C++编程思想重点笔记
-
C和C++指针的最重要的区别在于:C++是一种类型要求更强的语言。就
void *而言,这一点表现得更加突出。C虽然不允许随便地把一个类型的指针指派给另一个类型,但允许通过void *来实现。例如:bird* b; rock* r; void* v; v = r; b = v;
C++不允许这样做,其编译器将会给出一个出错信息。如果真的想这样做,必须显式地使用映射,通知编译器和读者。
-
参数传递准则
当给函数传递参数时,人们习惯上应该是通过常量引用来传递,这种简单习惯可以大大提高效率:传值方式需要调用构造函数和析构函数,然而如果不想改变参数,则可通过常量引用传递,它仅需要将地址压栈。 事实上,只有一种情况不适合用传递地址方式,这就是当传值是唯一安全的途径,否则将会破坏对象(而不是修改外部对象,这不是调用者通常期望的)。 -
C++访问权限控制:public、private、protected
其中protected只有在继承中才有不同含义,否则与private相同,也就是说两者只有一点不同:继承的结构可以访问protected成员,但不能访问private成员。 -
前置声明注意
struct X; // Declaration(incomplete type spec) struct Y { void f(X *memx); void g(X memx); // not allowed, the size of X is unknown. };
这里f(X*)引用了一个X对象的地址,这是没有任何问题的,但如果是
void g(X memx);就不行了,编译器会报错。这一点很关键,因为编译器知道如何传递一个地址,这一地址大小是一定的,而不用管被传递的对象类型大小。如果试图传递整个对象,编译器就必须知道X的全部定义以确定它的大小以及如何传递它,这就使程序员无法声明一个类似于Y :: g(X) 的函数。 -
C++是纯的吗?
如果某个类的一个函数被声明为friend,就意味着它不是这个类的成员函数,但却可以修改类的私有成员, 而且它必须被列在类的定义中,因此我们可以认为它是一个特权函数。这种类的定义提供了有关权限的信息,我们可以知道哪些函数可以改变类的私有部分。 因此,C++不是完全的面向对象语言,它只是一个混合产品。friend关键字就是用来解决部分的突发问题。它也说明了这种语言是不纯的。毕竟C + +语言的设计是为了实用,而不是追求理想的抽象。 -
C++输入输出流的操纵算子(manipulator)有:endl、flush、ws、hex等。
cout<<flush; // 清空流 cout << hex << "0x" << i; // 输出16进制 cin>>ws; // 跳过空格
iostream.h还包括以下的操纵算子:
如何建立我们自己的操纵算子?
我们可能想建立自己的操纵算子,这是相当简单的。一个像endl这样的不带参数的操纵算子只是一个函数,这个函数把一个ostream引用作为它的参数。对endl的声明是:ostream& endl(ostream&);
例子:产生一个换行而不刷新这个流。人们认为nl比使用endl要好,因为后者总是清空输出流,这可能引起执行故障。

ostream& nl(ostream& os) { return os << "\n"; } int main() { cout << "newlines" << nl << "between" << nl << "each" << nl << "word" << nl; return 0; }
-
C语言中const与C++中const的区别:
常量引进是在早期的C++版本中,当时标准C规范正在制订。那时,常量被看作是一个好的思想而被包含在C中。但是,C中的const意思是“一个不能被改变的普通变量”,在C中,它总是占用存储而且它的名字是全局符。C编译器不能把const看成一个编译期间的常量。在C中, 如果写:const bufsize=100; char buf[bufsize];
尽管看起来好像做了一件合理的事,但这将得到一个错误结果。因为bufsize占用存储的某个地方,所以C编译器不知道它在编译时的值。在C语言中可以选择这样书写:
const bufsize;这样写在C++中是不对的,而C编译器则把它作为一个声明,这个声明指明在别的地方有存储分配。因为C默认const是外部连接的,C++默认cosnt是内部连接的,这样,如果在C++中想完成与C中同样的事情,必须用extern把连接改成外部连接:
extern const bufsize;//declaration only
这种方法也可用在C语言中。
注意:在C语言中使用限定符const不是很有用,即使是在常数表达式里(必须在编译期间被求出);想使用一个已命名的值,使用const也不是很有用的。C迫使程序员在预处理器里使用#define。 -
类里的const和enum
下面的写法有什么问题吗?:class bob { const size = 100; // illegal int array[size]; // illegal }
结果当然是编译不通过。why?因为const在类对象里进行了存储空间分配,编译器不能知道const的内容是什么,所以不能把它用作编译期间的常量。这意味着对于类里的常数表达式来说,const就像它在C中一样没有作用。
在类里的const意思是“在这个特定对象的寿命期内,而不是对于整个类来说,这个值是不变的”。那么怎样建立一个可以用在常数表达式里的类常量呢?
