这些objects 的副本数为N。
优点
高性能
- Client和Server直接通信,不需要代理和转发
- 多个OSD带来的高并发度。objects是分布在所有OSD上。
- 负载均衡。每个OSD都有权重值(现在以容量为权重)。
- client不需要负责副本的复制(由primary负责),这降低了client的网络消耗。
高可靠性
- 数据多副本。可配置的per-pool副本策略和故障域布局,支持强一致性。
- 没有单点故障。可以忍受许多种故障场景;防止脑裂;单个组件可以滚动升级并在线替换。
- 所有故障的检测和自动恢复。恢复不需要人工介入,在恢复期间,可以保持正常的数据访问。
- 并行恢复。并行的恢复机制极大的降低了数据恢复时间,提高数据的可靠性。
高扩展性
- 高度并行。没有单个中心控制组件。所有负载都能动态的划分到各个服务器上。把更多的功能放到OSD上,让OSD更智能。
- 自管理。容易扩展、升级、替换。当组件发生故障时,自动进行数据的重新复制。当组件发生变化时(添加/删除),自动进行数据的重分布。
测试
使用fio测试RBD的IOPS,使用dd测试RBD的吞吐率,下面是测试的参数:
- fio的参数:bs=4K, ioengine=libaio, iodepth=32, numjobs=16, direct=1
- dd的参数:bs=512M,oflag=direct
我们的测试服务器是AWS上最强的实例:
- 117GB内存
- 双路 E5-2650,共16核
- 24 * 2TB 硬盘
服务器上的操作系统是Ubuntu 13.04,安装Ceph Cuttlefish 0.61版,副本数设置为2,RBD中的块大小设置为1M。为了对比,同时还对软件RAID10进行了测试。下面表格中的性能比是Ceph与RAID10性能之间的比较。
因为使用的是AWS上的虚拟机,所以它(Xen)挂载的磁盘都是设置了Cache的。因此下面测试的数据并不能真实反应物理磁盘的真实性能,仅供与RAID10进行对比。
IOPS
磁盘数 随机写 随机读 Ceph RAID10 性能比 Ceph RAID10 性能比 24 1075 3772 28% 6045 4679 129% 12 665 1633 40% 2939 4340 67% 6 413 832 49% 909 1445 62% 4 328 559 58% 666 815 81% 2 120 273 43% 319 503 63% 吞吐率
磁盘数 顺序写(MB/S) 顺序读(MB/S) Ceph RAID10 性能比 Ceph RAID10 性能比 24 299 879 33% 617 1843 33% 12 212 703 30% 445 1126 39% 6 81 308 26% 233 709 32% 4 67 284 23% 170 469 36% 2 34 153 22% 90 240 37% 结果分析
从测试结果中,我们看到在单机情况下,RBD的性能不如RAID10,这是为什么?我们可以通过三种方法找到原因:
- 阅读Ceph源码,查看I/O路径
- 使用blktrace查看I/O操作的执行
- 使用iostat观察硬盘的读写情况
RBD的I/O路径很长,要经过网络、文件系统、磁盘:
Librbd -> networking -> OSD -> FileSystem -> DiskClient的每个写操作在OSD中要经过8种线程,写操作下发到OSD之后,会产生2~3个磁盘seek操作:
- 把写操作记录到OSD的Journal文件上(Journal是为了保证写操作的原子性)。
- 把写操作更新到Object对应的文件上。
- 把写操作记录到PG Log文件上。
我使用fio向RBD不断写入数据,然后使用iostat观察磁盘的读写情况。在1分钟之内,fio向RBD写入了3667 MB的数据,24块硬盘则被写入了16084 MB的数据,被读取了288 MB的数据。
向RBD写入1MB数据 = 向硬盘写入4.39MB数据 + 读取0.08MB数据
在单机情况下,RBD的性能不如传统的RAID10,这是因为RBD的I/O路径很复杂,导致效率很低。但是Ceph的优势在于它的扩展性,它的性能会随着磁盘数量线性增长,因此在多机的情况下,RBD的IOPS和吞吐率会高于单机的RAID10(不过性能会受限于网络的带宽)。
如前所述,Ceph优势显著,使用它能够降低硬件成本和运维成本,但它的复杂性会带来一定的学习成本。
Ceph的特点使得它非常适合于云计算,那么OpenStack使用Ceph的效果如何?下期《Ceph与OpenStack》将会介绍Ceph的自动化部署、Ceph与OpenStack的对接。