python multiprocessing多线程爬取并解析百度贴吧某贴小trick
preface:看极客学院关于xpath的视频时,偶然看到可以用multiprocessing进行多线程爬取网页,只有小段代码,故先贴出来。mark下。新增xpath提取网页内容,主要分析html文本,然后存为字典写到文件夹中。
参考极客学院的python并行化介绍与演示视频
coding:
#!/usr/bin/env python # coding=utf-8 from multiprocessing.dummy import Pool as ThreadPool import requests import time def getsource(url): html = requests.get(url) urls = [] for i in range(1,21): newpage = "http://tieba.baidu.com/p/3522395718?pn=" + str(i) urls.append(newpage)#构造url列表 time1 = time.time() for i in urls: print i getsource(i) time2 = time.time() print u"单线程耗时:"+str(time2-time1) pool = ThreadPool(4)#机器是多少核便填多少,卤煮实在ubuntu14.04 4核戴尔电脑上跑的程序 time3 = time.time() results = pool.map(getsource, urls) pool.close() pool.join() time4 = time.time() print u"并行耗时:"+str(time4-time3)
效果:
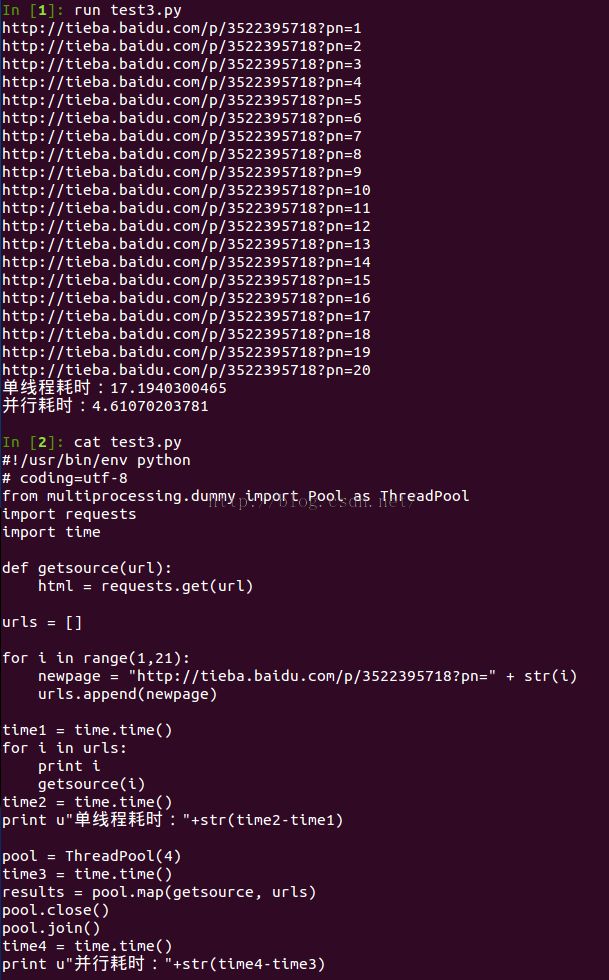
Figure 1-1: multiprocessing效果明显
可以看出,使用multiprocessing包对爬虫函数进行优化,其效果还是很明显的。另外,用requests包解析url时,未发生重定向问题,也是我比较意外的,以往卤煮写的没注意爬取访问时间被封掉ip。
xpath提取某贴回帖信息
极客学院网站视频:实战——百度贴吧爬虫-xpath与多线程爬虫
coding
#-*-coding:utf8-*- from lxml import etree from multiprocessing.dummy import Pool as ThreadPool import requests import json import sys reload(sys) sys.setdefaultencoding("utf-8") '''重新运行之前请删除content.txt,因为文件操作使用追加方式,会导致内容太多。''' def towrite(contentdict): f.writelines(u'回帖时间:' + str(contentdict['topic_reply_time']) + '\n') f.writelines(u'回帖内容:' + unicode(contentdict['topic_reply_content']) + '\n') f.writelines(u'回帖人:' + contentdict['user_name'] + '\n\n') def spider(url): html = requests.get(url) selector = etree.HTML(html.text) #主要解析html文件,用xpath表达式提取文本,存到字典中 # content_field = selector.xpath('//div[@class="l_post l_post_bright "]') content_field = selector.xpath('//div[@class="l_post j_l_post l_post_bright "]')#先抓大后抓小,这里改了 item = {} print len(content_field) for each in content_field: #print "==============" reply_info = json.loads(each.xpath('@data-field')[0].replace('"','')) author = reply_info['author']['user_name'] reply_time = reply_info['content']['date'] #print reply_time #print author content = each.xpath('div[@class="d_post_content_main"]/div/cc/div[@class="d_post_content j_d_post_content clearfix"]/text()')[0]#还有这里也改了 #print content item['user_name'] = author item['topic_reply_content'] = content item['topic_reply_time'] = reply_time towrite(item) if __name__ == '__main__': pool = ThreadPool(4) #机器为4核,故4个线程 f = open('content.txt','a')#主函数中并未直接f.write,而是通过spider函数,f作为全局变量传到towrite函数中实现写入文件 page = [] for i in range(1,21): newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i) page.append(newpage) results = pool.map(spider, page) pool.close() pool.join() f.close()
效果:

转载请认证:http://blog.csdn.net/u010454729/article/details/49765929