Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.2
Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.2
http://blog.csdn.net/sunbow0
第二章Deep Belief Network (深度信念网络)
2基础及源码解析
2.1 Deep Belief Network深度信念网络基础知识
1)综合基础知识参照:
http://tieba.baidu.com/p/2895759455
http://wenku.baidu.com/link?url=E8eett6R-mpVL-5AtO1yRNZR4DdEhW7YkQhDKY2CoYCiCQQYqdmWgrHQed2rsJZ8H2rwobpTgyjuXhdakD5QRv0OBWCUB8B2UA2iSNTcGeO
2)原著资料参照:
《Learning Deep Architectures for AI》
http://wenku.baidu.com/link?url=suD736_WyPyNRj_CEcdo11mKBNMBoq73-u9IxJkbksOtNXdsfMnxOCN2TUz-zVuW80iyb72dyah_GI6qAaPKg42J2sQWLmHeqv4CrU1aqTq
《A Practical Guide to Training Restricted Boltzmann Machines》
http://wenku.baidu.com/link?url=d4xrQntJn86xyMpbJA6dHEWs68_y3m9m-yola8r79MvJDtvjw1VqeHr_yU8Hs4NeRmJmcDQt_m9RY4AnT4Y2fIoIgdDMSEq_h0n_6oNAB4e
2.2 Deep Learning DBN源码解析
2.2.1 DBN代码结构
DBN源码主要包括:DBN,DBNModel两个类,源码结构如下:
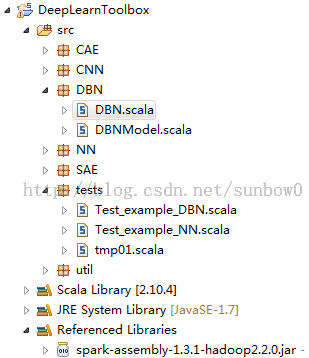
DBN结构:
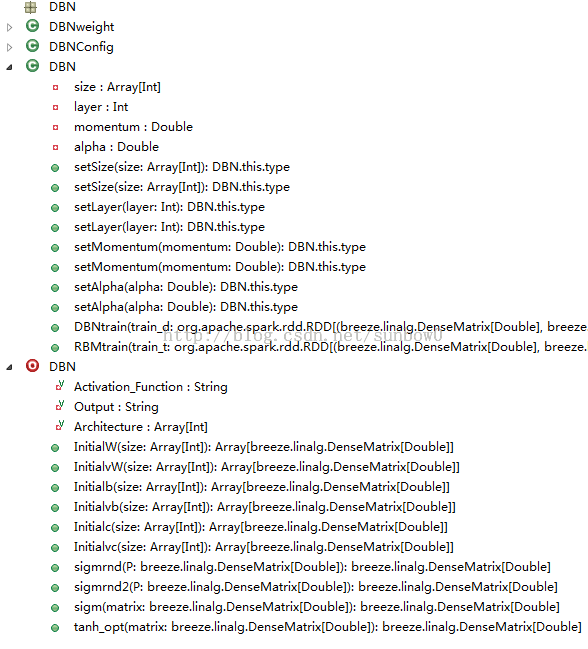
DBNModel结构:

2.2.2 DBN训练过程
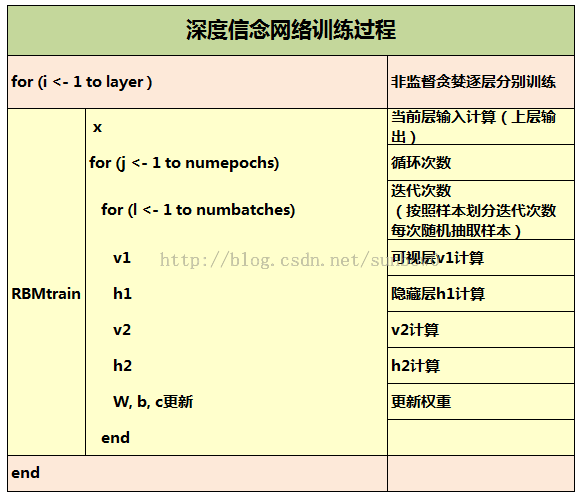
2.2.3 DBN解析
(1) DBNweight
/**
* W:权重
* b:偏置
* c:偏置
*/
caseclass DBNweight(
W: BDM[Double],
vW: BDM[Double],
b: BDM[Double],
vb: BDM[Double],
c: BDM[Double],
vc: BDM[Double])extendsSerializable
DBNweight:自定义数据类型,存储权重。
(2) DBNConfig
/**
*配置参数
*/
caseclassDBNConfig(
size: Array[Int],
layer: Int,
momentum: Double,
alpha: Double)extends Serializable
DBNConfig:定义参数配置,存储配置信息。参数说明:
size:神经网络结构
layer:神经网络层数
momentum: Momentum因子
alpha:学习迭代因子
(3) InitialWeight
初始化权重
/**
* 初始化权重
* 初始化为0
*/
def InitialW(size: Array[Int]): Array[BDM[Double]] = {
// 初始化权重参数
// weights and weight momentum
// dbn.rbm{u}.W = zeros(dbn.sizes(u + 1), dbn.sizes(u));
valn = size.length
valrbm_W = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](size(i), size(i - 1))
rbm_W += d1
}
rbm_W.toArray
}
(4) InitialWeightV
初始化权重vW
/**
* 初始化权重vW
* 初始化为0
*/
def InitialvW(size: Array[Int]): Array[BDM[Double]] = {
// 初始化权重参数
// weights and weight momentum
// dbn.rbm{u}.vW = zeros(dbn.sizes(u + 1), dbn.sizes(u));
valn = size.length
valrbm_vW = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](size(i), size(i - 1))
rbm_vW += d1
