使用WebMagic爬虫框架及javaEE SSH框架将数据保存到数据库
由于近期做毕设,需要从网站上爬取教学资源,下面实现一个简单的爬虫,并将爬取的数据保存到数据库中。
一:有关爬虫框架的选取,我使用的是WebMagic爬虫框架,中文文档:http://webmagic.io/docs/zh/
它是一个开源项目,github地址:https://github.com/code4craft/webmagic,之前想用python写爬虫的,也写了一点,但还要学习操作数据库的,想想还是用java爬虫框架吧,做完毕设再好好学学python。
二:首先看一下要爬取的内容,专业名字、课程数量、专业类别、url链接,然后将其存入数据库
三:定义一个实体类,属性对应,由于使用的SSH框架,之后我们将爬到的数据给这个对象,然后保存对象即可。

四:爬虫具体代码:
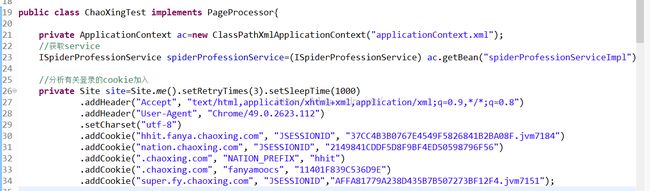
(1)实现PageProcessor接口,并实现其中的方法,下面会使用到service,这里得到Spring容器对象,然后得到需要的service
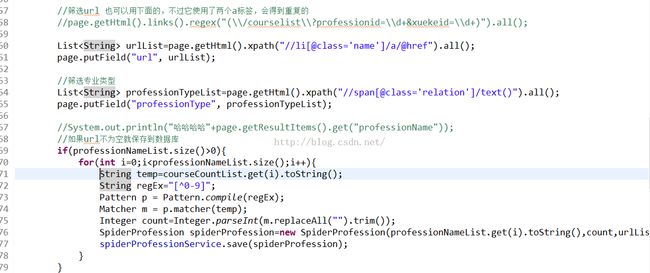
(2)然后重写process方法,提取需要的内容,这里主要使用了xpath,还有很多方法, 具体看其中文文档。
之前我也用了正则表达式,有个网站可以进行正则表达式的转换,还不错:http://www.txt2re.com/

(3)然后封装成对象,保存到数据库即可。
其中抽取到的课程数量是在一段文字中,使用正则匹配得到其中的数字。
五:一些问题:
(1)由于我这个爬虫的抓取有分页,而且它的分页通过js跳转的,抽取出来感觉有点麻烦,我想直接得到所有的信息,发现可以通过输入url地址请求得到所有的信息(这是网站的一个小问题,它没有设置每页数据记录条数的范围),但是需要登录才可以进行url地址的访问,就要使用cookie模拟登录。
(2)下面分析有关登录信息的cookie,我使用的是chrome,点击如图位置,会看到此网站的cookie,(如果已经访问了一段时间了,可以清除所有cookie然后重新登录再访问,否则可能会有很多的cookie,分析起来不方便),由于只有5个cookie,直接加上就可以访问了,看步骤四(1)中site的设置。

六:测试结果
数据保存成功。
七:总结
这只是一个简单的爬虫,后面还要接着爬取数据,感觉还是可以学到很多东西的。