Spark源码分析(一)作业提交
Spark架构
1、Standalone架构
- 整个集群分为 Master 节点和 Worker 节点,相当于 Hadoop 的 Master 和 Slave 节点。
- Master 节点上常驻 Master 守护进程,负责管理全部的 Worker 节点。
- Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 executors。
- Driver 官方解释是 “The process running the main() function of the application and creating the SparkContext”。Application 就是用户自己写的 Spark 程序(driver program),比如 WordCount.scala。如果 driver program 在 Master 上运行,比如在 Master 上运行,那么 SparkPi 就是 Master 上的 Driver。如果是 YARN 集群,那么 Driver 可能被调度到 Worker 节点上运行(比如上图中的 Worker Node 2)。
- 每个 Worker 上存在一个或者多个 ExecutorBackend 进程(一个application在一个Worker上只有一个ExecutorBackend )。每个进程包含一个 Executor 对象,该对象持有一个线程池,每个线程可以执行一个 task。
- 每个 application 包含一个 driver 和多个 executors,每个 executor 里面运行的 tasks 都属于同一个 application
- Worker 通过持有 ExecutorRunner 线程来控制 CoarseGrainedExecutorBackend 的启停
2、Spark on yarn架构

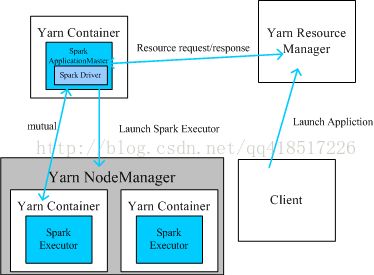
上图是yarn-client模式,下图是yarn-cluster模式
从深层次的含义讲,yarn-cluster和yarn-client模式的区别其实就是Spark Driver运行在哪的区别,yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。而yarn-client模式下,Client中运行Driver,在Client中能看到Application的运行信息,也就是说Client不能离开。
注意:本文以及后面的文章全是在standalone架构下分析的
作业提交
export HADOOP_CONF_DIR=/home/fw/hadoop-2.2.0/etc/hadoop $SPARK_HOME/bin/spark-submit --class cn.edu.hdu.threshold.Threshold \ --master yarn-client \ --num-executors 2 \ --driver-memory 4g \ --executor-memory 4g \ --executor-cores 4 \ /home/fw/Cluster2.jar
打开脚本spark-submit.sh,最后会发现调用的是org.apache.spark.deploy.SparkSubmit这个类
SparkSubmit.main
def main(args: Array[String]) {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
printStream.println(appArgs)
}
val (childArgs, classpath, sysProps, mainClass) = createLaunchEnv(appArgs)
launch(childArgs, classpath, sysProps, mainClass, appArgs.verbose)
}
先看createLaunchEnv方法
private[spark] def createLaunchEnv(args: SparkSubmitArguments)
: (ArrayBuffer[String], ArrayBuffer[String], Map[String, String], String) = {
if (args.master.startsWith("local")) {
clusterManager = LOCAL
} else if (args.master.startsWith("yarn")) {
clusterManager = YARN
} else if (args.master.startsWith("spark")) {
clusterManager = STANDALONE
} else if (args.master.startsWith("mesos")) {
clusterManager = MESOS
} else {
printErrorAndExit("Master must start with yarn, mesos, spark, or local")
}
......
(childArgs, childClasspath, sysProps, childMainClass)
}
该方法会读取提交上来的运行参数,判断是运行Standalone还是Spark on yarn,最后返回的childMainClass变量很重要。如果是Standalone架构则childMainClass为org.apache.spark.deploy.Client,如果是Spark on yarn架构则childMainClass为org.apache.spark.deploy.yarn.Client
接下来是launch方法
private def launch(
childArgs: ArrayBuffer[String],
childClasspath: ArrayBuffer[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean = false) {
......
val mainClass = Class.forName(childMainClass, true, loader)
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
try {
mainMethod.invoke(null, childArgs.toArray)
} catch {
case e: InvocationTargetException => e.getCause match {
case cause: Throwable => throw cause
case null => throw e
}
}
}
利用反射机制运行childMainClass
启动Client
Client.main
def main(args: Array[String]) {
......