一个普通的办法是使用一个不带实例的无标记的enum。枚举的所有值必须在编译时建立,它对类来说是局部的,但常数表达式能得到它的值,这样,我们一般会看到:class bob { enum { size = 100 }; // legal int array[size]; // legal }
使用enum是不会占用对象中的存储空间的,枚举常量在编译时被全部求值。我们也可以明确地建立枚举常量的值:
enum { one=1,two=2,three}; -
类里面的const成员函数
class X { int i; public: int f() const; }
这里f()是const成员函数,表示只能const类对象调用这个函数(const对象不能调用非const成员函数),如果我们改变对象中的任何一个成员或调用一个非const成员函数,编译器将发出一个出错信息。
关键字const必须用同样的方式重复出现在定义里,否则编译器把它看成一个不同的函数:int X::f() const { return i;}
任何不修改成员数据的函数应该声明为const函数,这样它可以由const对象使用。
注意:构造函数和析构函数都不是const成员函数,因为它们在初始化和清理时,总是对对象作些修改。引申:如何在const成员函数里修改成员 —— 按位和与按成员const
如果我们想要建立一个const成员函数,但仍然想在对象里改变某些数据,这时该怎么办呢?这关系到按位const和按成员const的区别。按位const意思是对象中的每个位是固定的,所以对象的每个位映像从不改变。按成员const意思是,虽然整个对象从概念上讲是不变的,但是某个成员可能有变化。当编译器被告知一个对象是const对象时,它将保护这个对象。
这里我们要介绍在const成员函数里改变数据成员的两种方法。
-
第一种方法已成为过去,称为“强制转换const”。它以相当奇怪的方式执行。取this(这个关键字产生当前对象的地址)并把它强制转换成指向当前类型对象的指针。看来this已经是我们所需的指针,但它是一个const指针,所以,还应把它强制转换成一个普通指针,这样就可以在运算中去掉常量性。下面是一个例子:
class Y { int i, j; public: Y() { i = j = 0; } void f() const; }; void Y::f() const { //! i++; // error ((Y*)this)->j++; // ok , cast away const feature. }
这种方法可行,在过去的程序代码里可以看到这种用法,但这不是首选的技术。问题是:this没有用const修饰,这在一个对象的成员函数里被隐藏,这样,如果用户不能见到源代码(并找到用这种方法的地方),就不知道发生了什么。
-
第二种方法也是推荐的方法,就是在类声明里使用关键字
mutable,以指定一个特定的数据成员可以在一个const对象里被改变。
class Y { int i; mutable int j; public: Y() { i = j = 0; } void f() const; }; void Y::f() const { //! i++; // error ((Y*)this)->j++; // ok , mutable. }
-
- volatile关键字
volatile的语法与const是一样的,但是volatile的意思是“在编译器认识的范围外,这个数据可以被改变”。不知何故,环境正在改变数据(可能通过多任务处理),所以,volatile告诉编译器不要擅自做出有关数据的任何假定—在优化期间这是特别重要的。如果编译器说:“我已经把数据读进寄存器,而且再没有与寄存器接触”。一般情况下,它不需要再读这个数据。但是,如果数据是volatile修饰的,编译器不能作出这样的假定,因为可能被其他进程改变了, 它必须重读这个数据而不是优化这个代码。
注意:
- 就像建立const对象一样,程序员也可以建立volatile对象,甚至还可以建立const volatile对 象,这个对象不能被程序员改变,但可通过外面的工具改变。
- 就像const一样,我们可以对数据成员、成员函数和对象本身使用volatile,可以并且也只能为volatile对象调用volatile成员函数。
- volatile的语法与const是一样的,所以经常把它们俩放在一起讨论。为表示可以选择两个中的任何一个,它们俩通称为c-v限定词。
上篇请看:C++编程思想重点笔记(上)
-
宏的好处与坏处
-
宏的好处:#与##的使用
三个有用的特征:字符串定义、字符串串联和标志粘贴。
字符串定义的完成是用#指示,它容许设一个标识符并把它转化为字符串,然而字符串串联发生在当两个相邻的字符串没有分隔符时,在这种情况下字符串组合在一起。在写调试代码时,这两个特征是非常有效的。
#define DEBUG(X) cout<<#X " = " << X << endl上面的这个定义可以打印任何变量的值。
我们也可以得到一个跟踪信息,在此信息里打印出它们执行的语句。
#define TRACE(S) cout << #S << endl; S#S定义了要输出的语句。第2个S重申了语句,所以这个语句被执行。当然,这可能会产生问题,尤其是在一行for循环中。for (int i = 0 ; i < 100 ; i++ ) TRACE(f(i)) ;