}
rbm_vW.toArray
}
(5) Initialb
初始化偏置向量
/**
* 初始化偏置向量b
* 初始化为0
*/
def Initialb(size: Array[Int]): Array[BDM[Double]] = {
// 初始化偏置向量b
// weights and weight momentum
// dbn.rbm{u}.b = zeros(dbn.sizes(u), 1);
valn = size.length
valrbm_b = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](size(i -1),1)
rbm_b += d1
}
rbm_b.toArray
}
(6) Initialvb
初始化偏置向量
/**
* 初始化偏置向量vb
* 初始化为0
*/
def Initialvb(size: Array[Int]): Array[BDM[Double]] = {
// 初始化偏置向量b
// weights and weight momentum
// dbn.rbm{u}.vb = zeros(dbn.sizes(u), 1);
valn = size.length
valrbm_vb = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](size(i -1),1)
rbm_vb += d1
}
rbm_vb.toArray
}
(7) Initialc
初始化偏置向量
/**
* 初始化偏置向量c
* 初始化为0
*/
def Initialc(size: Array[Int]): Array[BDM[Double]] = {
// 初始化偏置向量c
// weights and weight momentum
// dbn.rbm{u}.c = zeros(dbn.sizes(u + 1), 1);
valn = size.length
valrbm_c = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](size(i),1)
rbm_c += d1
}
rbm_c.toArray
}
(8) Initialvc
初始化偏置向量
/**
* 初始化偏置向量vc
* 初始化为0
*/
def Initialvc(size: Array[Int]): Array[BDM[Double]] = {
// 初始化偏置向量c
// weights and weight momentum
// dbn.rbm{u}.vc = zeros(dbn.sizes(u + 1), 1);
valn = size.length
valrbm_vc = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](size(i),1)
rbm_vc += d1
}
rbm_vc.toArray
}
(8) sigmrnd
Gibbs采样
/**
* Gibbs采样
* X = double(1./(1+exp(-P)) > rand(size(P)));
*/
def sigmrnd(P: BDM[Double]): BDM[Double] = {
vals1 =1.0 / (Bexp(P * (-1.0)) +1.0)
valr1 = BDM.rand[Double](s1.rows,s1.cols)
vala1 =s1 :>r1
vala2 =a1.data.map { f =>if (f ==true)1.0else0.0 }
vala3 =new BDM(s1.rows,s1.cols,a2)
a3
}
/**
* Gibbs采样
* X = double(1./(1+exp(-P)))+1*randn(size(P));
*/
def sigmrnd2(P: BDM[Double]): BDM[Double] = {
vals1 =1.0 / (Bexp(P * (-1.0)) +1.0)
valr1 = BDM.rand[Double](s1.rows,s1.cols)
vala3 =s1 + (r1 *1.0)
a3
}
(9) DBNtrain
对神经网络每一层进行训练。
/**
* 深度信念网络(Deep Belief Network)
* 运行训练DBNtrain
*/
def DBNtrain(train_d: RDD[(BDM[Double], BDM[Double])], opts: Array[Double]): DBNModel = {
// 参数配置广播配置
valsc = train_d.sparkContext
valdbnconfig = DBNConfig(size,layer,momentum, alpha)
// 初始化权重
vardbn_W = DBN.InitialW(size)
