Hadoop2.6.0版本MapReudce示例之WordCount
一、准备测试数据
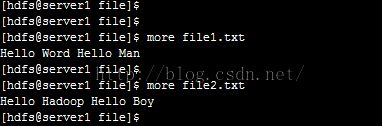
1、在本地Linux系统/var/lib/hadoop-hdfs/file/路径下准备两个文件file1.txt和file2.txt,文件列表及各自内容如下图所示:
2、在hdfs中,准备/input路径,并上传两个文件file1.txt和file2.txt,如下图所示:
![]()
二、编写代码,封装Jar包并上传至linux
将代码封装成TestMapReduce.jar,并上传至linux的/usr/local路径下,如下图所示:
![]()
三、运行命令
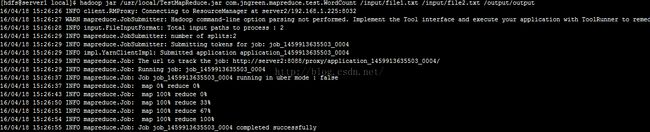
执行命令如下:hadoop jar /usr/local/TestMapReduce.jar com.jngreen.mapreduce.test.WordCount /input/file1.txt /input/file2.txt /output/output
命令执行过程截图如下:
四、查看运行结果
查看hdfs输出路径/output下的结果,如下图所示:
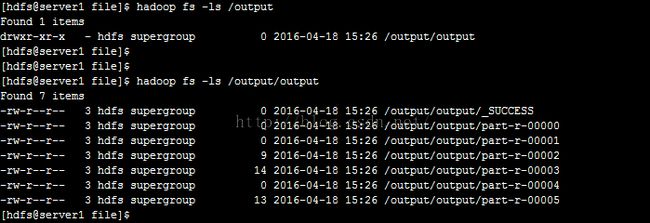
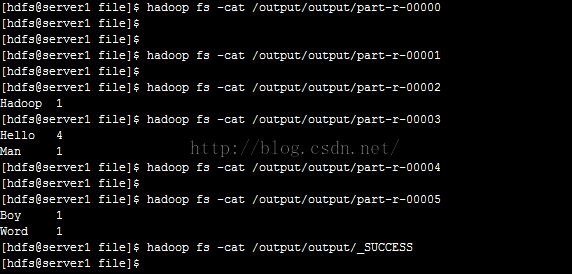
运行结果为Hello 4、Hadoop 1、Man 1、Boy 1、Word 1,完全正确!
五、WordCount展示
源码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
// TokenizerMapper作为Map阶段,需要继承Mapper,并重写map()函数
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// 用StringTokenizer作为分词器,对value进行分词
StringTokenizer itr = new StringTokenizer(value.toString());
// 遍历分词后结果
while (itr.hasMoreTokens()) {
// 将String设置入Text类型word
word.set(itr.nextToken());
// 将(word,1),即(Text,IntWritable)写入上下文context,供后续Reduce阶段使用
context.write(word, one);
}
}
}
// IntSumReducer作为Reduce阶段,需要继承Reducer,并重写reduce()函数
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
// 遍历map阶段输出结果中的values中每个val,累加至sum
for (IntWritable val : values) {
sum += val.get();
}
// 将sum设置入IntWritable类型result
result.set(sum);
// 通过上下文context的write()方法,输出结果(key, result),即(Text,IntWritable)
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// 加载hadoop配置
Configuration conf = new Configuration();
// 校验命令行输入参数
if (args.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
// 构造一个Job实例job,并命名为"word count"
Job job = new Job(conf, "word count");
// 设置jar
job.setJarByClass(WordCount.class);
// 设置Mapper
job.setMapperClass(TokenizerMapper.class);
// 设置Combiner
job.setCombinerClass(IntSumReducer.class);
// 设置Reducer
job.setReducerClass(IntSumReducer.class);
// 设置OutputKey
job.setOutputKeyClass(Text.class);
// 设置OutputValue
job.setOutputValueClass(IntWritable.class);
// 添加输入路径
for (int i = 0; i < args.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(args[i]));
}
// 添加输出路径
FileOutputFormat.setOutputPath(job,
new Path(args[args.length - 1]));
// 等待作业job运行完成并退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}