因为在TRACE( )宏里实际上有两个语句,所以一行for循环只执行第一个。
for (int i = 0 ; i < 100 ; i++ ) cout << "f(i)" << endl; f(i); // 第二条语句脱离了for循环,因此执行不到
解决方法是在宏中用逗号代替分号。
标志粘贴在写代码时是非常有用的,用##表示。它让我们设两个标识符并把它们粘贴在一起自动产生一个新的标识符。例如:
#define FIELD(A) char *A##_string;int A##_size此时下面的代码:
class record{ FIELD(one); FIELD(two); FIELD(three); //... };
就相当于下面的代码:
class record{ char *one_string,int one_size; char *two_string,int two_size; char *three_string,int three_size; //... };
-
宏的不好:容易出错
下面举个例子即可说明:
#define band(x) (((x)>5 && (x)<10) ? (x) :0) int main() { for(int i = 4; i < 11; i++) { int a = i; cout << "a = " << a << "\t"; cout << "band(++a)" << band(++a) << "\t"; cout << "a = " << a << endl; } return 0; }
输出:
a = 4 band(++a)0 a = 5
a = 5 band(++a)8 a = 8
a = 6 band(++a)9 a = 9
a = 7 band(++a)10 a = 10
a = 8 band(++a)0 a = 10
a = 9 band(++a)0 a = 11
a = 10 band(++a)0 a = 12
-
-
存储类型指定符
常用的有static和extern。
不常用的有两个:一是auto,人们几乎不用它,因为它告诉编译器这是一个局部变量,实际上编译器总是可以从 变量定义时的上下文中判断出这是一个局部变量。所以auto是多余的。还有一个是register,它也是局部变量,但它告诉编译器这个特殊的变量要经常用到,所以编译器应该尽可能地让它保存在寄存器中。它用于优化代码。各种编译器对这种类型的变量处理方式也不尽相同,它们有时会忽略这种存储类型的指定。一般,如果要用到这个变量的地址,register指定符通常都会被忽略。应该避免用register类型,因为编译器在优化代码方面通常比我们做得更好。 -
位拷贝(bitcopy)与值拷贝的区别(很重要)
由1个例子来说明:一个类在任何时候知道它存在多少个对象,可以通过包含一个static成员来做到,如下代码所示:
#include <iostream> using namespace std; class test { static int object_count; public: test() { object_count++; print("test()"); } static void print(const char *msg = 0) { if(msg) cout << msg << ": "; cout << "object_count = " << object_count << endl; } ~test() { object_count--; print("~test()"); } }; int test::object_count = 0; // pass and return by value. test f(test x) { x.print("x argument inside f()"); return x; } int main() { test h; test::print("after construction of h"); test h2 = f(h); test::print("after call to f()"); return 0; }
然而输出并不是我们期望的那样:
test(): object_count = 1
after construction of h: object_count = 1
x argument inside f(): object_count = 1
~test(): object_count = 0
after call to f(): object_count = 0
~test(): object_count = -1
~test(): object_count = -2在h生成以后,对象数是1,这是对的。我们希望在f()调用后对象数是2,因为h2也在范围内。然而,对象数是0,这意味着发生了严重的错误。这从结尾两个析构函数执行后使得对象数变为负数的事实得到确认,有些事根本就不应该发生。
让我们来看一下函数f()通过传值方式传入参数那一处。原来的对象h存在于函数框架之外,同时在函数体内又增加了一个对象,这个对象是传值方式传入的对象的拷贝,这属于位拷贝,调用的是默认拷贝构造函数,而不是调用构造函数。然而,参数的传递是使用C的原始的位拷贝的概念,但test类需要真正的初始化来维护它的完整性。所以,缺省的位拷贝不能达到预期的效果。
