Hadoop学习笔记(4)-Eclipse下搭建Hadoop2.6.4开发环境
0.前言
本文参考博客:http://www.51itong.net/eclipse-hadoop2-7-0-12448.html
搭建开发环境前保障已经搭建好hadoop的伪分布式。可参考上个博客:
http://blog.csdn.net/xummgg/article/details/51173072
1.下载安装eclipse
下载网址:http://www.eclipse.org/downloads/

因为运行在ubuntu下,所以下载linux 64为的版本(支持javaEE),下载后默认放在当前用户的Downloads。
解压,命令如下:

解压后可以在/usr/local下看到:
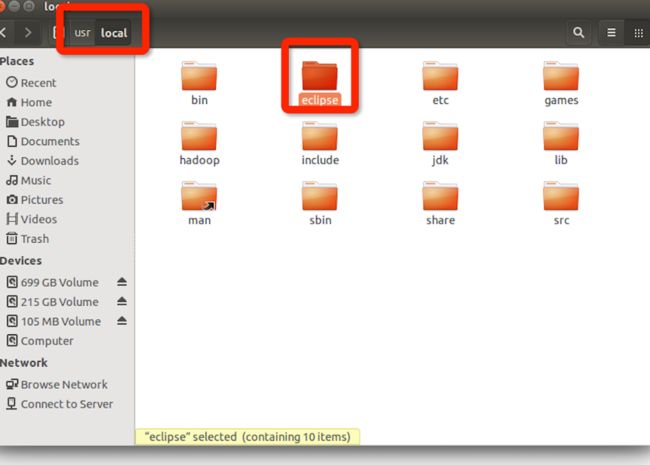
因为,要加入新jar包进入eclipse,所以把ecplise文件夹权限,设置高权限。
2.下载hadoop插件
2.6.4插件hadoop-eclipse-plugin-2.6.4.jar 下载地址:
http://download.csdn.net/download/tondayong1981/9437360
下载完成后,把插件放到eclipse/plugins目录下
用sudo要输入用户密码。
3.设置eclipse
运行eclipse
打开window->preferences
可以看到多了个Hadoop Map/Reduce,设置本机的hadoop目录,我的目录时/usr/local/hadoop/hadoop-2.6.4/ ,如下图所示:
4.配置Map/Reduce Locations
注意:配置前先在后台运行起hadoop,即开启hadoop伪分布式的dfs和yarn,参考上一个博客。
Eclipse中打开Windows—Open Perspective—Other

选择Map/Reduce,点击OK
在右下方看到如下图所示
点击Map/Reduce Location选项卡,点击右边蓝色小象图标,打开Hadoop Location配置窗口。
输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。如下图:
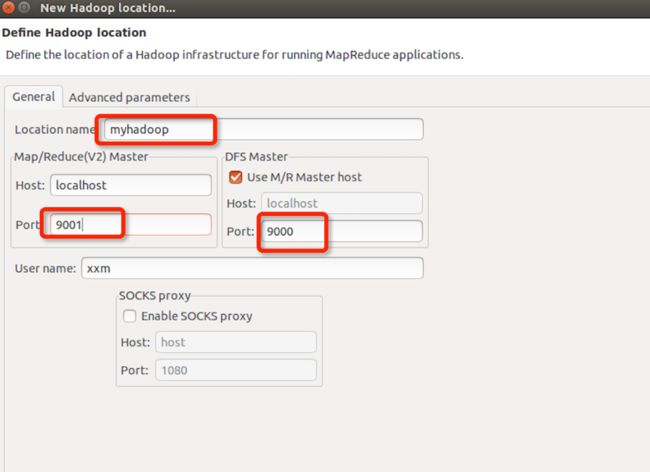
点击”Finish”按钮,关闭窗口。
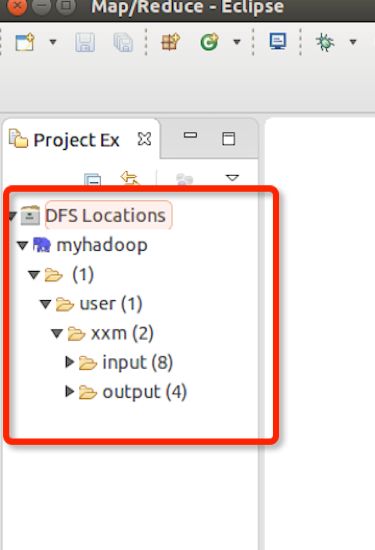
点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功。这样eclipse就连接上了分布式文件系统,可以在eclipse里做查看,方便编程。
5.新建WordCount项目
点击File—>Project:
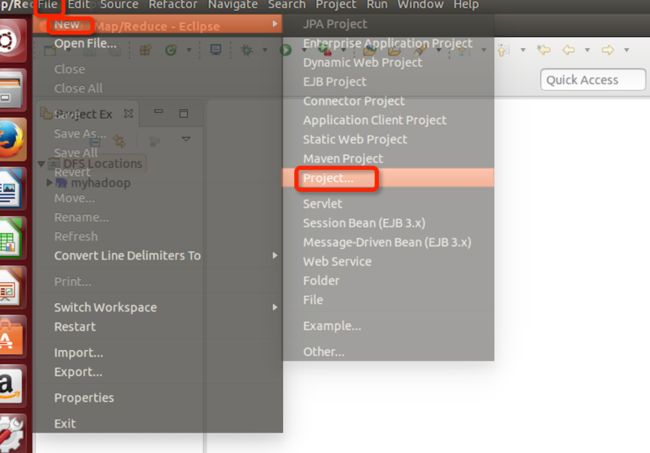
选择Map/Reduce Project,点next进入下一步:
输入项目名称WordCount,点finish完成:
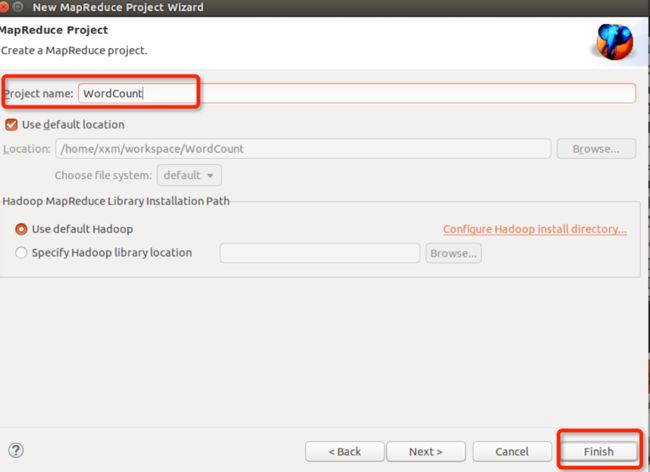
在WordCount项目里右键src新建class,包名com.xxm(请自行命明),类名为WordCount:
