openVswitch(OVS)源代码分析之工作流程(flow流表查询)
作者:庾志辉 完成时间:2014-9-25 00:43 原文地址:http://blog.csdn.net/yuzhihui_no1/article/details/39504139
前面分析了openVswitch几部分源代码,对于openVswitch也有了个大概的理解,今天要分析得代码将是整个openVswitch的重中之重。整个openVswitch的核心代码在datapath文件中;而datapath文件中的核心代码又在ovs_dp_process_received_packet(struct vport *p, struct sk_buff *skb);函数中;而在ovs_dp_process_received_packet(struct vport *p, struct sk_buff *skb);函数中的核心代码又是流表查询(流表匹配的);有关于ovs_dp_process_received_packet(struct vport *p, struct sk_buff *skb);核心代码的分析在前面的openVswitch(OVS)源代码分析之工作流程(数据包处理)中。今天要分析得就是其核心中的核心:流表的查询(匹配流表项)源代码。我分析源代码一般是采用跟踪的方法,一步步的往下面去分析,只会跟着主线走(主要函数调用),对其他的分支函数调用只作大概的说明,不会进入其实现函数去分析。由于流表的查询设计到比较多的数据结构,所以建议对照着openVswitch(OVS)源代码分析之数据结构去分析,我自己对数据结构已经大概的分析了遍,可是分析流表查询代码时还是要时不时的倒回去看看以前的数据结构分析笔记。
注:这是我写完全篇后补充的,我写完后自己阅读了下,发现如果就单纯的看源代码心里没有个大概的轮廓,不是很好理解,再个最后面的那个图,画的不是很好(我也不知道怎么画才能更好的表达整个意思,抱歉),所以觉得还是在这个位置(源代码分析前)先来捋下框架(也可以先看完源码分析再来看着框架总结,根据自己情况去学习吧)。上面已经说过了openVswitch(OVS)源代码分析之数据结构的重要性,现在把里面最后那幅图拿来顺着图示来分析,会更好理解。(最后再来说下那幅图是真的非常有用,那相当于openVswitch的整个框架图了,如果你要分析源代码,有了那图绝对是事半功倍,希望阅读源代码的朋友重视起来,哈哈,绝不是黄婆卖瓜)
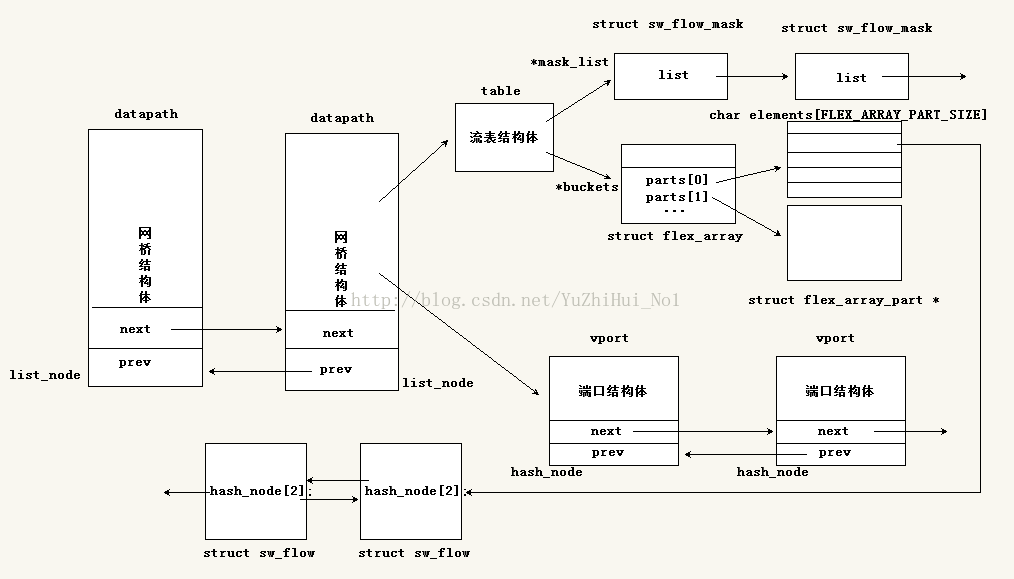
流表查询框架(或者说理论):从ovs_dp_process_received_packet(struct vport *p, struct sk_buff *skb)函数中开始调用函数查流表,怎么查呢?