当局部对象出了调用的函数f()范围时,析构函数就被调用,析构函数使object_count减小。 所以,在函数外面, object_count等于0。h2对象的创建也是用位拷贝产生的(也是调用默认拷贝构造函数),所以,构造函数在这里也没有调用。当对象h和h2出了它们的作用范围时,它们的析构函数又使object_count值变为负值。
总结:
- 位拷贝拷贝的是地址(也叫浅拷贝),而值拷贝则拷贝的是内容(深拷贝)。
- 深拷贝和浅拷贝可以简单理解为:如果一个类拥有资源,当这个类的对象发生复制过程的时候,资源重新分配,这个过程就是深拷贝,反之,没有重新分配资源,就是浅拷贝。
- 默认的拷贝构造函数”和“缺省的赋值函数”均采用“位拷贝”而非“值拷贝”的方式来实现,倘若类中含有指针变量,这两个函数注定将出错。
关于位拷贝和值拷贝的深入理解可以参考这篇文章:C++中的位拷贝与值拷贝浅谈
为了达到我们期望的效果,我们必须自己定义拷贝构造函数:
test(const test& t) { object_count++; print("test(const test&)"); }
这样输出才正确:
test(): object_count = 1
after construction of h: object_count = 1
test(const test&): object_count = 2
x argument inside f(): object_count = 2
test(const test&): object_count = 3
~test(): object_count = 2
after call to f(): object_count = 2
~test(): object_count = 1
~test(): object_count = 0引申
-
如果在main中加一句“f(h);”,即忽略返回值,那么返回的时候还会调用拷贝构造函数吗?
答案是:会调用。这时候会产生一个临时对象,由于该临时对象没有用处,因此会马上调用析构函数销毁掉。这时候输出就会像下面这样:test(): object_count = 1
after construction of h: object_count = 1
test(const test&): object_count = 2
x argument inside f(): object_count = 2
test(const test&): object_count = 3
~test(): object_count = 2
after call to f(): object_count = 2
test(const test&): object_count = 3
x argument inside f(): object_count = 3
test(const test&): object_count = 4
~test(): object_count = 3
~test(): object_count = 2
~test(): object_count = 1
~test(): object_count = 0 -
如果一个类由其它几个类的对象组合而成,如果此时该类没有自定义拷贝构造函数,那么编译器递归地为所有的成员对象和基本类调用拷贝构造函数。如果成员对象也含有别的对象,那么后者的拷贝构造函数也将被调用。
-
怎样避免调用拷贝构造函数?仅当准备用传值的方式传递类对象时,才需要拷贝构造函数。有两种解决方法:
- 防止传值方法传递
有一个简单的技术防止通过传值方式传递:声明一个私有private拷贝构造函数。我们甚至不必去定义它,除非我们的成员函数或友元函数需要执行传值方式的传递。如果用户试图用传值方式传递或返回对象,编译器将会发出一个出错信息。这是因为拷贝构造函数是私有的。因为我们已显式地声明我们接管了这项工作,所以编译器不再创建缺省的拷贝构造函数。
class noCC { int i; noCC(const noCC&); // private and no definition public: noCC(int I = 0) : i(I) {} }; void f(noCC); main() { noCC n; //! f(n); // error: copy-constructor called //! noCC n2 = n; // error: c-c called //! noCC n3(n); // error: c-c called }
注意这里`n2 = n`也调用拷贝构造函数,注意这里要和赋值函数区分。
- 改变外部对象的函数
使用引用传递:比如void get(const Slice&);
- 防止传值方法传递
-
非自动继承的函数
构造函数、析构函数和赋值函数(operator=)不能被继承。 -
私有继承的目的
private继承的目的是什么,因为在类中选择创建一个private对象似乎更合适。将private继承包含在该语言中只是为了语言的完整性。但是,如果没有其他理由,则应当减少混淆,所以通常建议用private成员而不是private继承。
然而,private继承也不是一无用处。
这里可能偶然有这种情况,即可能想产生像基类接口一样的接口,而不允许处理该对象像处理基类对象一样。private继承提供了这个功能。引申
能对私有继承成员公有化吗?
