python urllib BeautifulSoup抓取去哪儿网站景点部分信息
preface: 最近一个同学需要收集去哪儿网的一些景点信息,爬虫上场。像是这么有规律的之间用urllib及BeautifulSoup这两个包就可破。实际上是我想少了。
一、抓取分析
http://piao.qunar.com/ticket/detail_1.html及http://piao.qunar.com/ticket/detail_1774014993.html分别为齐庐山和西海景区的两个景点。显然生成url:http://piao.qunar.com/ticket/detail_*.html,*为0到很大的数n。知道初始url,urllib就可破。
其次,分析提取的页面,同学想要景区名称、级别、地址、价格这四个主要的信息,网页另存html进行分析,发现其都在span标签中,结合BeautifulSoup包,提取可破。BeautifulSoup的教程很多,卤煮参考了博客:python爬虫入门八之Beautiful Soup的用法。文本在<p>标签中,不需要也就没提取。
二、抓取
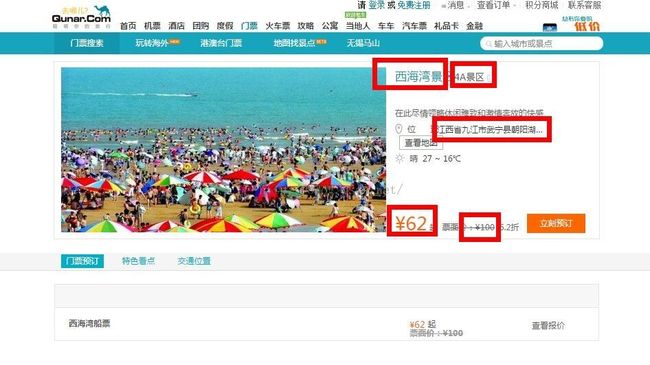
Figure 1-1: 主要信息
#!/usr/bin/env python # coding=utf-8 import bs4 from bs4 import BeautifulSoup import urllib import xlwt import time def crawl(html_string): # respons = urllib.urlopen(url) # soup = BeautifulSoup(respons.read()) soup = BeautifulSoup(html_string) name = "" level = "" address = "" money = "" #分析网页提取信息,这一部分需要熟悉beautifulsoup for tag in soup.find_all(["span"]): #利用beautifulsoup提取所有span标签 if "class" in tag.attrs: if "mp-description-name" in tag.attrs["class"]: #如果其class包含name,那么就是景区名称,下面同理 name = str(tag.string) if "mp-description-level" in tag.attrs["class"]: level = str(tag.string) if "mp-description-address" in tag.attrs["class"]: address = str(tag.string) else: for j in tag.children: #提取票价时,在span的子标签span中 if type(j) == bs4.element.Tag and j.name=="span": money = str(j.string) information = (address, name, level, money) return information #======python读入excel表初始化 book = xlwt.Workbook(encoding="utf-8",style_compression=0) sheet = book.add_sheet("where_we_go",cell_overwrite_ok=True) sheet.write(0,0,"景区地址") #第一行为四个属性名字,整个表为n行×4列,n为抓取到的景区个数 sheet.write(0,1,"景区名称") sheet.write(0,2,"景区级别") sheet.write(0,3,"景区票面价") start_time = time.time() line_num = 1 for i in xrange(0, 1000):#2500000000,最大2295597022 #有相当多的景区,这一点吓尿,n大的时候必须用xrange,用range生成一个列表太大崩溃。 url = "http://piao.qunar.com/ticket/detail_"+str(i)+".html" respons = urllib.urlopen(url) if respons.geturl()!=url: #抓取太快又会发生重定向的问题,重定向后的url网页显示“尊敬的用户,安全系统检测到异常访问,当前请求已经被拦截” print respons.geturl() html_string = respons.read() if "mp-description-detail" in html_string: #判断是否有这个网页,像是标号为0的,就没有,1为齐庐山,2为中国竹艺城等等, information = crawl(html_string) #进行抓取任务,返回四个主要属性值 for j in range(len(information)): sheet.write(line_num, j, information[j]) #写入excel表中。 line_num+=1 print "处理url:",i, information[1] if line_num%10==0: end_time = time.time() print "time:",end_time-start_time else: continue book.save("where.xls") #要吧excel进行保存
三、抓取遇到的问题
首先网页个数太多,n设置过大,必须要用xrange,迭代生成初始url。
其次,爬取的时候没有设置sleep,结果 爬取太快被检查到发生url重定向,提取不到景点信息。