第一步、它会根据网桥上的流表结构体(table)中的mask_list成员来遍历,这个mask_list成员是一条链表的头结点,这条链表是由mask元素链接组成(里面的list是没有数据的链表结构,作用就是负责链接多个mask结构,是mask的成员);流表查询函数开始就是循环遍历这条链表,每遍历到得到一个mask结构体,就调用函数进入第二步。
第二步、是操作key值,调用函数让从数据包提取到的key值和第一步得到的mask中的key值,进行与操作,然后把结构存放到另外一个key值中(masked_key)。顺序执行第三步。
第三步、把第二步中得到的那个与操作后的key值(masked_key),传入 jhash2()算法函数中,该算法是经典的哈希算法,想深入了解可以自己查资料(不过都是些数学推理,感觉挺难的),linux内核中也多处使用到了这个算法函数。通过这个函数把key值(masked_key)转换成hash关键字。
第四步、把第三步得到的hash值,传入 find_bucket()函数中,在该函数中再通过jhash_1word()算法函数,把hash关键字再次哈希得到一个全新的hash关键字。这个函数和第三步的哈希算法函数类似,只是参数不同,多了一个word。经过两个哈希算法函数的计算得到一个新的hash值。
第五步、 把第四步得到的hash关键字,传入到flex_array_get()函数中,这个函数的作用就是找到对应的哈希头位置。具体的请看上面的图,流表结构(table)中有个buckets成员,该成员称作为哈希桶,哈希桶里面存放的是成员字段和弹性数组parts[n],而这个parts[n]数组里面存放的就是所要找的哈希头指针,这个哈希头指针指向了一个流表项链表(在图中的最下面struct sw_flow),所以这个才是我们等下要匹配的流表项。(这个哈希桶到弹性数组这一段,我有点疑问,不是很清楚,在下一篇blog中会分析下这个疑问,大家看到如果和源代码有出入,请按源代码来分析),这一步就是根据hash关键字查找到流表项的链表头指针。
第六步、由第五步得到的流表项链表头指针,根据这个指针遍历整个流表项节点元素(就是struct sw_flow结构体元素),每遍历得到一个流表项sw_flow结构体元素,就把流表项中的mask成员和第一步遍历得到的mask变量(忘记了可以重新回到第一步去看下)进行比较;比较完后还要让流表项sw_flow结构体元素中的key值成员和第二步中得到的key值(masked_key)进行比较;只有当上面两个比较都相等时,这个流表项才是我们要匹配查询的流表项了。然后直接返回该流表项的地址。查询完毕!!接下来分析源代码了。
在ovs_dp_process_received_packet(struct vport *p, struct sk_buff *skb);函数中流表查询调用代码:
// ovs_flow_lookup()是流表查询实现函数;参数rcu_dereference(dp->table):网桥流表(不是流表项); // 参数&key:数据包各层协议信息提取封装的key地址;返回值flow:查询到的或者说匹配到的流表项 flow = ovs_flow_lookup(rcu_dereference(dp->table), &key);
这里要特别说明下:dp->table是流表,是结构体struct flow_table的变量;而flow是流表项,是结构体struct sw_flow的变量;我们平常习惯性说的查询流表或者匹配流表,其实并不是说查询或者匹配flow_table结构体的变量(在openVswitch中flow_table没有链表,只有一个变量),而是struct sw_flow的结构体链表。所以确切的说应该是查询和匹配流表项。这两个结构是完全不同的,至于具体的是什么关系,有什么结构成员,可以查看下openVswitch(OVS)源代码分析之数据结构。如果不想看那么繁琐的分析,也可以看下最后面的那张图,可以大概的了解下他们的关系和区别。
下面来着重的分析下ovs_flow_lookup()函数,主要是循环遍历mask链表节点,和调用ovs_masked_flow_lookup()函数。