当私有继承时,基类的所有public成员都变成了private。如果希望它们中的任何一个是可视的,可以办到吗?答案是可以的,只要用派生类的public选项声明它们的名字即可(新的标准中使用using关键字)。
#include <iostream> class base { public: char f() const { return 'a'; } int g() const { return 2; } float h() const { return 3.0; } }; class derived : base { public: using base::f; // Name publicizes member using base::h; }; int main() { derived d; d.f(); d.h(); // d.g(); // error -- private function return 0; }
这样,如果想要隐藏这个类的基类部分的功能,则
private继承是有用的。 -
多重继承注意向上映射的二义性。比如base(有个f()方法)有两个子对象d1和d2,且都重写了base的f()方法,此时子类dd如果也有f()方法则不能同时继承自d1和d2,因为f()方法存在二义性,不知道该继承哪个f()方法。
解决方法是对dd类中的f()方法重新定义以消除二义性,比如明确指定使用d1的f()方法。
当然也不能将dd类向上映射为base类,这可以通过使用虚继承解决,关键字virtual,base中的f()方法改成虚函数且d1和d2的继承都改为虚继承,当然dd继承d1和d2用public继承即可。 -
C语言中如何关闭assert断言功能?
头文件:<assert.h>或<cassert>
在开发过程中,使用它们,完成后用#define NDEBUG使之失效,以便推出产品,注意必须在头文件之前关闭才有效。#define NDEBUG #include <cassert>
- C++如何实现动态捆绑?—即多态的实现(很重要)
C++中为了实现多态,编译器对每个包含虚函数的类创建一个表(称为VTABLE,虚表)。在 VTABLE中,编译器放置特定类的虚函数地址。在每个带有虚函数的类中,编译器秘密地置一指针,称为vpointer(缩写为VPTR),指向这个对象的VTABLE。通过基类指针做虚函数调用时(也就是做多态调用时),编译器静态地插入取得这个VPTR,并在VTABLE表中查找函数地址的代码,这样就能调用正确的函数使晚捆绑发生。
为每个类设置VTABLE、初始化VPTR、为虚函数调用插入代码,所有这些都是自动发生的,所以我们不必担心这些。利用虚函数,这个对象的合适的函数就能被调用,哪怕在编译器还不知道这个对象的特定类型的情况下。在vtable表中,编译器放置了在这个类中或在它的基类中所有已声明为
virtual的函数的地址。如果在这个派生类中没有对在基类中声明为virtual的函数进行重新定义,编译器就使用基类的这个虚函数地址。
下面举个例子说明:
#include <iostream> enum note { middleC, Csharp, Cflat }; class instrument { public: virtual void play(note) const { cout << "instrument::play" << endl; } virtual char* what() const { return "instrument"; } // assume this will modify the object: virtual void adjust(int) {} }; class wind : public instrument { public: void play(note) const { cout << "wind::play" << endl; } char* what() const { return "wind"; } void adjust(int) {} }; class percussion : public instrument { public: void play(note) const { cout << "percussion::play" << endl; } char* what() const { return "percussion"; } void adjust(int) {} }; class string : public instrument { public: void play(note) const { cout << "string::play" << endl; } char* what() const { return "string"; } void adjust(int) {} }; class brass : public wind { public: void play(note) const { cout << "brass::play" << endl; } char* what() const { return "brass"; } }; class woodwind : public wind { public: void play(note) const { cout << "woodwind::play" << endl; } char* what() const { return "woodwind"; } }; instrument *A[] = { new wind, new percussion, new string, new brass };
