Spark机器学习:概念和安装
http://blog.csdn.net/pipisorry/article/details/50924395
spark基本概念
Spark一种与 Hadoop 相似的通用的集群计算框架,通过将大量数据集计算任务分配到多台计算机上,在性能和迭代计算上很有看点,提供高效内存计算,现在是Apache孵化的顶级项目。
Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架,而Scala的语言特点也铸就了大部分Spark的成功。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。
虽然 Spark 与 Hadoop 有相似之处,但它提供了具有有用差异的一个新的集群计算框架。首先,Spark 是为集群计算中的特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。为了优化这些类型的工作负载,Spark 引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟。
Spark 还引进了名为 弹性分布式数据集 (RDD) 的抽象。RDD 是分布在一组节点中的只读对象集合。这些集合是弹性的,如果数据集一部分丢失,则可以对它们进行重建。重建部分数据集的过程依赖于容错机制,该机制可以维护 “血统”(即充许基于数据衍生过程重建部分数据集的信息)。RDD 被表示为一个 Scala 对象,并且可以从文件中创建它;一个并行化的切片(遍布于节点之间);另一个 RDD 的转换形式;并且最终会彻底改变现有 RDD 的持久性,比如请求缓存在内存中。
Spark 中的应用程序称为驱动程序,这些驱动程序可实现在单一节点上执行的操作或在一组节点上并行执行的操作。与 Hadoop 类似,Spark 支持单节点集群或多节点集群。对于多节点操作,Spark 依赖于 Mesos 集群管理器。Mesos 为分布式应用程序的资源共享和隔离提供了一个有效平台。该设置充许 Spark 与 Hadoop 共存于节点的一个共享池中。
如果你熟悉Hadoop,那么你知道分布式计算框架要解决两个问题:如何分发数据和如何分发计算。Hadoop使用HDFS来解决分布式数据问题,MapReduce计算范式提供有效的分布式计算。类似的,Spark拥有多种语言的函数式编程API,提供了除map和reduce之外更多的运算符,这些操作是通过一个称作弹性分布式数据集(resilient distributed datasets, RDDs)的分布式数据框架进行的。本质上,RDD是种编程抽象,代表可以跨机器进行分割的只读对象集合。RDD可以从一个继承结构(lineage)重建(因此可以容错),通过并行操作访问,可以读写HDFS或S3这样的分布式存储,更重要的是,可以缓存到worker节点的内存中进行立即重用。由于RDD可以被缓存在内存中,Spark对迭代应用特别有效,因为这些应用中,数据是在整个算法运算过程中都可以被重用。大多数机器学习和最优化算法都是迭代的,使得Spark对数据科学来说是个非常有效的工具。另外,由于Spark非常快,可以通过类似Python REPL的命令行提示符交互式访问。
Spark库本身包含很多应用元素,这些元素可以用到大部分大数据应用中,其中包括对大数据进行类似SQL查询的支持,机器学习和图算法,甚至对实时流数据的支持。
spark核心组件
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。对熟悉Hive和HiveQL的人,Spark可以拿来就用。
Spark Streaming:允许对实时数据流进行处理和控制。很多实时数据库(如Apache Store)可以处理实时数据。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。之前可选的大数据机器学习库Mahout,将会转到Spark,并在未来实现。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
由于这些组件满足了很多大数据需求,也满足了很多数据科学任务的算法和计算上的需要,Spark快速流行起来。不仅如此,Spark也提供了使用Scala、Java和Python编写的API;满足了不同团体的需求,允许更多数据科学家简便地采用Spark作为他们的大数据解决方案。
Spark的执行
本质上,Spark应用作为独立的进程运行,由驱动程序中的SparkContext协调。这个context将会连接到一些集群管理者(如YARN),这些管理者分配系统资源。集群上的每个worker由执行者(executor)管理,执行者反过来由SparkContext管理。执行者管理计算、存储,还有每台机器上的缓存。重点是应用代码由驱动程序发送给执行者,执行者指定context和要运行的任务。执行者与驱动程序通信进行数据分享或者交互。驱动程序是Spark作业的主要参与者,因此需要与集群处于相同的网络。这与Hadoop代码不同,Hadoop中你可以在任意位置提交作业给JobTracker,JobTracker处理集群上的执行。
Spark-0.8源码流程图

spark相关论文
M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica, “Spark: cluster computing with working sets,” in Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, 2010, pp. 10–10.
M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauley, M. J. Franklin, S. Shenker, and I. Stoica, “Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing,” in Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation, 2012, pp. 2–2.
[Spark简介及其在ubuntu下的安装使用]
皮皮blog
linux下spark的安装
安装jdk依赖
[java环境配置:安装jdk]
下载spark相应hadoop2.6版本
选择Spark最新发布版,一个预构建的Hadoop 2.6包,直接下载。
Download Apache Spark™
[spark-1.6.1-bin-hadoop2.6.tgz]第二个下载链接较快
解压到/opt
这样就可以在/opt/spark-1.6.1-bin-hadoop2.6目录下通过$./bin/spark-shell 或者$./bin/pyspark使用spark了。不过可以配置一下更好用:
spark配置
创建指向该Spark版本的符号链接到spark目录。这样你可以简单地下载新/旧版本的Spark,然后修改链接来管理Spark版本,而不用更改路径或环境变量。
pika:~$sudo ln -s /opt/spark-1.6.1-bin-hadoop2.6 /opt/spark
修改BASH配置,将Spark添加到PATH中,设置SPARK_HOME环境变量,这样就可以直接在命令行上执行spark命令了。
Ubuntu上,编辑~/.profile 或 ~/.bash_profile文件 Note: ~/.profile is not read by bash(1), if ~/.bash_profile or ~/.bash_login exists.