vardbn_vW = DBN.InitialvW(size)
vardbn_b = DBN.Initialb(size)
vardbn_vb = DBN.Initialvb(size)
vardbn_c = DBN.Initialc(size)
vardbn_vc = DBN.Initialvc(size)
// 训练第1层
printf("Training Level: %d.\n",1)
valweight0 =new DBNweight(dbn_W(0),dbn_vW(0),dbn_b(0),dbn_vb(0),dbn_c(0),dbn_vc(0))
valweight1 = RBMtrain(train_d, opts,dbnconfig,weight0)
dbn_W(0) =weight1.W
dbn_vW(0) =weight1.vW
dbn_b(0) =weight1.b
dbn_vb(0) =weight1.vb
dbn_c(0) =weight1.c
dbn_vc(0) =weight1.vc
// 训练第2层至 n层
for (i <-2 todbnconfig.layer -1) {
// 前向计算x
// x = sigm(repmat(rbm.c', size(x, 1), 1) + x * rbm.W');
printf("Training Level: %d.\n",i)
valtmp_bc_w =sc.broadcast(dbn_W(i -2))
valtmp_bc_c =sc.broadcast(dbn_c(i -2))
valtrain_d2 = train_d.map { f =>
vallable = f._1
valx = f._2
valx2 = DBN.sigm(x *tmp_bc_w.value.t +tmp_bc_c.value.t)
(lable, x2)
}
// 训练第i层
valweighti =new DBNweight(dbn_W(i -1), dbn_vW(i -1),dbn_b(i -1),dbn_vb(i -1),dbn_c(i -1),dbn_vc(i -1))
valweight2 = RBMtrain(train_d2, opts,dbnconfig,weighti)
dbn_W(i -1) =weight2.W
dbn_vW(i -1) =weight2.vW
dbn_b(i -1) =weight2.b
dbn_vb(i -1) =weight2.vb
dbn_c(i -1) =weight2.c
dbn_vc(i -1) =weight2.vc
new DBNModel(dbnconfig,dbn_W,dbn_b, dbn_c)
}
(10) RBMtrain
神经网络训练执行代码。
/**
* 深度信念网络(Deep Belief Network)
* 每一层神经网络进行训练rbmtrain
*/
def RBMtrain(train_t: RDD[(BDM[Double], BDM[Double])],
opts: Array[Double],
dbnconfig: DBNConfig,
weight: DBNweight): DBNweight = {
valsc = train_t.sparkContext
varStartTime = System.currentTimeMillis()
varEndTime = System.currentTimeMillis()
// 权重参数变量
varrbm_W = weight.W
varrbm_vW = weight.vW
varrbm_b = weight.b
varrbm_vb = weight.vb
varrbm_c = weight.c
varrbm_vc = weight.vc
// 广播参数
valbc_config =sc.broadcast(dbnconfig)
// 训练样本数量
valm = train_t.count
// 计算batch的数量
valbatchsize = opts(0).toInt
valnumepochs = opts(1).toInt
valnumbatches = (m /batchsize).toInt
// numepochs是循环的次数
for (i <-1 tonumepochs) {
StartTime = System.currentTimeMillis()
valsplitW2 = Array.fill(numbatches)(1.0 / numbatches)
varerr =0.0
// 根据分组权重,随机划分每组样本数据
for (l <-1 tonumbatches) {
// 1 广播权重参数
valbc_rbm_W =sc.broadcast(rbm_W)
valbc_rbm_vW =sc.broadcast(rbm_vW)
