数据挖掘的一个例子
干货来啦~
数据库版本:oracle database 11.2.0.1.0
sqldeveloper版本:3.0
例子的目标是预测SH用户下customer拥有信用卡的概率
首先你要有一个建立一个用于data mining的用户,然后通过sqldeveloper图形界面创建data mining资料库
资料库建好之后准备工作也就基本完成了(别跟我说没装oracle database =_=|||)
首先我们需要创建用于数据挖掘的几个视图,为了方便起见(懒癌发作),test模型用的数据我们就不要了,我们要的就是build data 和 apply data。
Build data的试图创建语句如下:
create view build_data as SELECT a.CUST_ID, a.CUST_GENDER, 2003-a.CUST_YEAR_OF_BIRTH AGE, a.CUST_MARITAL_STATUS, c.COUNTRY_NAME, a.CUST_INCOME_LEVEL, b.EDUCATION, b.OCCUPATION, b.HOUSEHOLD_SIZE, b.YRS_RESIDENCE, b.AFFINITY_CARD, b.BULK_PACK_DISKETTES, b.FLAT_PANEL_MONITOR, b.HOME_THEATER_PACKAGE, b.BOOKKEEPING_APPLICATION, b.PRINTER_SUPPLIES, b.Y_BOX_GAMES, b.OS_DOC_SET_KANJI FROM sh.customers a, sh.supplementary_demographics b, sh.countries c WHERE a.CUST_ID = b.CUST_ID AND a.country_id = c.country_id AND a.cust_id between 100001 and 101500
Apply data的视图创建语句如下:
create view apply_data as SELECT a.CUST_ID, a.CUST_GENDER, 2003-a.CUST_YEAR_OF_BIRTH AGE, a.CUST_MARITAL_STATUS, c.COUNTRY_NAME, a.CUST_INCOME_LEVEL, b.EDUCATION, b.OCCUPATION, b.HOUSEHOLD_SIZE, b.YRS_RESIDENCE, b.BULK_PACK_DISKETTES, b.FLAT_PANEL_MONITOR, b.HOME_THEATER_PACKAGE, b.BOOKKEEPING_APPLICATION, b.PRINTER_SUPPLIES, b.Y_BOX_GAMES, b.OS_DOC_SET_KANJI FROM sh.customers a, sh.supplementary_demographics b, sh.countries c WHERE a.CUST_ID = b.CUST_ID AND a.country_id = c.country_id AND a.cust_id between 101501 and 103000
视图建立好之后,我们要开始创建data mining工作流程了
我们首先要建立数据库连接
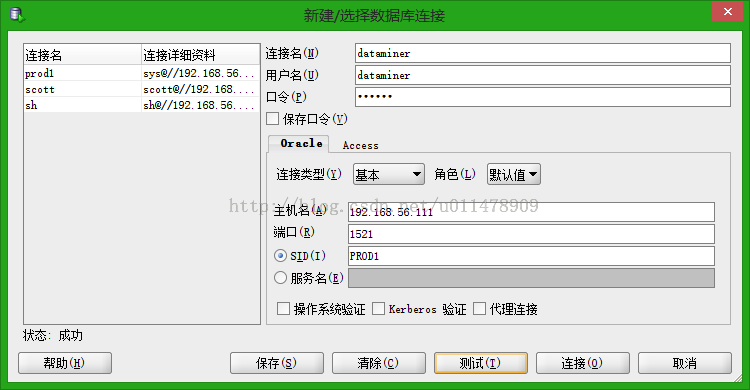
测试成功后,点击连接按钮即可。
然后右击建立的连接,选择新建项目。
我们的项目名就用默认的Project1,然后右击Project1
创建工作流程。
我们使用默认名称workflow。
在组件调色盘中选择数据源
然后选择自己创建了的build_data
成功后如图所示
然后再模型面板中选择分类模型
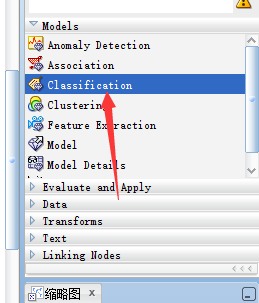
将数据源与模型相连接
目标选择信用卡字段