// tbl是网桥结构中的table,key是包中提取的key的地址指针
struct sw_flow *ovs_flow_lookup(struct flow_table *tbl,
const struct sw_flow_key *key)
{
struct sw_flow *flow = NULL;// 准备流表项,匹配如果匹配到流表项则返回这个变量
struct sw_flow_mask *mask;// 了解mask结构就非常好理解mask的作用
// 下面是从网桥上的table结构中头mask_list指针开始遍历mask链表,
// 依次调用函数去查询流表,如果得到流表项则退出循环
list_for_each_entry_rcu(mask, tbl->mask_list, list) {
// 流表查询函数(其实是key的匹配),参数分别是:网桥的table,和数据包的key,以及网桥上的mask节点
flow = ovs_masked_flow_lookup(tbl, key, mask);
if (flow) /* Found */
break;
}
return flow;
}
接下来是flow = ovs_masked_flow_lookup(tbl, key, mask);函数的分析,该函数就是最后流表的比较了和查询了。主要实现功能是对key值得操作,和哈希得到哈希值,然后根据哈希值查找哈希头结点,最后在头结点链表中遍历流表项,匹配流表项。
// table 是网桥结构体中成员,flow_key是数据包提取到的key值,mask是table中的sw_flow_mask结构体链表节点
static struct sw_flow *ovs_masked_flow_lookup(struct flow_table *table,
const struct sw_flow_key *flow_key,
struct sw_flow_mask *mask)
{
// 要返回的流表项指针,其实这里就可以断定后面如果查询成功的话,返回的是存储flow的动态申请好的内存空间地址,
// 因为这几个函数都是返回flow的地址的,如果不是动态申请的地址,返回的就是局部变量,那后面使用时就是非法的了。
// 它这样把地址一层一层的返回;若查询失败返回NULL。因为这里不涉及到对流表的修改,只是查询而已,如果为了防止流表被更改,
// 也可以自己动态的申请个flow空间,存储查询到的flow结构。
struct sw_flow *flow;
struct hlist_head *head;// 哈希表头结点
// 下面是mask结点结构体中成员变量:struct sw_flow_key_range range;
// 而该结构体struct sw_flow_key_range有两个成员,分别为start和end
// 这两个成员是确定key值要匹配的范围,因为key值中的数据并不是全部都要进程匹配的
int key_start = mask->range.start;
int key_len = mask->range.end;
u32 hash;
struct sw_flow_key masked_key;// 用来得到与操作后的结果key值
// 下面调用的ovs_flow_key_mask()函数是让flow_key(最开始的数据包中提取到的key值),和mask中的key进行与操作(操作范围是
// 在mask的key中mask->range->start开始,到mask->range->end结束) 最后把与操作后的key存放在masked_key中
ovs_flow_key_mask(&masked_key, flow_key, mask);
// 通过操作与得到的key,然后再通过jhash2算法得到个hash值,其操作范围依然是 range->start 到range->end
// 因为这个key只有在这段范围中数据时有效的,对于匹配操作来说。返回个哈希值
hash = ovs_flow_hash(&masked_key, key_start, key_len);
// 调用find_bucket通过hash值查找hash所在的哈希头,为什么要查询链表头节点呢?
