TransR/CTransR论文:学习实体和关系嵌入的知识图谱补全
摘要:
知识图谱补全以执行实体间的链接预测为目标。本文,我们考虑知识图谱嵌入方法。近年来,一些模型像TransE和TransH通过把关系作为从头实体到尾实体的翻译来建立实体和关系嵌入。我们注意到这些模型仅仅简单地假设实体和关处于相同的语义空间。事实上,一个实体是多种属性的综合体,不同关系关注实体的不同属性,仅仅在同一个空间下对它们进行建模是不够的。本文,我们提出了TransR,分别在实体空间和关系空间构建实体和关系嵌入。然后,我们学习嵌入,首先将实体投影到对应的关系空间中,然后在建立从头实体到尾实体的翻译关系。在实验设计方面,我们通过连接预测,元组分类和关系事实抽取来评估我们的模型。实验结果表明与目前最新的进展包括TransE和TransH相比性能有显著的提高。
简介
知识图谱对实体和它们丰富的关系的结构化信息编码。虽然一个典型的知识图谱可能得到数百万的实体和数以亿计的关系事实,但离补全还很远。知识图谱补全旨在通过现有知识图谱来预测实体之间的关系。知识图谱补全能够找到新的关系事实,这是对从纯文本进行关系抽取的重要补充。
在社交网络分析上,知识图谱补全和链接预测很相似,但是由于以下原因知识图谱补有更多的挑战:(1)知识图谱中的实体具有不同的类型和属性;(2)知识图谱中的关系具有不同的类型。对于知识图谱补全,我们不仅要判断两个实体之间是否有关系,而且还要预测关系的具体类型。
由于这个原因,传统的链接预测的方法并不能胜任知识图谱补全。近年来,一种很有前景的方法被应用到知识图谱补全,它将知识图谱嵌入到一个连续的向量空间并且保留一定的图中的信息。
在这些方法中,TransE(Bordes et al.2013)和TransH(Wang et al.2014)方法既简单又高效,达到了很好的预测性能。TransE是从(Mikolov et al.2013b)中受到启发,学习实体和关系的向量嵌入。这些向量嵌入被设置在Rk空间中并且用相同的粗体字符表示。TransE的基本思想是,实体之间的关系与实体之间的嵌入的翻译相对应,也就是当有(h,r,t)时h+r≈t。当对1-N,N-1和N-N关系建模时TransE存在很多问题,因此提出了TransH,当涉及不同类型的关系时,TransH使得一个实体具有不同的表示。
TransE和TransH都假设实体和关系嵌入在相同的空间Rk中。然而,一个实体是多种属性的综合体,不同关系关注实体的不同属性。直觉上一些相似的实体在实体空间中应该彼此靠近,但是同样地,在一些特定的不同的方面在对应的关系空间中应该彼此远离。为了解决这个问题,我们提出了一种新的方法,将实体和关系投影到不同的空间中,也就是实体空间和多元关系空间(也即是特定关系的实体空间),在对应的关系空间上实现翻译。因此命名为TransR。
TransR的基本思想如图1所示。对于每个元组(h,r,t),首先将实体空间中的实体通过Mr向关系r投影得到hr和tr,然后使hr+r≈tr。特定的关系投影(彩色的圆圈表示)能够使得头/尾实体在这个关系下真实的靠近彼此,使得不具有此关系(彩色的三角形表示)的实体彼此远离。
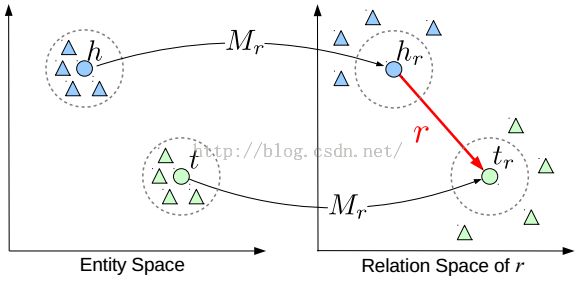
图1:TransR的简单图解
此外,在一个特定的关系下,头-尾实体对通常展示出不同的模型。仅仅通过单个的关系向量还不足以建立实现从头实体到尾实体的所有翻译。例如,具有关系“location location contains”头-尾实体有很多模式,如country-city,country-university,continent-country等等。沿着分段线性回归(Ritzema and others 1994)的思想,通过对不同的头-尾实体对聚类分组和学习每组的关系向量,我们进一步提出了基于聚类的TransR(CTransR)。
我们通过WordNet和Freebase上的链接预测,元组分类和关系事实抽取来评估我们的模型。实验结果表明与最先进的模型相比,我们的模型取得了显著的提高。