MongoDB 集群介绍
Master-Slaver(主从)
这个是最简答的集群搭建,官方不推荐这种方式,官方建议采用 replica set。主从数据库需要两个 MongoDB 文档数据库即可,一个是以主模式启动,另一个属于从模式启动。主服务器进程将创建一个 local.oplog,将数据同步到 Slave 服务器中(并不一定非得两台独立的服务器,可使用--dbpath参数指定数据库目录)。一个从节点可以有多个主节点,这种情况下,local.sources中会有多条配置信息。一台服务器可以同时即为主也为从。如果一台从节点与主节点不同步,比如从节点的数据更新远远跟不上主节点或者从节点中断之后重启但主节点中相关的数据更新日志却不可用了。这种情况下,复制操作将会终止,需要管理者的介入,看是否默认需要重启复制操作。管理者可以使用{resync:1}命令重启复制操作,可选命令行参数--autoresync可使从节点在不同步情况发生10秒钟之后,自动重启复制操作。如果指定了--autoresync参数,从节点在10分钟以内自动重新同步数据的操作只会执行一次。--oplogSize命令行参数(与--master一同使用)配置用于存储给从节点可用的更新信息占用的磁盘空间(M为单位),如果不指定这个参数,默认大小为当前可用磁盘空间的5%(64位机器最小值为1G,32位机器为50M)。
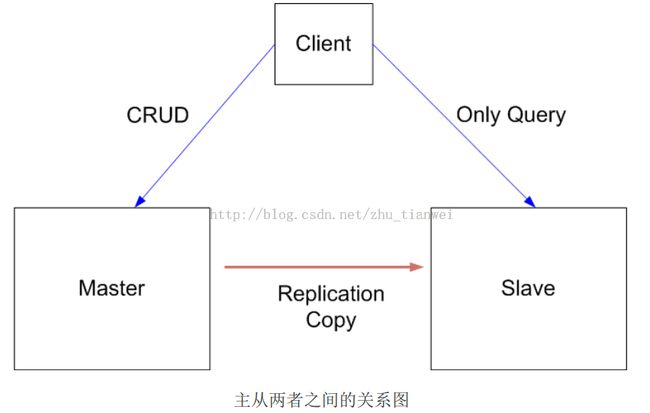
Replica Set(副本集)
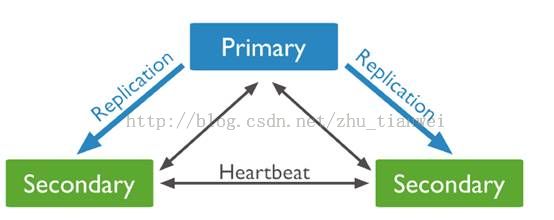
复制集是一组mongod实例维护了同一份数据,primary接受所有的写入。Secondary从primary上获取这些写入然后应用到本地。Primary接受所有client的写入操作,并且一个复制集只能有一个primary,这样才能提供严格的一致性。Primary把所有的写入操作都放在一个叫oplog的地方。Secondary复制primary的oplog然后应用到自己的数据集上,secondary就是primary的一个影子,当primary不可用时,复制集会选一个secondary变成primary。客户端默认从primary读取数据,也可以通过制定读偏好,从secondary上读取。当然你可以增加一个仲裁服务,仲裁没有数据,但是可以投票选出primary,如果你的复制集的成员是偶数的,可以增加一个仲裁,仲裁对硬件基本没什么要求。Secondary从primary上应用操作是异步的,在primary之后应用到secondary,虽然有些成员还是没有,但是复制集还可以继续运行,唯一的问题是secondary不能反映当前的数据状态。当primary不能和其他成员交互超过10s,复制集会试图选择一个成员变成primary。复制集是一组mongodb提供的冗余和高可用,成员如下:
1.Primary成员
Primary是唯一一个可以接受写入的成员,写入到primary之后然后记录到primary的oplog,然后secondary复制这些日志应用这些操作。所有成员都可以接受读操作,默认应用程序会直接从primary上读取。复制集只能有一个primary,也必须要有一个,当当前的primary不可用,可以换一个。
2.Secondary成员
Secondary维护了primary的数据备份,然后通过应用primary的oplog来异步的更新数据。一个复制集可以有多个secondary。
客户端不能写入到secondary只能从secondary上读取。当primary不可用,复制集会从secondary上选一个。
还可以配置secondary:
1.为了防止secondary变成primary,可以把优先级设为0
2.为了防止secondary读取可以把secondary设置为隐藏
3.用来维护一个历史的快照,用来恢复认为的错误。

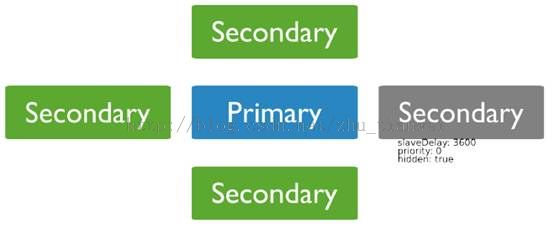
1)优先级设置为0成员
优先级为0的secondary不能变成primary。
把优先级为0的作为准备:因为当数据大的时候新增一个节点有困难,准备节点可以很快的去替换现在不可用的节点。一般是不太用准备节点,但是在不同硬件设备,不同物理环境状况下,0优先级可以保证可以选到一个合格的primary。