// 因为openVswitch中有多条流表项链表,所以要先查找出要匹配的流表在哪个链表中,然后再去遍历该链表
head = find_bucket(table, hash);
// 重点戏来了,下面是遍历流表项节点。由开始获取到哈希链表头节点,依次遍历这个哈希链表中的节点元素,
// 把每一个节点元素都进行比较操作,如果成功,则表示查询成功,否则查询失败。
hlist_for_each_entry_rcu(flow, head, hash_node[table->node_ver]) {
// 下面都是比较操作了,如果成功则返回对应的flow
if (flow->mask == mask &&
__flow_cmp_key(flow, &masked_key, key_start, key_len))
// 上面的flow是流表项,masked_key是与操作后的key值,
return flow;
}
return NULL;
}
分析到上面主线部分其实已经分析完了,但其中有几个函数调用比较重要,不得不再来补充分析下。也是按顺序依次分析下来,
第一个调用函数:ovs_flow_key_mask(&masked_key, flow_key, mask);分析。这个函数主要功能是让数据包中提取到的key值和mask链表节点中key与操作,然后把结果存储到masked_key中。
// 要分析一个函数除了看实现代码外,分析传入的参数和返回的数据类型也是非常重要和有效的
// 传入函数的参数要到调用该函数的地方去查找,返回值得类型可以在本函数内看到。
// 上面调用函数:ovs_flow_key_mask(&masked_key, flow_key, mask);
// 所以dst是要存储结构的key值变量地址,src是最开始数据包中提取的key值,mask是table中mask链表节点元素
void ovs_flow_key_mask(struct sw_flow_key *dst, const struct sw_flow_key *src,
const struct sw_flow_mask *mask)
{
u8 *m = (u8 *)&mask->key + mask->range.start;
u8 *s = (u8 *)src + mask->range.start;
u8 *d = (u8 *)dst + mask->range.start;
int i;
memset(dst, 0, sizeof(*dst));
// ovs_sw_flow_mask_size_roundup()是求出range->end - range->start长度
// 循环让最开始的key和mask中的key值进行与操作,放到目标key中
for (i = 0; i < ovs_sw_flow_mask_size_roundup(mask); i++) {
*d = *s & *m;
d++, s++, m++;
}
} 第二个调用函数:hash = ovs_flow_hash(&masked_key, key_start, key_len);这个没什么好分析得,只是函数里面调用了个jhash2算法来获取一个哈希值。所以这个函数的整体功能是:由数据包中提取到的key值和每个mask节点中的key进行与操作后得到的有效masked_key,和key值的有效数据开始位置及其长度,通过jhash2算法得到一个hash值。
第三个调用函数:head = find_bucket(table, hash);分析,该函数实现的主要功能是对hash值调用jhash_1word()函数再次对hash进行哈希,最后遍历哈希桶,查找对应的哈希链表头节点。
// 参数table:网桥上的流表;参数hash:由上面调用函数获取到哈希值;返回
static struct hlist_head *find_bucket(struct flow_table *table, u32 hash)
{
// 由开始的hash值再和table结构中自带的哈希算法种子通过jhash_1word()算法,再次hash得到哈希值
// 不知道为什么要哈希两次,我个人猜测是因为第一次哈希的值,会有碰撞冲突。所以只能二次哈希来解决碰撞冲突
hash = jhash_1word(hash, table->hash_seed);
// 传入的参数数:buckets桶指针,哈希值hash(相当于关键字)n_buckets表示有多少个桶(其实相当于有多少个hlist头结点)
// hash&(table->n_buckets-1)表示根据hash关键字查找到第几个桶,其实相当于求模算法,找出关键字hash应该存放在哪个桶里面
return flex_array_get(table->buckets,
(hash & (table->n_buckets - 1)));
}
第四个调用函数: __flow_cmp_key(flow, &masked_key, key_start, key_len));分析,该函数实现的功能是对流表中的key值和与操作后的key值(masked_key)进行匹配。
// 参数flow:流表项链表节点元素;参数key:数据包key值和mask链表节点key值与操作后的key值;
// 参数key_start:key值得有效开始位置;参数key_len:key值得有效长度
static bool __flow_cmp_key(const struct sw_flow *flow,
const struct sw_flow_key *key, int key_start, int key_len)
{
return __cmp_key(&flow->key, key, key_start, key_len);
}
//用数据包中提取到的key和mask链表节点中的key操作后的key值(masked_key)和流表项里面的key比较
static bool __cmp_key(const struct sw_flow_key *key1,
const struct sw_flow_key *key2, int key_start, int key_len)
{
return !memcmp((u8 *)key1 + key_start,
(u8 *)key2 + key_start, (key_len - key_start));
}
上面就是整个流表的匹配实现源代码的分析,现在来整理下其流程,如下图所示(图有点丑见谅):
到此流表查询就就算结束了,分析了遍自己也清晰了遍。
转载请注明作者和原文出处,原文地址:http://blog.csdn.net/yuzhihui_no1/article/details/39504139
分析得比较匆促,若有不正确之处,望大家指正,共同学习!谢谢!!!