valbc_rbm_b =sc.broadcast(rbm_b)
valbc_rbm_vb =sc.broadcast(rbm_vb)
valbc_rbm_c =sc.broadcast(rbm_c)
valbc_rbm_vc =sc.broadcast(rbm_vc)
// 2 样本划分
valtrain_split2 = train_t.randomSplit(splitW2, System.nanoTime())
valbatch_xy1 =train_split2(l -1)
// 3 前向计算
// v1 = batch;
// h1 = sigmrnd(repmat(rbm.c', opts.batchsize, 1) + v1 * rbm.W');
// v2 = sigmrnd(repmat(rbm.b', opts.batchsize, 1) + h1 * rbm.W);
// h2 = sigm(repmat(rbm.c', opts.batchsize, 1) + v2 * rbm.W');
// c1 = h1' * v1;
// c2 = h2' * v2;
valbatch_vh1 =batch_xy1.map { f =>
vallable = f._1
valv1 = f._2
valh1 = DBN.sigmrnd((v1 *bc_rbm_W.value.t +bc_rbm_c.value.t))
valv2 = DBN.sigmrnd((h1 *bc_rbm_W.value +bc_rbm_b.value.t))
valh2 = DBN.sigm(v2 *bc_rbm_W.value.t +bc_rbm_c.value.t)
valc1 =h1.t *v1
valc2 =h2.t *v2
(lable, v1,h1,v2,h2,c1,c2)
}
// 4 更新前向计算
// rbm.vW = rbm.momentum * rbm.vW + rbm.alpha * (c1 - c2) / opts.batchsize;
// rbm.vb = rbm.momentum * rbm.vb + rbm.alpha * sum(v1 - v2)' / opts.batchsize;
// rbm.vc = rbm.momentum * rbm.vc + rbm.alpha * sum(h1 - h2)' / opts.batchsize;
// W 更新方向
valvw1 =batch_vh1.map {
case (lable,v1,h1,v2,h2,c1,c2) =>
c1 -c2
}
valinitw = BDM.zeros[Double](bc_rbm_W.value.rows,bc_rbm_W.value.cols)
val (vw2,countw2) =vw1.treeAggregate((initw,0L))(
seqOp = (c, v) => {
// c: (m, count), v: (m)
valm1 = c._1
valm2 =m1 + v
(m2, c._2 +1)
},
combOp = (c1, c2) => {
// c: (m, count)
valm1 = c1._1
valm2 = c2._1
valm3 =m1 + m2
(m3, c1._2 + c2._2)
})
valvw3 =vw2 /countw2.toDouble
rbm_vW = bc_config.value.momentum *bc_rbm_vW.value +bc_config.value.alpha *vw3
// b 更新方向
valvb1 =batch_vh1.map {
case (lable,v1,h1,v2,h2,c1,c2) =>
(v1 -v2)
}
valinitb = BDM.zeros[Double](bc_rbm_vb.value.cols,bc_rbm_vb.value.rows)
val (vb2,countb2) =vb1.treeAggregate((initb,0L))(
seqOp = (c, v) => {
// c: (m, count), v: (m)
valm1 = c._1
valm2 =m1 + v
(m2, c._2 +1)
},
combOp = (c1, c2) => {
// c: (m, count)
valm1 = c1._1
valm2 = c2._1
valm3 =m1 + m2
(m3, c1._2 + c2._2)
})
valvb3 =vb2 /countb2.toDouble
rbm_vb = bc_config.value.momentum *bc_rbm_vb.value +bc_config.value.alpha *vb3.t
// c 更新方向
valvc1 =batch_vh1.map {
case (lable,v1,h1,v2,h2,c1,c2) =>
(h1 -h2)
