(11.1.8)Hadoop基础教程之高级编程
从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤:
1.输入(input):将输入数据分成一个个split,并将split进一步拆成<key, value>。
2.映射(map):根据输入的<key, value>进生处理,
3.合并(combiner):合并中间相两同的key值。
4.分区(Partition):将<key, value>分成N分,分别送到下一环节。
5.化简(Reduce):将中间结果合并,得到最终结果
6.输出(output):负责输入最终结果。
其中第3、4步又成洗牌(shuffle)过程。
从前面HelloWorld示例中,我们看到,我们只去个性化了Map和Reduce函数,那其他函数呢,是否可以个性化?答案当然是肯定的。下面我们就对每个环节的个性化进行介绍。
自定义输入格式
输 入格式(InputFormat)用于描述整个MapReduce作业的数据输入规范。先对输入的文件进行格式规范检查,如输入路径,后缀等检查;然后对 数据文件进行输入分块(split);再对数据块逐一读出;最后转换成Map所需要的<key, value>健值对。
系统中提供丰富的预置输入格式。最常用的以下两种:
TextInputFormat:系统默认的数据输入格式。将文件分块,并逐行读入,每一行记录行成一对<key, value>。其中,key值为当前行在整个文件中的偏移量,value值为这一行的文本内容。
KeyValueTextInputFormat:这是另一个常用的数据输入格式,读入的文本文件内容要求是以<key, value>形式。读出的结果也就直接形成<key, value>送入map函数中。
如果选择输入格式呢?那就只要在job函数中调用
|
1
|
job.setInputFormatClass(TextInputFormat.
class
);
|
一般情况够用了,但某些情况下,还是无法满足用户的需求,所以还是需要个性化。个性化则按下面的方式进行:
如果数据我们是来源于文件,则可以继承FileInputFormat:
|
1
2
3
4
5
6
7
8
|
public
class
MyInputFormat
extends
FileInputFormat<Text,Text> {
@Override
public
RecordReader<Text, Text> createRecordReader(InputSplit split,
TaskAttemptContext context)
throws
IOException, InterruptedException {
// TODO Auto-generated method stub
return
null
;
}
}
|
如果数据我们是来源于非文件,如关系数据,则继承
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public
class
MyInputFormat
extends
InputFormat<Text,Text> {
@Override
public
RecordReader<Text, Text> createRecordReader(InputSplit arg0,
TaskAttemptContext arg1)
throws
IOException, InterruptedException {
// TODO Auto-generated method stub
return
null
;
}
@Override
public
List<InputSplit> getSplits(JobContext arg0)
throws
IOException,
InterruptedException {
// TODO Auto-generated method stub
return
null
;
}
}
|
这里比较清晰了,下面个函数为拆分成split,上面个函数跟据split输出成Key,value。
自定义map处理
这个好理解,我们的HelloWorld程序中就自定义了map处理函数。然后在job中指定了我们的处理类:
|
1
|
job.setMapperClass(TokenizerMapper.
class
);
|
个性化代码如下:
|
1
2
3
4
5
6
7
|
public
static
class
TokenizerMapper
extends
Mapper<Object, Text, Text, IntWritable>{
public
void
map(Object key, Text value, Context context
)
throws
IOException, InterruptedException {
context.write(key, value);
}
}
|
自定义合并Combiner
自定义合并Combiner类,主要目的是减少Map阶段输出中间结果的数据量,降低数据的网络传输开销。
Combine 过程,实际跟Reduce过程相似,只是执行不同,Reduce是在Reducer环节运行,而Combine是紧跟着Map之后,在同一台机器上预先将 结时进行一轮合并,以减少送到Reducer的数据量。所以在HelloWorld时,可以看到,Combiner和Reducer用的是同一个类:
|
1
2
|
job.setCombinerClass(IntSumReducer.
class
);
job.setReducerClass(IntSumReducer.
class
);
|
如何个性化呢,这个跟Reducer差不多了:
|
1
2
3
4
5
6
7
8
|
public
static
class
MyCombiner
extends
Reducer<Text,IntWritable,Text,IntWritable> {
public
void
reduce(Text key, Iterable<IntWritable> values,
Context context
)
throws
IOException, InterruptedException {
context.write(key,
new
IntWritable(
1
));
}
}
|
自定义分区Partitioner
在 MapReduce程序中,Partitioner决定着Map节点的输出将被分区到哪个Reduce节点。而默认的Partitioner是 HashPartitioner,它根据每条数据记录的主健值进行Hash操作,获得一个非负整数的Hash码,然后用当前作业的Reduce节点数取模 运算,有N个结点的话,就会平均分配置到N个节点上,一个隔一个依次。大多情况下这个平均分配是够用了,但也会有一些特殊情况,比如某个文件的,不能被拆 开到两个结点中,这样就需要个性化了。
个性化方式如下:
|
1
2
3
4
5
6
|
public
static
class
MyPartitioner
extends
HashPartitioner<K,V> {
public
void
getPartition(K key, V value,
int
numReduceTasks) {
super
.getPartition(key,value,numReduceTasks);
}
}
|
方式其实就是在执行之前可以改变一下key,来欺骗这个hash表。
自定义化简(Reducer)
这一块是将Map送来的结果进行化简处理,并形成最终的输出值。与前面map一样,在HelloWorld中我们就见到过了。通过下面代码可以设置其值:
|
1
|
job.setReducerClass(IntSumReducer.