// TODO: See if we can initialize akka so return messages are sent back using the same TCP
// flow. Else, this (sadly) requires the DriverClient be routable from the Master.
val (actorSystem, _) = AkkaUtils.createActorSystem(
"driverClient", Utils.localHostName(), 0, conf, new SecurityManager(conf))
actorSystem.actorOf(Props(classOf[ClientActor], driverArgs, conf))
actorSystem.awaitTermination()
}
}
咦?这三行代码什么?一开始看到这也懵了,后来一查才知道这是Spark使用了一个很经典的消息通信机制:Akka
下面是官方的例子:
//定义一个case class用来传递参数
case class Greeting(who: String)
//定义Actor,比较重要的一个方法是receive方法,用来接收信息的
class GreetingActor extends Actor with ActorLogging {
def receive = {
case Greeting(who) ⇒ log.info("Hello " + who)
}
}
//创建一个ActorSystem
val system = ActorSystem("MySystem")
//给ActorSystem设置Actor
val greeter = system.actorOf(Props[GreetingActor], name = "greeter")
//向greeter发送信息,用Greeting来传递
greeter ! Greeting("Charlie Parker")
我们再看Client.Main函数,它初始化了类ClientActor,它有两个方法preStart和receive,所有Actor都有这两个方法,第一个方法是初始化使用的,第二个方法是接受其他Actor发送过来的消息
ClientActor.preStart
override def preStart() = {
masterActor = context.actorSelection(Master.toAkkaUrl(driverArgs.master))
......
driverArgs.cmd match {
case "launch" =>
......
masterActor ! RequestSubmitDriver(driverDescription)
case "kill" =>
val driverId = driverArgs.driverId
val killFuture = masterActor ! RequestKillDriver(driverId)
}
}
1、动态代理获得Master的引用
2、参数配置及代码的封装
3、最后向master提交程序
启动Driver
Master.receive
override def receive = {
......
case RequestSubmitDriver(description) => {
if (state != RecoveryState.ALIVE) {
val msg = s"Can only accept driver submissions in ALIVE state. Current state: $state."
sender ! SubmitDriverResponse(false, None, msg)
} else {
logInfo("Driver submitted " + description.command.mainClass)
val driver = createDriver(description)
persistenceEngine.addDriver(driver)
waitingDrivers += driver
drivers.add(driver)
schedule()
// TODO: It might be good to instead have the submission client poll the master to determine
// the current status of the driver. For now it's simply "fire and forget".
sender ! SubmitDriverResponse(true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}")
}
}
1、将Driver封装成DriverInfor对象
2、再将Driver加入到相应的集合中
3、Master执行自己的调度机制
4、向Client返回Resonse
Master的调度机制我们也放到后面的章节
Master.launchDriver
def launchDriver(worker: WorkerInfo, driver: DriverInfo) {
logInfo("Launching driver " + driver.id + " on worker " + worker.id)
worker.addDriver(driver)
driver.worker = Some(worker)
worker.actor ! LaunchDriver(driver.id, driver.desc)
driver.state = DriverState.RUNNING
}
上述会通知Worer节点启动Driver
Worker.receive
override def receive = {
......
case LaunchDriver(driverId, driverDesc) => {
logInfo(s"Asked to launch driver $driverId")
val driver = new DriverRunner(driverId, workDir, sparkHome, driverDesc, self, akkaUrl)
drivers(driverId) = driver
driver.start()
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
}
......
}
DriverRunner.start会启动一个线程执行命令,通过ProcessBuilder类启动Driver进程,这是万里长征的第一步,之后还有初始化SparkContext、DAGScheduler、TaskScheduler等,将Application中的RDD划分成Stage,调度Tasks提交执行,这些会在之后的章节陆续展开
<原创,转载请注明出处http://blog.csdn.net/qq418517226/article/details/42711067>