再次,得到信息的过程太慢,5秒才爬到20个,平均1个需要0.25s,对于大规模网页爬取这样的速度是不可容忍的。同仁提醒用多线程爬取。没设置sleep也被封了。
再之,打算用scrapy框架爬取,用scrapy shell http://piao.qunar.com/ticket/detail_1774014993.html测试一下都被封掉,用scrapy继续不了。
四、多线程爬取
多线程爬取遇到的问题是存excel,存excel需要写入行号,需要返回值,后来发现在run()方法重写就行。不过也依然发生重定向问题。时间的设置比较关键。。
coding:
#!/usr/bin/env python # coding=utf-8 import bs4 from bs4 import BeautifulSoup import urllib import time import threading class MyThread(threading.Thread): def __init__(self, func, j): threading.Thread.__init__(self,target=func, args=j) #继承线程类 self.func = func self.j = j def run(self): print "starting:",self.j,self.func get_infor(self.j) #在run中调用get_infor函数 def crawl(html_string): soup = BeautifulSoup(html_string) name = "" level = "" address = "" money = "" for tag in soup.find_all(["span"]): if "class" in tag.attrs: if "mp-description-name" in tag.attrs["class"]: name = str(tag.string) if "mp-description-level" in tag.attrs["class"]: level = str(tag.string) if "mp-description-address" in tag.attrs["class"]: address = str(tag.string) else: for j in tag.children: if type(j) == bs4.element.Tag and j.name=="span": money = str(j.string) information = (address, name, level, money) return information def get_infor(j): n=50 for i in xrange(n): url = "http://piao.qunar.com/ticket/detail_"+str(i+j*n)+".html" respons = urllib.urlopen(url) if respons.geturl()!=url: print respons.geturl() continue html_string = respons.read() if "mp-description-detail" in html_string: information = crawl(html_string) print information[1] f = open("t.txt","a") #以追加的方式写入每个景点的四个属性值 s = "\t".join(information) #以"\t"隔开。 f.write(s+"\n") f.close() else: continue # return s def main(): threads = [] for j in range(50): #j为线程个数 t = MyThread(get_infor, j) #对每个函数都用一个线程,将所有的网页分为j份,每份为n threads.append(t) for t in threads: #start开始线程爬取 t.setDaemon(True) t.start() t.join() if __name__=="__main__": start_time = time.time() main() end_time = time.time() print "time:",end_time - start_time
五、scrapy尝试爬取
scrapy shell http://piao.qunar.com/ticket/detail_1774014993.html进入交互式终端,提取不出来。
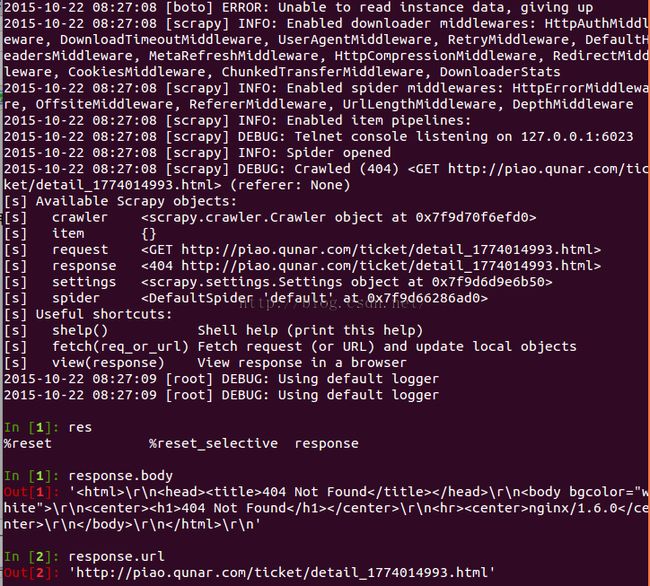
六、后续
爬虫往后还有更加深入的问题,怎么更快爬取而不被封掉,快速提取主要信息等等很多。同学又说stop,太慢了就不用爬了,其后试了多线程及scrapy后没继续。
参考:
有关urllib的博客:http://www.cnblogs.com/yuxc/archive/2011/08/01/2123995.html
使用scrapy建立一个网站抓取器:http://www.oschina.net/translate/build-website-crawler-based-upon-scrapy
scrapy抓取Logdown博文相关数据:http://dabing1022.github.io/2014/07/17/scrapy-crawling-logdown-blog-related-data/
转载请认证:http://blog.csdn.net/u010454729/article/details/49328681