class
);
|
如果要个性化,则如下:
|
1
2
3
4
5
6
7
8
|
public
static
class
IntSumReducer
extends
Reducer<Text,IntWritable,Text,IntWritable> {
public
void
reduce(Text key, Iterable<IntWritable> values,
Context context
)
throws
IOException, InterruptedException {
context.write(key, result);
}
}
|
自定义输出格式
数 据输出格式(OutPutFormat)用于描述MapReduce作业的数据输出规范。Hadoop提供了丰富的内置数据输出格式。最常的数据输出格式 是TextOutputFormat,也是系统默认的数据输出格式,将结果以"key+\t+value"的形式逐行输出到文本文件中。还有其它的, 如:DBOutputFormat,FileOutputFormat,FilterOutputFormat,IndexUpdataOutputFormat,LazyOutputFormat,MapFileOutputFormat, 等等。
如果要个性化,则按下面方式进行:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public
class
MyOutputFormat
extends
OutputFormat<Text,Text> {
@Override
public
void
checkOutputSpecs(JobContext arg0)
throws
IOException,
InterruptedException {
// TODO Auto-generated method stub
}
@Override
public
OutputCommitter getOutputCommitter(TaskAttemptContext arg0)
throws
IOException, InterruptedException {
// TODO Auto-generated method stub
return
null
;
}
@Override
public
RecordWriter<Text, Text> getRecordWriter(TaskAttemptContext arg0)
throws
IOException, InterruptedException {
// TODO Auto-generated method stub
return
null
;
}
}
|
复合健——用户自定义类型。
从前面的整个过程中可以看到,都是采用key-value的方式进行传入传出,而这些类型大多是单一的字符串,和整型。如果我的key中需要包含多个信息怎么办?用字符串直接拼接么? 太不方便了,最好能够自己定义一个类,作为这个key,这样就方便了。 如果定义一个类作为key 或value的类型? 有什么要求?就是这个类型必须要继承WritableComparable<T>这个类,所以如果要自定义一个类型则可以这么实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public
class
MyType
implements
WritableComparable<MyType> {
private
float
x,y;
public
float
GetX(){
return
x;}
public
float
GetY(){
return
y;}
@Override
public
void
readFields(DataInput in)
throws
IOException {
x = in.readFloat();
y = in.readFloat();
}
@Override
public
void
write(DataOutput out)
throws
IOException {
out.writeFloat(x);
out.writeFloat(y);
}
@Override
public
int
compareTo(MyType arg0) {
//输入:-1(小于) 0(等于) 1(大于)
return
0
;
}
}
|
这个示例中,我们添加了两个float变量:x,y 。 这个信息能过int 和out按次序进行输入输出。最后,再实现一个比较函数即可。
Job任务的创建
|
1
2
3
4
5
6
7
8
9
10
11
12
|
Job job =
new
Job(conf,
"word count"
);
job.setJarByClass(WordCount.
class
);
job.setInputFormatClass(MyInputFormat.
class
);
job.setMapperClass(TokenizerMapper.
class
);
job.setCombinerClass(IntSumReducer.
class
);
job.setPartitionerClass(MyPartitioner.
class
);
job.setReducerClass(IntSumReducer.
class
);
job.setOutputFormatClass(TextOutputFormat.
class
);
job.setOutputKeyClass(Text.
class
);
job.setOutputValueClass(IntWritable.
class
);
FileInputFormat.addInputPath(job,
new
Path(otherArgs[
0
]));
FileOutputFormat.setOutputPath(job,
new
Path(otherArgs[
1
]));
|
任务创建比较容易,其实就是new一个实例,然后把上面描述的过程类设置好,然后加上第2行中,jar包的主类,第10、11行的输入输出路径。这样就完事了。
Job任务的执行
单个任务的执行,没有什么问题,可以用这个:
|
1
|
job.waitForCompletion(
true
);
|
但多个任务呢? 多个任务的话,就会形成其组织方式,有串行,有并行,有无关,有组合的,如下图:
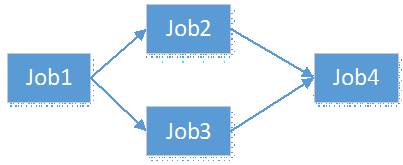
图中,Job2和Job3将会等Job1执行完了再执行,且可以同时开始,而Job4必须等Job2和Job3同时结束后才结束。
这个组合,就可以采用这样的代码来实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
Configuration conf =
new
Configuration();
Job job1 =
new
Job(conf,
"job1"
);
//.. config Job1
Job job2 =
new
Job(conf,
"job2"
);
//.. config Job2
Job job3 =
new
Job(conf,
"job3"
);
//.. config Job3
Job job4 =
new
Job(conf,
"job4"
);
//.. config Job4
//添加依赖关系
job2.addDependingJob(job1);
job3.addDependingJob(job1);
job4.addDependingJob(job2);
job4.addDependingJob(job3);
JobControl jc =
new
JobControl(
"jbo name"
);
jc.addJob(job1);
jc.addJob(job2);
jc.addJob(job3);
jc.addJob(job4);
jc.run();
|
总述
现在回头看看,其实整个hadoop编程,也就是这几块内容了,要实现某个功能,我们就往上面这些步骤上套,然后联起来执行,达到我们的目的。