Spark源码分析(五)调度管理3
接着上章的内容
CoarseGrainedExecutorBackend.DriverActor收到launchTask消息后(在第三章讲过,CoarseGrainedExecutorBackend是由AppClient向Master发送注册程序的消息,然后Master调度资源启动的),接下去的调用关系如下:
Executor.launchTask ThreadPool.executor(new TaskRunner)所有的Tasks都是放到线程池中去启动的,下面是TaskRunner.run方法
override def run() {
val startTime = System.currentTimeMillis()
SparkEnv.set(env)
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = SparkEnv.get.closureSerializer.newInstance()
logInfo("Running task ID " + taskId)
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var attemptedTask: Option[Task[Any]] = None
var taskStart: Long = 0
def gcTime = ManagementFactory.getGarbageCollectorMXBeans.map(_.getCollectionTime).sum
val startGCTime = gcTime
try {
......
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)//任务反序列化
......
val value = task.run(taskId.toInt)//ShuffleMapTask或者ResultTask的run方法
......
val directResult = new DirectTaskResult(valueBytes, accumUpdates,
task.metrics.getOrElse(null))//封装结果
val serializedDirectResult = ser.serialize(directResult)
val serializedResult = {
if (serializedDirectResult.limit >= execBackend.akkaFrameSize() -
AkkaUtils.reservedSizeBytes) {// 如果传输结果的大小超过akka的限定,则将结果存入BlockManager,否则直接返回结果
logInfo("Storing result for " + taskId + " in local BlockManager")
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId, serializedDirectResult, StorageLevel.MEMORY_AND_DISK_SER)
ser.serialize(new IndirectTaskResult[Any](blockId))
} else {
logInfo("Sending result for " + taskId + " directly to driver")
serializedDirectResult
}
}
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)// 执行结果返回
logInfo("Finished task ID " + taskId)
} catch {
......
}
}
} finally {
......
}
}
}
再分别看下ShuffleMapTask和ResultTask的run方法
override def ShuffleMapTask.runTask(context: TaskContext): MapStatus = {
......
val blockManager = SparkEnv.get.blockManager
val shuffleBlockManager = blockManager.shuffleBlockManager
var shuffle: ShuffleWriterGroup = null
var success = false
try {
// Obtain all the block writers for shuffle blocks.
val ser = Serializer.getSerializer(dep.serializer)
shuffle = shuffleBlockManager.forMapTask(dep.shuffleId, partitionId, numOutputSplits, ser)//获取写入shuffle文件的BlockObjectWriter
// Write the map output to its associated buckets.
for (elem <- rdd.iterator(split, context)) {//注意在这会调用RDD.iterator,pipeline的计算方式
val pair = elem.asInstanceOf[Product2[Any, Any]]
val bucketId = dep.partitioner.getPartition(pair._1)
shuffle.writers(bucketId).write(pair)
}
// Commit the writes. Get the size of each bucket block (total block size).
var totalBytes = 0L
var totalTime = 0L
val compressedSizes: Array[Byte] = shuffle.writers.map { writer: BlockObjectWriter =>//将每个结果的大小压缩
writer.commit()
writer.close()
val size = writer.fileSegment().length
totalBytes += size
totalTime += writer.timeWriting()
MapOutputTracker.compressSize(size)
}
......
new MapStatus(blockManager.blockManagerId, compressedSizes)
} catch { case e: Exception =>
......
} finally {
......
}
// Execute the callbacks on task completion.
context.executeOnCompleteCallbacks()
}
}ShuffleMapTask返回的MapStatus封装的是一个blockManagerId和每个shuffle文件的FileSegment的大小
override def ReslutTask.runTask(context: TaskContext): U = {
metrics = Some(context.taskMetrics)
try {
func(context, rdd.iterator(split, context))
} finally {
context.executeOnCompleteCallbacks()
}
}ResultTask直接返回结果
最后看下整个作业的执行流程,需要说明的是下面的过程是基于启动了Driver之后,关于怎样启动Driver我在第一章已经介绍过了
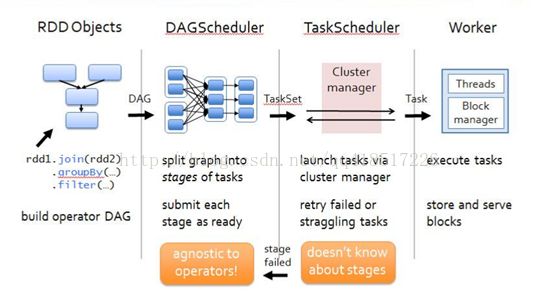
更多作业生命周期的介绍可以参考http://www.cnblogs.com/cenyuhai/p/3801167.html
返回Task执行结果
TaskRunner.run会返回计算结果,调用关系如下:
ExecutorBackend.statusUpdate SchedulerBackend.DriverActor.receive.StatusUpdate TaskScheduler.statusUpdate TaskResultGetter.enqueueSuccessfulTask
def enqueueSuccessfulTask(
taskSetManager: TaskSetManager, tid: Long, serializedData: ByteBuffer) {
getTaskResultExecutor.execute(new Runnable {
override def run(): Unit = Utils.logUncaughtExceptions {
try {
val result = serializer.get().deserialize[TaskResult[_]](serializedData) match {
case directResult: DirectTaskResult[_] => directResult
case IndirectTaskResult(blockId) =>//不是直接返回结果的情况,需要到远程BlockManager取数据
scheduler.handleTaskGettingResult(taskSetManager, tid)
val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId) ......
val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]](
serializedTaskResult.get)
sparkEnv.blockManager.master.removeBlock(blockId)
deserializedResult
}
scheduler.handleSuccessfulTask(taskSetManager, tid, result)
} catch {
......
