Zookeeper学习三:HA学习
Zookeeper学习三:HA学习
标签(空格分隔): zookeeper
- Zookeeper学习三HA学习
- 一HA概述
- 二HA的安装和配置
- 三HA自动故障转移配置和测试
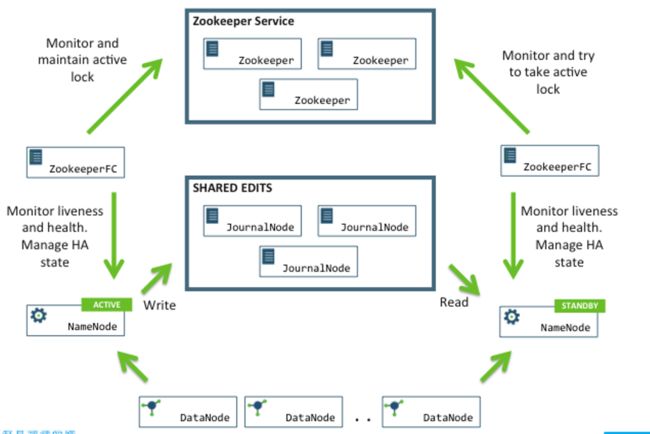
一,HA概述
HA:配置2个namenode,其中一个是另外一个热备
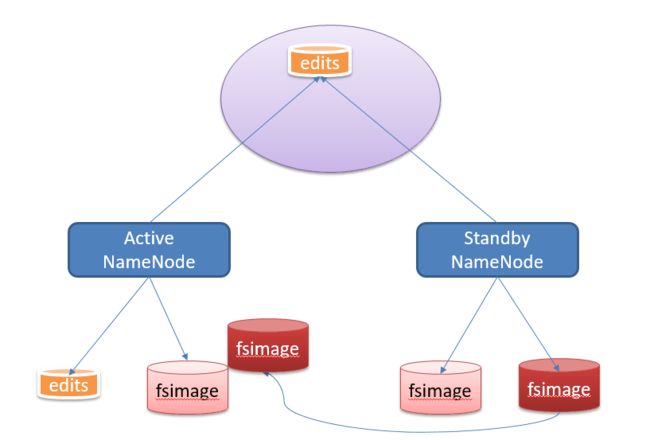
(1)如何保证2个namenode的数据(fsimage和edits log)一致性:
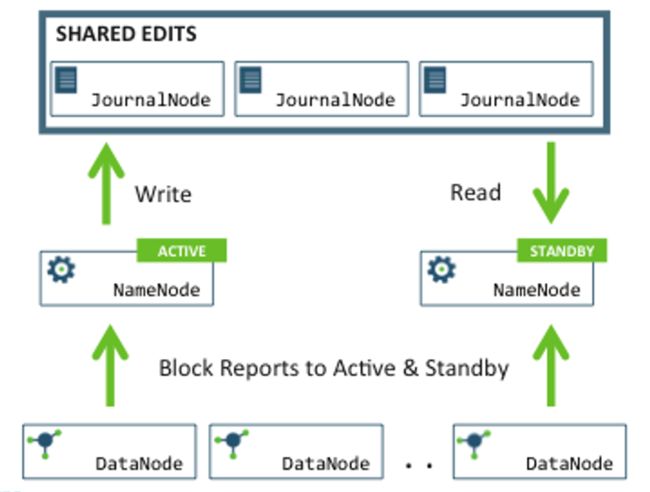
(2)只有一台namenode对外提供服务(proxy)
(3)接受datanode的心跳
(4)隔离
二,HA的安装和配置
1,角色分配
hadoop001.com.cn—namenode—-active
hadoop002.com.cn—namenode—-stand by
2,修改hdfs-site.xml配置文件:
[hadoop001@hadoop001 hadoop-2.5.0]$ mkdir qjournal
[hadoop001@hadoop001 tmp]$ rm -rf ./*<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop001.com.cn:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop002.com.cn:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop001.com.cn:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop002.com.cn:50070</value>
</property>
<!--指定JournalNode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001.com.cn:8485;hadoop002.com.cn:8485;hadoop003.com.cn:8485/cluster1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.5.0/qjournal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop001/.ssh/id_rsa</value>
</property>
</configuration>3,修改core-site.xml配置文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.5.0/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
</configuration>4,将hdfs-site.xml和core-site.xml文件拷贝到其它服务器上并且执行如下操作
[hadoop001@hadoop001 hadoop-2.5.0]$ mkdir qjournal
[hadoop001@hadoop001 tmp]$ rm -rf ./*5,启动HA
//Step1 :在各个JournalNode节点上,输入以下命令启动journalnode服务
sbin/hadoop-daemon.sh start journalnode//Step2:在[nn1]上,对其进行格式化,并启动
$ bin/hdfs namenode -format
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode//Step3:在[nn2]上,同步nn1的元数据信息
$ bin/hdfs namenode -bootstrapStandby//Step4:启动[nn2]:
$ sbin/hadoop-daemon.sh start namenode//Step5:将[nn1]切换为Active
$ bin/hdfs haadmin -transitionToActive nn1//Step6:在[nn1]上,启动所有datanode
$ sbin/hadoop-daemons.sh start datanode
三,HA自动故障转移配置和测试
1,修改core-site.xml配置文件
添加如下配置:
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop001.com.cn:2181,hadoop002.com.cn:2181,hadoop003.com.cn:2181</value>
</property>2,修改hdfs-site.xml配置文件:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>3,将hdfs-site.xml和core-site.xml文件复制到其他服务器上
4,启动
关闭所有HDFS 服务 sbin/stop-dfs.sh
启动Zookeeper 集群 bin/zkServer.sh start
初始化 HA 在Zookeeper中状态 bin/hdfs zkfc -formatZK
启动HDFS服务 sbin/start-dfs.sh
在各个NameNode节点上启动DFSZK Failover Controller,先在那台机器启动,那个机器的NameNode就是Active NameNode
sbin/hadoop-daemon.sh start zkfc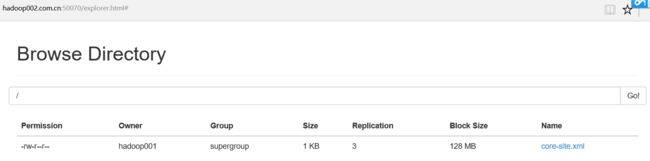
5,测试
[hadoop001@hadoop002 hadoop-2.5.0]$ kill 12185
6,总结