0优先级和故障转移:考虑到潜在的故障,把优先级设置为0,并且保证你的主要数据中心包含了所有的合格可以变成primary的成员和可以投票的成员。
2)隐藏成员
隐藏成员维护了primary的数据备份,但是对应用程序不可见。隐藏成员用来其他使用,隐藏成员难道优先级都为0,不能变成primary。使用db.isMaster()不显示隐藏成员,但是隐藏成员可以投票。
客户端的读取不能从隐藏成员上读取,隐藏成员一般用来做报表或者用来备份。如果用来备份,就要让隐藏成员尽量接近primary。
为了避免隐藏成员关闭mongod,可以使用db.fsyncLock()来刷新所有的写入,并且在备份期间锁定mongod。
3)延迟成员
延迟成员,是primary数据的一个延迟。如果出现人为的错误,可以使用延迟成员来恢复。
要求:
1.优先级必须为0,2.不许是隐藏的,3.可以投票。
延迟成员是延迟应用oplog,所以当选择延迟时间的时候要考虑以下2点:
1.必须大于等于你的维护窗口
2.必须小于oplog的能力。
3.仲裁成员
仲裁不包含数据也不能成为primary,但是复制集可以增加一个仲裁来一起投票primary。仲裁可以让复制集成员变成奇数,但是不用复制数据。
当成员是偶数的时候再加仲裁。如果你把仲裁加入到一个奇数成员个数的集中,复制集可能会无法产生primary。

4.安全性
当启用auth的时候,仲裁会和其他成员交换凭据,仲裁使用keyfiles来验证到复制集。
交互:只有仲裁要投票,心跳,配置的时候才会和其他成员交互。当然也可以运行在可信任网络下。
Sharding(切片)
当数据库数据增大,应用程序高吞吐量会对单服务的能力进行挑战。查询过大cpu使用过大,数据过大要要求存储能力,working set 过大要求RAM和IO能力。
为了解决这个问题,有2个基本的方案:水平扩展,垂直扩展。
水平扩展:添加更多的cpu,存储资源来这更加处理能力。大cpu大内存的设备价格会远远大于小设备。
Sharding:是一种水平扩展,把数据分片到各个设备上。每个分片都是一个独立的数据库。
sharding处理大数据,大吞吐量的好处:
1.减少了在每个shard上的操作
2.减少了每个shard上的数据保存量。
mongodb分发数据或者分配是在collection级别的,同归shard key对collection进行分片。Shard Keys必须每个文档都有,并且要不是索引的字段,要不是组合索引的字段。mongodb把shard key划分为chunks,然后发布这些chunk到各个shard。可以使用range分区也可以是hash分区。
shard集群由以下几个组件:shard,query routers和config server
Shard Server:用来存储数据。提供高可用和数据一致性,在生产环境下一个shard是一个复制集
Query Routers:或者mongos实例,是客户端的接口然后在合适的shard中型操作然后返回数据。对于shard集群可以包含多余一个router来分流客户端请求。一个客户端发送请求到一个router,大多数shard集群由很多query router。
Config Server:保存集群元数据,query router根据config server上的元数据来决定路由到哪个shard。
以上三种集群搭建方式首选Replica Set,只有真的是大数据,Sharding才能显现威力,毕竟备节点同步数据是需要时间的。Sharding可以将多片数据集中到路由节点上进行一些对比,然后将数据返回给客户端,但是效率还是比较低的说。
参考文章:
http://blog.csdn.net/luonanqin/article/details/8497860
http://www.cnblogs.com/Amaranthus/p/3616951.html
http://www.searchdatabase.com.cn/showcontent_48979.htm
http://www.cnblogs.com/nbpowerboy/p/4325692.html