下图画的是指针数组A[]。

指针数组A下面看到的是通过instrument指针对于brass调用adjust()。instrument引用产生如下结果:
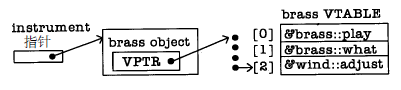
动态绑定编译器从这个instrument指针开始,这个指针指向这个对象的起始地址。所有的instrument对象或由instrument派生的对象都有它们的VPTR,它在对象的相同的位置(常常在对象的开头),所以编译器能够取出这个对象的VPTR。VPTR指向VTABLE的开始地址。所有的VTABLE有相同的顺序,不管何种类型的对象。 play()是第一个,what()是第二个,adjust()是第三个。所以编译器知道adjust()函数必在VPTR + 2处。这样,不是“以instrument :: adjust地址调用这个函数”(这是早捆绑,是错误活动),而是产生代码,“在VPTR + 2处调用这个函数”。因为VPTR的效果和实际函数地址的确定发生在运行时,所以这样就得到了所希望的晚捆绑。向这个对象发送消息,这个对象能断定它应当做什么。
引申 — 对象切片
当多态地处理对象时,传地址与传值有明显的不同。所有在这里已经看到的例子和将会看到的例子都是传地址的,而不是传值的。这是因为地址都有相同的长度,传派生类型(它通常稍大一些)对象的地址和传基类(它通常小一点)对象的地址是相同的。如前面解释的,使用多态的目的是让对基类对象操作的代码也能操作派生类对象。
如果使用对象而不是使用地址或引用进行向上映射,发生的事情会使我们吃惊:这个对象 被“切片”,直到所剩下来的是适合于目的的子对象。在下面例子中可以看到通过检查这个对象的长度切片剩下来的部分。
#include <iostream> using namespace std; class base { int i; public: base(int I = 0) : i(I) {} virtual int sum() const { return i; } }; class derived : public base { int j; public: derived(int I = 0, int J = 0) : base(I), j(J) {} virtual int sum() const { return base::sum() + j; } }; void call(base b) { cout << "sum = " << b.sum() << endl; } main() { base b(10); derived d(10, 47); call(b); call(d); }
函数call( )通过传值传递一个类型为base的对象。然后对于这base对象调用虚函数sum( )。 我们可能希望第一次调用产生10,第二次调用产生57。实际上,两次都产生10。 在这个程序中,有两件事情发生了。
- 第一,call( )接受的只是一个base对象,所以所有在这个函数体内的代码都将只操作与base相关的数。 对call( )的任何调用都将引起一个与base大小相同的对象压栈并在调用后清除。这意味着,如果一个由base派生来类对象被传给call,编译器接受它,但只拷贝这个对象对应于base的部分,切除这个对象的派生部分,如图:
现在,我们可能对这个虚函数调用感到奇怪:这里,这个虚函数既使用了base(它仍存在), 又使用了derived的部分(derived不再存在了,因为它被切片)。 其实我们已经从灾难中被解救出来,这个对象正安全地以值传递。因为这时编译器认为它知道这个对象的确切的类型(这个对象的额外特征有用的任何信息都已经失去)。

-
另外,用值传递时,它对base对象使用拷贝构造函数,该构造函数初始化vptr指向base vtable,并且只拷贝这个对象的base部分。这里没有显式的拷贝构造函数,所以编译器自动地为我们合成一个。由于上述诸原因,这个对象在切片期间变成了一个base对象。
对象切片实际上是去掉了对象的一部分,而不是象使用指针或引用那样简单地改变地址的内容。因此,对象向上映射不常做,事实上,通常要提防或防止这种操作。我们可以通过在基 类中放置纯虚函数来防止对象切片。这时如果进行对象切片就将引起编译时的出错信息。
最后注意:虚机制在构造函数中不工作。即在构造函数中调用虚函数没有结果。
- 第一,call( )接受的只是一个base对象,所以所有在这个函数体内的代码都将只操作与base相关的数。 对call( )的任何调用都将引起一个与base大小相同的对象压栈并在调用后清除。这意味着,如果一个由base派生来类对象被传给call,编译器接受它,但只拷贝这个对象对应于base的部分,切除这个对象的派生部分,如图:
- RTTI—运行时类型识别(很重要)
-
概念
运行时类型识别(Run-time type identification, RTTI)是在我们只有一个指向基类的指针或引用时确定一个对象的准确类型。
-
使用方法
一般情况下,我们并不需要知道一个类的确切类型,虚函数机制可以实现那种类型的正确行为。但是有些时候,我们有指向某个对象的基类指针,确定该对象的准确类型是很有用的。