}
valinitc = BDM.zeros[Double](bc_rbm_vc.value.cols,bc_rbm_vc.value.rows)
val (vc2,countc2) =vc1.treeAggregate((initc,0L))(
seqOp = (c, v) => {
// c: (m, count), v: (m)
valm1 = c._1
valm2 =m1 + v
(m2, c._2 +1)
},
combOp = (c1, c2) => {
// c: (m, count)
valm1 = c1._1
valm2 = c2._1
valm3 =m1 + m2
(m3, c1._2 + c2._2)
})
valvc3 =vc2 /countc2.toDouble
rbm_vc = bc_config.value.momentum *bc_rbm_vc.value +bc_config.value.alpha *vc3.t
// 5 权重更新
// rbm.W = rbm.W + rbm.vW;
// rbm.b = rbm.b + rbm.vb;
// rbm.c = rbm.c + rbm.vc;
rbm_W = bc_rbm_W.value +rbm_vW
rbm_b = bc_rbm_b.value +rbm_vb
rbm_c = bc_rbm_c.value +rbm_vc
// 6 计算误差
valdbne1 =batch_vh1.map {
case (lable,v1,h1,v2,h2,c1,c2) =>
(v1 -v2)
}
val (dbne2,counte) =dbne1.treeAggregate((0.0,0L))(
seqOp = (c, v) => {
// c: (e, count), v: (m)
vale1 = c._1
vale2 = (v :* v).sum
valesum =e1 + e2
(esum, c._2 +1)
},
combOp = (c1, c2) => {
// c: (e, count)
vale1 = c1._1
vale2 = c2._1
valesum =e1 + e2
(esum, c1._2 + c2._2)
})
valdbne =dbne2 /counte.toDouble
err += dbne
}
EndTime = System.currentTimeMillis()
// 打印误差结果
printf("epoch: numepochs = %d , Took = %d seconds; Average reconstruction error is: %f.\n",i, scala.math.ceil((EndTime -StartTime).toDouble /1000).toLong,err / numbatches.toDouble)
}
new DBNweight(rbm_W,rbm_vW,rbm_b, rbm_vb,rbm_c,rbm_vc)
}
2.2.4 DBNModel解析
(1) DBNModel
DBNModel:存储DBN网络参数,包括:config配置参数,dbn_W权重,dbn_b偏置,dbn_c偏置。
class DBNModel(
valconfig: DBNConfig,
valdbn_W: Array[BDM[Double]],
valdbn_b: Array[BDM[Double]],
valdbn_c: Array[BDM[Double]])extends Serializable {
}
(2) dbnunfoldtonn
dbnunfoldtonn:将DBN网络参数转换为NN参数。
/**
* DBN模型转化为NN模型
* 权重转换
*/
defdbnunfoldtonn(outputsize: Int): (Array[Int], Int, Array[BDM[Double]]) = {
//1 size layer 参数转换
valsize =if (outputsize >0) {
valsize1 =config.size
valsize2 = ArrayBuffer[Int]()
size2 ++= size1
size2 += outputsize
size2.toArray
} elseconfig.size
vallayer =if (outputsize >0)config.layer +1elseconfig.layer
//2 dbn_W 参数转换
varinitW = ArrayBuffer[BDM[Double]]()
for (i <-0 todbn_W.length -1) {
initW += BDM.horzcat(dbn_c(i),dbn_W(i))
}
(size, layer,initW.toArray)
}
转载请注明出处:
http://blog.csdn.net/sunbow0