蓝鲸python第一题个人理解运行版
>>> s = ‘this is a Chinese character:汉’
>>> s
‘this is a Chinese character:/xe6/xb1/x89′
>>> print s
this is a Chinese character:汉
>>> str(s)
‘this is a Chinese character:/xe6/xb1/x89′
>>> print str(s)
this is a Chinese character:汉
>>> repr(s)
“‘this is a Chinese character://xe6//xb1//x89′”
>>> print repr(s)
‘this is a Chinese character:/xe6/xb1/x89′
也就是说 一个访问的是对象的__repr__, 另一个访问的是对象的 __str__
另外,谈一下关于python中的中文编码问题,我们常说的Unicode是一种编码方案,又称万国码,可见其包含之广。但是具体存储到计算机上,并不用这种编码,而是用自身默认的编码方式,utf-8是互联网上使用的最广的一种Unicode的实现方式。UTF-8或者gbk也可以进行解码(decode)还原为Unicode。在python中Unicode是一类对象,表现为以u打头的,比如u'中文',而string又是一类对象,是在具体编码方式下的实际存在计算机上的字符串。比如utf-8编码下的'中文'和gbk编码下的汉字“中华”,并不相同。例如

可能有人对unicode和UTF-8的关系还是不是很了解,这么说吧,Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
搞清三者关系后,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
然后我就可以对这道题作答了:
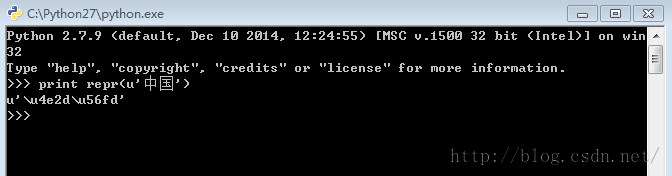
print repr(u‘中国’)的输出结果是