RTTI与异常一样,依赖驻留在虚函数表中的类型信息。如果试图在一个没有虚函数的类上用RTTI,就得不到预期的结果。RTTI的两种使用方法
- 第一种使用
typeid(),就像sizeof()一样,看上都像一个函数。但实际上它是由编译器实现的。typeid()带有一个参数,它可以是一个对象引用或指针,返回全局typeinfo类的常量对象的一个引用。可以用运算符“==”和“!=”来互相比较这些对象。也可以用name()来获得类型的名称。注意,如果给typeid( )传递一个shape*型参数,它会认为类型为shape*,所以如果想知道一个指针所指对象的精确类型,我们必须逆向引用这个指针。比如,s是个shape*, 那么:cout << typeid(*s).name()<<endl;
也可以用before(typeinfo&)查询一个typeinfo对象是否在另一个typeinfo对象的前面(以定义实现的排列顺序),它将返回true或false。如果写:if(typeid(me).before(typeid(you))) //... - RTTI的第二个用法叫“安全类型向下映射”。使用
dynamic_cast<>模板。
两种方法的使用举例如下:
#include <iostream> #include <typeinfo> using namespace std; class base { int i; public: base(int I = 0) : i(I) {} virtual int sum() const { return i; } }; class derived : public base { int j; public: derived(int I = 0, int J = 0) : base(I), j(J) {} virtual int sum() const { return base::sum() + j; } }; main() { base *b = new derived(10, 47); // rtti method1 cout << typeid(b).name() << endl; // P4base cout << typeid(*b).name() << endl; // 7derived if(typeid(b).before(typeid(*b))) cout << "b is before *b" << endl; else cout << "*b is before b" << endl; // rtti method2 derived *d = dynamic_cast<derived*>(d); if(d) cout << "cast successful" << endl; }
注意1:这里如果没有多态机制,则RTTI可能运行的结果不是我们想要的,比如如果没有虚函数,则这里两个都显示base,一般希望RTTI用于多态类。
注意2:运行时类型的识别对一个
void型指针不起作用。void *确实意味着“根本没有类型信息”。void *v = new stimpy; stimpy* s = dynamic_cast<stimpy*>(v); // error cout << typeid(*v).name() << endl; // error
- 第一种使用
-
RTTI的实现
典型的RTTI是通过在VTABLE中放一个额外的指针来实现的。这个指针指向一个描述该特定类型的typeinfo结构(每个新类只产生一个typeinfo的实例),所以typeid( )表达式的作用实际上很简单。VPTR用来取typeinfo的指针,然后产生一个结果typeinfo结构的一个引用—这是一个决定性的步骤—我们已经知道它要花多少时间。对于
dynamic_cast<目标* > <源指针>,多数情况下是很容易的,先恢复源指针的RTTI信息再取出目标*的类型RTTI信息,然后调用库中的一个例程判断源指针是否与目标*相同或者是目标*类型的基类。它可能对返回的指针做了一点小的改动,因为目的指针类可能存在多重继承的情况,而源指针类型并不是派生类的第一个基类。在多重继承时情况会变得复杂些,因为一个基类在继承层次中可能出现一次以上,并且可能有虚基类。
用于动态映射的库例程必须检查一串长长的基类列表,所以动态映射的开销比typeid()要大(当然我们得到的信息也不同,这对于我们的问题来说可能很关键),并且这是非确定性的,因为查找一个基类要比查找一个派生类花更多的时间。另外动态映射允许我们比较任何类型,不限于在同一个继承层次中比较两个类。这使得动态映射调用的库例程开销更高了。
映射类型 含义 static_cast 为了“行为良好”和“行为较好”而使用的映射,包括一些我们可能现在不用的映射(如向上映射和自动类型转换) const_cast 用于映射常量和变量(const和volatile) const_cast 为了安全类型的向下映射(本章前面已经介绍) reinterpret_cast 为了映射到一个完全不同的意思。这个关键词在我们需要把类型映射回原有类型时要用到它。我们映射到的类型仅仅是为了故弄玄虚和其他目的。这是所有映射中最危险的 注意:如果想把一个const 转换为非const,或把一个volatile转换成一个非volatile(勿遗忘这种情况),就要用到const_cast。这是可以用const_cast的唯一转换。如果还有其他的转换牵涉进来,它必须分开来指定,否则会有一个编译错误。
-