点击确认,然后运行该模型。
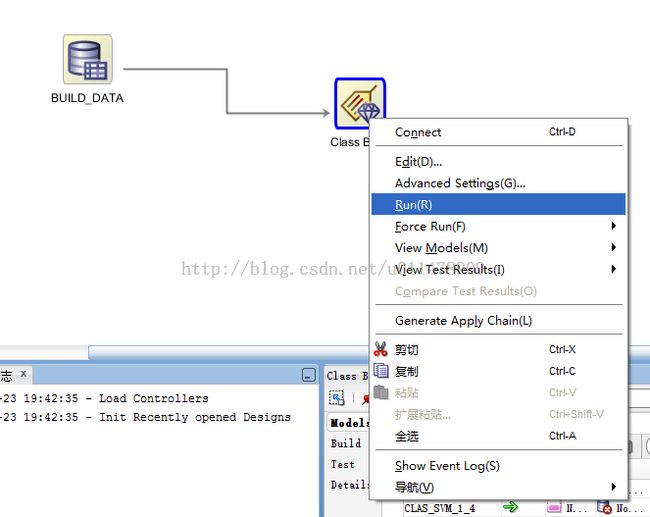
运行完成之后,我们对比各种算法的置信度

对比结果如下:
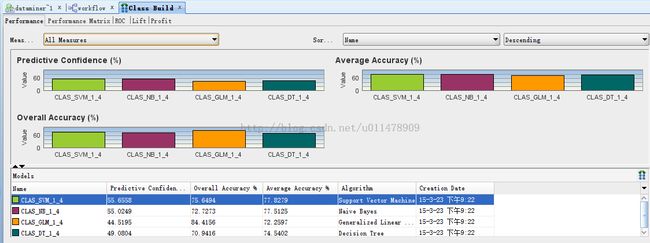
对比后决定选择朴素贝叶斯算法
然后选择模型详细信息,至于class build结点右侧
然后连接两节点,运行model details结点
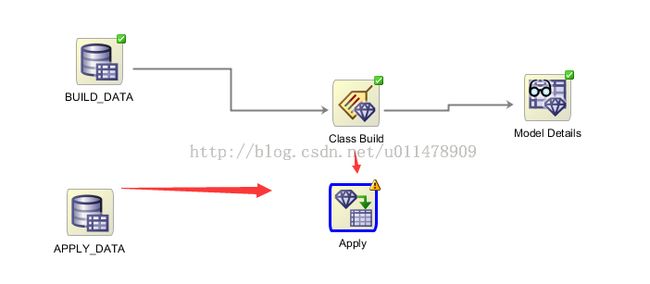
选择应用的数据源(同创建数据源)
再选择apply结点
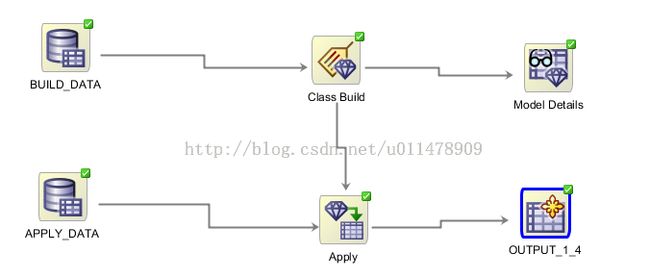
接下来将三结点相连接。
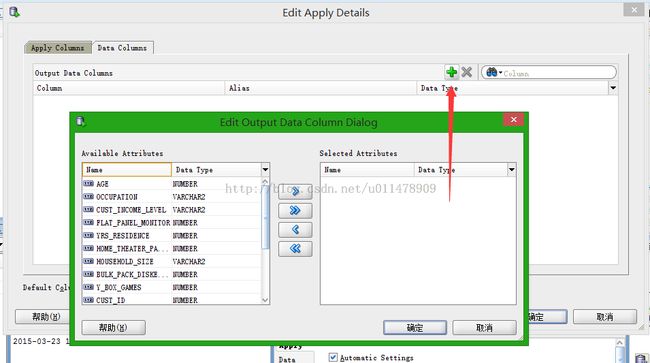
为了方便观察,我们将用户ID在模型输出结果中显示出来。
选择cust_id字段点击确认即可。
然后运行apply结点。
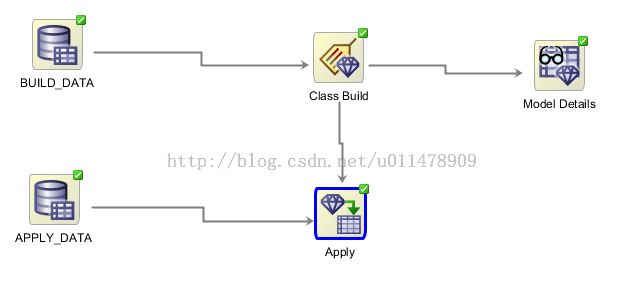
最后将结果导出

如图,一次简单的数据挖掘就完成了
我们可以右键点击查看预测的数据
或者直接用sql查看数据
由于我们应用的数据cust_id的范围是101501 到 103000
所以我们可以查询出ID范围是101501 到 103000的用户的真实数据来和预测数据进行对比。
查询语句如下:
select a.cust_id, a.clas_nb_1_4_pred pred_value, b.affinity_card true_value, a.clas_nb_1_4_prob from OUTPUT_1_4 a, sh.supplementary_demographics b where a.cust_id=b.cust_id(+) order by cust_id