pika:~$vi .profile
pika:~$sudo vi /etc/environment #修改这个也可以
将下面的语句加入到PATH中
:$SPARK_HOME/bin
将以下语句添加到文件中PATH的下一行中:
export SPARK_HOME=/opt/spark
将pyspark的python版本指向python3
export PYSPARK_PYTHON=python3
ps: if you want to run in in IPython Notebook, write:
PYSPARK_PYTHON=python3 PYSPARK_DRIVER_PYTHON=ipython3 PYSPARK_DRIVER_PYTHON_OPTS="notebook" ./bin/pyspark #当然这是要安装的
[Apache Spark: How to use pyspark with Python 3]
使修改生效pika:~$. /etc/environment,只是在root用户下当前命令窗口生效,总是生效要重启。
启动spark
$spark-shell #启动scala spark
$pyspark #启动python spark
PS:本博客是根据《spark机器学习》学习后记录的笔记。书代码及勘误[CODE DOWNLOADS & ERRATA],填写好邮箱等就会发送给你了,lz:其实就是这个地址http://www.packtpub.com/code_download/17400,另[《Machine Learning with Spark》书评与作者访谈]。
简略Spark输出
Spark(和PySpark)的执行可以特别详细,很多INFO日志消息都会打印到屏幕。开发过程中,这些非常恼人,因为可能丢失Python栈跟踪或者print的输出。为了减少Spark输出 – 你可以设置$SPARK_HOME/conf下的log4j。首先,拷贝一份$SPARK_HOME/conf/log4j.properties.template文件,去掉“.template”扩展名。
$sudo cp $SPARK_HOME/conf/log4j.properties.template $SPARK_HOME/conf/log4j.properties
编辑新文件,用WARN替换代码中出现的INFO。你的log4j.properties文件类似:
# Set everything to be logged to the console
19 log4j.rootCategory=WARN, console
20 log4j.appender.console=org.apache.log4j.ConsoleAppender
21 log4j.appender.console.target=System.err
22 log4j.appender.console.layout=org.apache.log4j.PatternLayout
23 log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
24
25 # Settings to quiet third party logs that are too verbose
26 log4j.logger.org.spark-project.jetty=WARN
27 log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
28 log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=WARN
29 log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=WARN
30 log4j.logger.org.apache.parquet=ERROR
31 log4j.logger.parquet=ERROR
32
33 # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
34 log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
35 log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
现在运行PySpark,输出消息将会更简略!
皮皮blog
pycharm中使用pyspark
配置python虚拟开发环境
配置python虚拟环境[python虚拟环境配置virtualenv]
在虚拟环境中安装py4j:
pika:/media/pika/files/mine/python_workspace/ubuntu_env$source bin/activate
(ubuntu_env) pika:/media/pika/files/mine/python_workspace/ubuntu_env$pip3 install py4j
Note: 如果在pip3 install前面加上sudo则是在系统中安装py4j,而不是虚拟环境中!
测试安装是否成功:
(ubuntu_env) pika:/media/pika/files/mine/python_workspace/ubuntu_env$python3
Python 3.4.3 (default, Oct 14 2015, 20:28:29)
[GCC 4.8.4] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import py4j
没报错说明成功!
pycharm中配置python开发环境
pycharm设置中设置ubuntu_env为python开发环境。当然不想用virtualenv的可以直接在系统中安装python包,使用系统自带的python解析器

在项目Project的要运行的python代码运行配置中选择“Run” ->“Edit Configurations” ->“Environment variables”“Configurations” ->“Environment variables”增加SPARK_HOME目录与PYTHONPATH目录。
SPARK_HOME:Spark安装目录; PYTHONPATH:Spark安装目录下的Python目录
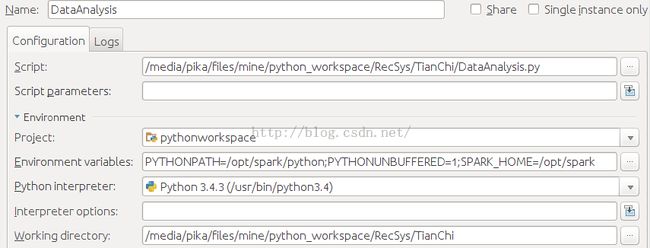
测试一下是否成功,DataAnalysis.py:
from pyspark import SparkContext sc = SparkContext("local[4]", "tianchi data analysis") songs_data = sc.textFile(r"/media/pika/files/machine_learning/RecSys/Tianchi/mars_tianchi_songs.csv") print(songs_data.first())
Note: 也可以使用spark-submit命令来运行py代码: $ spark-submit DataAnalysis.py
输出类似下面内容就成功了(print输出正确就OK了):
[使用PyCharm配置Spark的Python开发环境(基础)]
[importing pyspark in python shell]
from: http://blog.csdn.net/pipisorry/article/details/50924395
ref: 别再比较Hadoop和Spark了,那不是设计人员的初衷