代码如下:
package com.xxm;//改为自己的包明
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
/** * * 描述:WordCount explains by xxm * @author xxm */
public class WordCount
{
/** * MapReduceBase类:实现了Mapper和Reducer接口的基类(其中的方法只是实现接口,而未作任何事情) * Mapper接口: * WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。 * Reporter 则可用于报告整个应用的运行进度,本例中未使用。 * */
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable>
{
/** * LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口, * 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为long,int,String 的替代品。 */
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/** * Mapper接口中的map方法: * void map(K1 key, V1 value, OutputCollector<K2,V2> output, Reporter reporter) * 映射一个单个的输入k/v对到一个中间的k/v对 * 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。 * OutputCollector接口:收集Mapper和Reducer输出的<k,v>对。 * OutputCollector接口的collect(k, v)方法:增加一个(k,v)对到output */
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens())
{
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable>
{
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
{
int sum = 0;
while (values.hasNext())
{
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception
{
/** * JobConf:map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作 * 构造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等 */
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount"); //设置一个用户定义的job名称
conf.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
conf.setOutputValueClass(IntWritable.class); //为job输出设置value类
conf.setMapperClass(Map.class); //为job设置Mapper类
conf.setCombinerClass(Reduce.class); //为job设置Combiner类
conf.setReducerClass(Reduce.class); //为job设置Reduce类
conf.setInputFormat(TextInputFormat.class); //为map-reduce任务设置InputFormat实现类
conf.setOutputFormat(TextOutputFormat.class); //为map-reduce任务设置OutputFormat实现类
/** * InputFormat描述map-reduce中对job的输入定义 * setInputPaths():为map-reduce job设置路径数组作为输入列表 * setInputPath():为map-reduce job设置路径数组作为输出列表 */
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf); //运行一个job
}
}
6.运行
运行前保证分布式文件系统里的input目录下有文件,如果是HDFS刚格式化过,也请参考《搭建Hadoop伪分布式》教程,创建和上传input文件以及里面的内容。
在WordCount的代码区域,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹地址参数:
hdfs://localhost:9000/user/xxm/input hdfs://localhost:9000/user/xxm/output/wordcount3
如下图所示:
点击Run。
结果可以重连接myhadoop后进入output双击查看。也可以用HDFS命令get下来看。重连接myhadoop方法:在项目管理窗口,右键蓝色小象,选reconnect。
到此hadoop的eclipse开发环境搭建完成。
7.关联hadoop源码
还是在hadoop的下载网站下载源码:
http://hadoop.apache.org/releases.html
下载后解压到/usr/hadoop文件夹里:
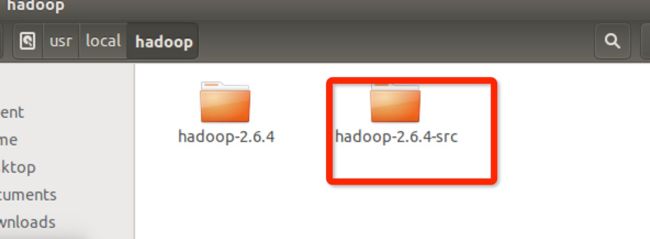
如下图所示,选择了一个hadoop的InWritable函数,右击查看源程序:
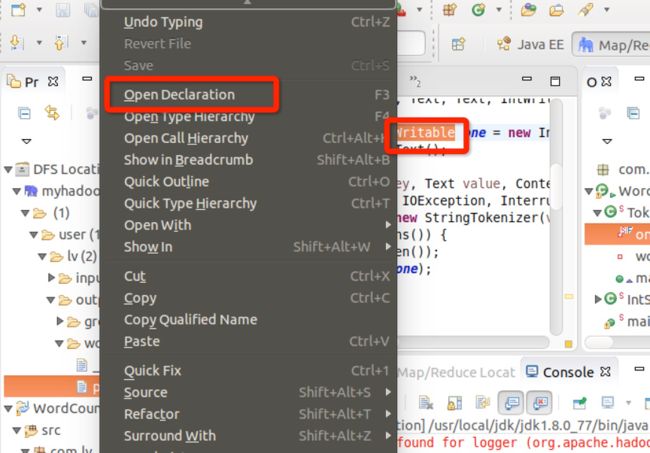
结果源程序不能找到,所以要做源程序的关联。点击Attach Source:
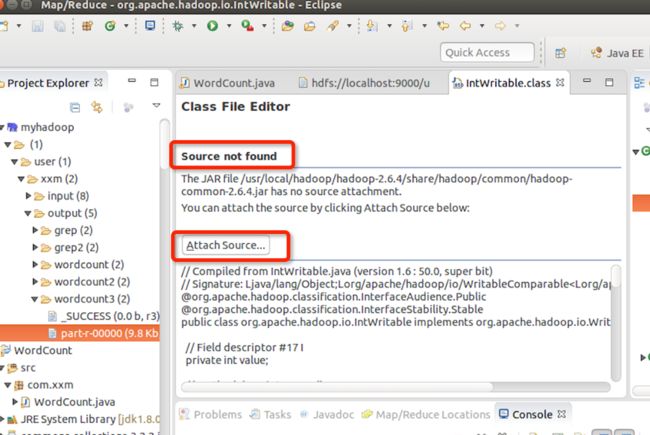
将hadoop-2.6.4-src源码关联,点击ok:
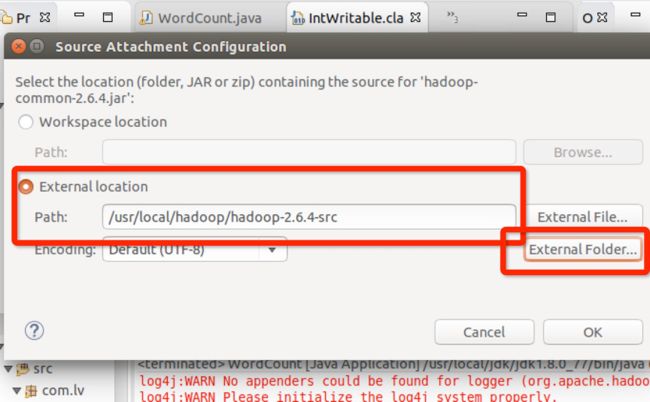
跳转后可以看到InWritable函数已经可以看到源码了:

到此源码关联成功。
XianMing