SequenceFile 解决hadoop小文件问题
|
OverviewSequenceFile is a flat file consisting of binary key/value pairs. It is extensively used in MapReduce as input/output formats. It is also worth noting that, internally, the temporary outputs of maps are stored using SequenceFile. The SequenceFile provides a Writer, Reader and Sorter classes for writing, reading and sorting respectively. There are 3 different SequenceFile formats:
The recommended way is to use the SequenceFile.createWriter methods to construct the 'preferred' writer implementation. The SequenceFile.Reader acts as a bridge and can read any of the above SequenceFile formats.
SequenceFile FormatsThis section describes the format for the latest 'version 6' of SequenceFiles. Essentially there are 3 different file formats for SequenceFiles depending on whether compression and block compression are active.
SequenceFile Common Header
All strings are serialized using Text.writeString api.
Uncompressed & RecordCompressed Writer Format
The sync marker permits seeking to a random point in a file and then re-synchronizing input with record boundaries. This is required to be able to efficiently split large files for MapReduce processing.
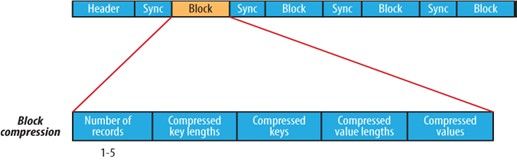
BlockCompressed Writer Format
简介:
SequenceFile 是一个由二进制序列化过的key/value的字节流组成的文本存储文件,它可以在map/reduce过程中的input/output 的format时被使用。在map/reduce过程中,map处理文件的临时输出就是使用SequenceFile处理过的。 SequenceFile分别提供了读、写、排序的操作类。 SequenceFile的操作中有三种处理方式: 1) 不压缩数据直接存储。 //enum.NONE 2) 压缩value值不压缩key值存储的存储方式。//enum.RECORD 3) key/value值都压缩的方式存储。//enum.BLOCK SequenceFile提供了若干Writer的构造静态获取。 //SequenceFile.createWriter(); SequenceFile.Reader使用了桥接模式,可以读取SequenceFile.Writer中的任何方式的压缩数据。 三种不同的压缩方式是共用一个数据头,流方式的读取会先读取头字节去判断是哪种方式的压缩,然后根据压缩方式去解压缩并反序列化字节流数据,得到可识别的数据。 流的存储头字节格式: Header: *字节头”SEQ”, 后跟一个字节表示版本”SEQ4”,”SEQ6”.//这里有点忘了 不记得是怎么处理的了,回头补上做详细解释 *keyClass name *valueClass name *compression boolean型的存储标示压缩值是否转变为keys/values值了 *blockcompression boolean型的存储标示是否全压缩的方式转变为keys/values值了 *compressor 压缩处理的类型,比如我用Gzip压缩的Hadoop提供的是GzipCodec什么的.. *元数据 这个大家可看可不看的 所有的String类型的写操作被封装为Hadoop的IO API,Text类型writeString()搞定。 未压缩的和只压缩values值的方式的字节流头部是类似的: *Header *RecordLength记录长度 *key Length key值长度 *key 值 *是否压缩标志 boolean *values
package com.netease.hadooplucene.lucene.test;
import java.io.File;
import java.io.IOException;
import java.util.*;
import java.lang.String;
import java.lang.Object;
import java.net.URI;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.fs.*;
import com.netease.hadooplucene.lucene.util.HadoopService;
public class SequenceFileTest {
public static void writeSequceFile(String uri)throws IOException{
FileSystem fs = HadoopService.getInstance().getHDFSClient();
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, fs.getConf(), path, key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
String tt = String.valueOf(100 - i);
key.set(i);
value.set(tt);
System.out.printf("[%s]/t%s/t%s/n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
// public static File getFile(String uri){
// FileSystem fs = HadoopService.getInstance().getHDFSClient();
// Path path = new Path(uri);
// SequenceFile.Reader reader=new SequenceFile.Reader(fs, path, fs.getConf());
// reader.
// reader.
// }
public static void main(String[] args) throws IOException {
String uri = args[0];
// Configuration conf = new Configuration();
// FileSystem fs = FileSystem.get(URI.create(uri), conf);
}
}
前天项目组里遇到由于sequenceFile 的压缩参数设置为record 而造成存储空间的紧张,后来设置为block 压缩方式的压缩方式,存储空间占用率为record 方式的1/5 。问题虽解决了,但是还不是很清楚这两种方式是如何工作以及他们的区别是啥。昨天和今天利用空闲时间,细细的看了一遍sequenceFile 这个类和一些相关类的源码。 sequenceFile 文件存储有三种方式:可以通过在程序调用 enum CompressionType { NONE , RECORD , BLOCK } 指定,或通过配置文件io.seqfile.compression.type 指定,这三种存储方式如下图:
对于Record 压缩这种存储方式,RecordLen 表示的是key 和value 的占用的byte 之和,Record 压缩方式中 key 是不压缩 ,value 是压缩后的值,在record 和非压缩这两种方式,都会隔几条记录插入一个特殊的标号来作为一个同步点Sync ,作用是当指定读取的位置不是记录首部的时候,会读取一个同步点的记录,不至于读取数据的reader “迷失”。 每两千个byte 就插入一个同步点,这个同步点占16 byte ,包括同步点标示符:4byte ,一个同步点的开销是20byte 。 对于block 这种压缩方式, key 和value 都是压缩的 ,通过设置io.seqfile.compress.blocksize 这个参数决定每一个记录块压缩的数据量,默认大小是1000000 byte ,这个值具体指的是key 和value 缓存所占的空间,每要往文件写一条key/value 时,都是将key 和value 的长度以及key 和value 的值缓存在keyLenBuffer keyBuffer valLenBuffer valBuffer 这四个DataOutputStream 中,当keyBuffer.getLength() + valBuffer.getLength() 大于或等于io.seqfile.compress.blocksize 时,将这些数据当做一个block 写入sequence 文件,如上图所示 每个block 之间都会插入一个同步点。 |