}
}
})
}再接下去的调用关系:
TaskScheduler.handleSuccessfulTask TaskSetManager.handleSuccessfulTask DAGScheduler.taskEnded DAGScheduler.handleTaskComletion
private[scheduler] def handleTaskCompletion(event: CompletionEvent) {
......
listenerBus.post(SparkListenerTaskEnd(stageId, taskType, event.reason, event.taskInfo,
event.taskMetrics))//向ListenerBus发送Task事件
......
//返回的event有多种情况,其中Success是我们比较关心的,它分两种情况:ShuffleMapTask和ReslutTask
event.reason match {
case Success =>
logInfo("Completed " + task)
if (event.accumUpdates != null) {
// TODO: fail the stage if the accumulator update fails...
Accumulators.add(event.accumUpdates) // TODO: do this only if task wasn't resubmitted
}
pendingTasks(stage) -= task
task match {
case rt: ResultTask[_, _] =>
resultStageToJob.get(stage) match {
case Some(job) =>
if (!job.finished(rt.outputId)) {
job.finished(rt.outputId) = true
job.numFinished += 1
// If the whole job has finished, remove it
if (job.numFinished == job.numPartitions) {
markStageAsFinished(stage)
cleanupStateForJobAndIndependentStages(job, Some(stage))
listenerBus.post(SparkListenerJobEnd(job.jobId, JobSucceeded))
}
// taskSucceeded runs some user code that might throw an exception. Make sure
// we are resilient against that.
try {
job.listener.taskSucceeded(rt.outputId, event.result)
} catch {
case e: Exception =>
// TODO: Perhaps we want to mark the stage as failed?
job.listener.jobFailed(new SparkDriverExecutionException(e))
}
}
case None =>
logInfo("Ignoring result from " + rt + " because its job has finished")
}
case smt: ShuffleMapTask =>
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo("Ignoring possibly bogus ShuffleMapTask completion from " + execId)
} else {
stage.addOutputLoc(smt.partitionId, status)
}
if (runningStages.contains(stage) && pendingTasks(stage).isEmpty) {
markStageAsFinished(stage)
if (stage.shuffleDep.isDefined) {
// We supply true to increment the epoch number here in case this is a
// recomputation of the map outputs. In that case, some nodes may have cached
// locations with holes (from when we detected the error) and will need the
// epoch incremented to refetch them.
// TODO: Only increment the epoch number if this is not the first time
// we registered these map outputs.
mapOutputTracker.registerMapOutputs(
stage.shuffleDep.get.shuffleId,
stage.outputLocs.map(list => if (list.isEmpty) null else list.head).toArray,
changeEpoch = true)
}
clearCacheLocs()
if (stage.outputLocs.exists(_ == Nil)) {
// Some tasks had failed; let's resubmit this stage
// TODO: Lower-level scheduler should also deal with this
logInfo("Resubmitting " + stage + " (" + stage.name +
") because some of its tasks had failed: " +
stage.outputLocs.zipWithIndex.filter(_._1 == Nil).map(_._2).mkString(", "))
submitStage(stage)
} else {
val newlyRunnable = new ArrayBuffer[Stage]
for (stage <- waitingStages) {
logInfo("Missing parents for " + stage + ": " + getMissingParentStages(stage))
}
for (stage <- waitingStages if getMissingParentStages(stage) == Nil) {
newlyRunnable += stage
}
waitingStages --= newlyRunnable
runningStages ++= newlyRunnable
for {
stage <- newlyRunnable.sortBy(_.id)
jobId <- activeJobForStage(stage)
} {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which is now runnable")
submitMissingTasks(stage, jobId)
}
}
}
}
case Resubmitted =>
logInfo("Resubmitted " + task + ", so marking it as still running")
pendingTasks(stage) += task
case FetchFailed(bmAddress, shuffleId, mapId, reduceId) =>
......
case ExceptionFailure(className, description, stackTrace, metrics) =>
// Do nothing here, left up to the TaskScheduler to decide how to handle user failures
case TaskResultLost =>
// Do nothing here; the TaskScheduler handles these failures and resubmits the task.
case other =>
// Unrecognized failure - also do nothing. If the task fails repeatedly, the TaskScheduler
// will abort the job.
}
submitWaitingStages()
}1、ResultTask:JobWaiter.taskSucceeded,唤醒JobWaiter对象,同时DAGScheudler.runJob返回,我在第四章开始有讲。其实JobWaiter还封装了ResultTask的结果
2、ShuffleMapTask:首先将返回的MapStatus放入stage中,然后把stage的相关信息注册到MapOutputTracker中(Shuffle Read会从MapOutputTracker中取信息,主要是上个调度阶段的Shuffle文件存放在哪些node上),如果该stage的tasks运行完了则提交下一个stage
至此Spark程序运行的大体流程已经分析完了,还有很多细节比如BlockManager、Shuffle机制等在后面的章节会逐一分析
<原创,转载请注明出处http://blog.csdn.net/qq418517226/article/details/42711067>