蓝鲸Python第一题
python 的输出函数print str repr pprint
$ python
Python 2.5.5 (r255:77872, Apr 21 2010, 08:40:04)
[GCC 4.4.3] on linux2
Type “help”, “copyright”, “credits” or “license” for more information.
>>> s = ‘this is a Chinese character:汉’
>>> s
‘this is a Chinese character:/xe6/xb1/x89′
>>> print s
this is a Chinese character:汉
直接输入s,是调用 repr 函数, 而print 是调用str函数
也就是说 一个访问的是对象的__repr__, 另一个访问的是对象的 __str__
>>> str(s)
‘this is a Chinese character:/xe6/xb1/x89′
>>> print str(s)
this is a Chinese character:汉
>>> repr(s)
“‘this is a Chinese character://xe6//xb1//x89′”
>>> print repr(s)
‘this is a Chinese character:/xe6/xb1/x89′
在解释器的交互模式输入 str(s), 相当于调用 repr(str(s))
还可以使用 % 操作符 来格式化字符串, Python总是把任意类型的值传给 repr() 或 str() 函数
str() 用于将值转化为适于人阅读的形式,而 repr() 转化为供解释器读取的形式
某对象没有适于人阅读的解释形式的话, str() 会返回与 repr() 等同的值。
可以看看 webpy的代码, 它对自定义的Storage类型, 就实现了 __repr__
def __repr__(self):
return ” ” % ()
类似,也可实现 __str__
对于dict, list, tuple等类型, str()其实还是调用repr来实现的
实例如下
x = {“version”:”1.00″,”mode”:0}
s = str(x)
t = type(x)
print t
print s
print x
还有注意pprint的模块, 对于某些对象, repr表示不是很好看, str也不好看, 用pprint.pprint 就可以格式化得很漂亮,真不愧是 pretty print
还要注意 dict 和 % 的一种高级用法
>>> table = {‘Sjoerd’: 4127, ‘Jack’: 4098, ‘Dcab’: 7678}
>>> print ‘%(Jack)d; %(Sjoerd)d; %(Dcab)d’ % table
4098; 4127; 7678
repr 是 buit-in函数, repr是representation的缩写, 返回一个 含有 含有某个对象的可打印的表示形式 的 字符串.
还有一个 repr 模块, 可以用来替换内建同名函数. 该模块与内建函数不同的是它限制了很多输出形式: 他只会 输出字符串的前 30 个字符, 它只打印嵌套数据结构的几个等级, 等等.
pprint 模块( pretty printer )用于打印 Python 数据结构. 当你在命令行下打印 特定数据结构时你会发现它很有用(输出格式比较整齐, 便于阅读).
python的中文编码问题
问题要从文字的编码讲起。原本的英文编码只有0~255(28),刚好是8位1个字节。为了使计算机表示各种不同的语言,1个字节是大大不够的,自然要进行扩充。中文的话有GB系列、UTF-8,那么,它们之间是什么关系呢?
Unicode是一种编码方案,又称万国码,可见其包含之广。但是具体存储到计算机上,并不用这种编码,而是用自身默认的编码方式,utf-8是互联网上使用的最广的一种Unicode的实现方式。UTF-8或者gbk也可以进行解码(decode)还原为Unicode。
在python中Unicode是一类对象,表现为以u打头的,比如u'中文',而string又是一类对象,是在具体编码方式下的实际存在计算机上的字符串。比如utf-8编码下的'中文'和gbk编码下的汉字“中华”,并不相同。例如

设计python的几个函数
encode():编码
decode():解码
repr():返回一个可以用来表示对象的可打印的字串
默认编码问题
#coding: gbk str1 = '汗' print repr(str1) str2 = u'汗' print repr(str2) str3 = str2.encode('utf-8') str4 = str2.encode('gbk') print repr(str3) print repr(str4) str5 = str3.decode('utf-8') print repr(str5)
执行程序出现问题:
![]()
说gbk编码器不能解码。原因是何?看看自己的linux配置,用命令“locale”

其中,与中文输入关系最密切的就是 LC_CTYPE, LC_CTYPE 规定了系统内有效的字符以及这些字符的分类,诸如什么是大写字母,小写字母,大小写转换,标点符号、可打印字符和其他的字符属性等方面。而locale定义zh_CN中最最重要的一项就是定义了汉字(Class “hanzi”)这一个大类,当然也是用Unicode描述的,这就让中文字符在Linux系统中成为合法的有效字符,而且不论它们是用什么字符集编码的。
简单说:程序中写了个str1 = '汗',默认编码是utf-8,当赋予变量str1的时候,因为此时设定的编码为gbk,驴唇不对马嘴,编码与解码不一致,导致解码错误。
修改如下(左),结果(右)

计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
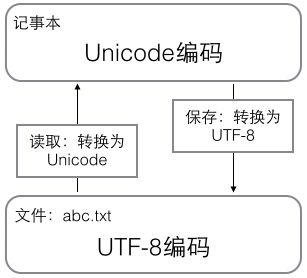
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
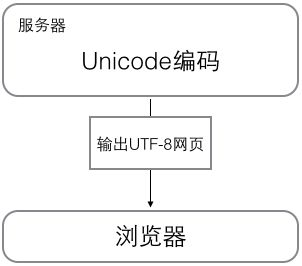
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
如果知道字符的整数编码,还可以用十六进制这么写str:
>>> '\u4e2d\u6587'
'中文'
两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。

在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3, 1)
' 3-01'
>>> '%.2f' % 3.1415926
'3.14'
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'