Spark源码分析(六)存储管理1
背景
我们在编写Spark程序的时候常常需要与RDD打交道,通过RDD为我们提供的各种接口来实现我们的应用。RDD的引入提高了抽象层次,在接口和实现上进行了有效隔离,使用户无须关心底层的实现。但是,RDD提供给我们的仅仅是一个“形”,我们所操作的数据究竟放在哪里?如何存取?这个“体”是怎样的?数据的存放和管理都是由Spark的存储管理模块实现和管理的,在下面的内容我会详细介绍
存储管理模块整体架构
从架构上看存储管理模块主要分为以下两层
- 通信层:存储管理模块采用的是master-slave结构来实现通信层,master和slave之间传输控制信息状态信息
- 存储层:存储管理模块需要把数据存储到内存或磁盘中,必要时还需要复制到远端,这些操作由存储层来实现和提供相应接口
从功能上看存储管理模块又可以分为以下两个主要部分
- RDD缓存:整个存储管理模块主要的的工作是RDD的缓存,包括基于磁盘和内存的缓存
- Shuffle:Shuffle中间结果的存取也是交由存储管理模块进行管理的
通信层架构
首先我们看下通信层的UML类图,这里罗列了通信层中涉及的主要类,如下所示:
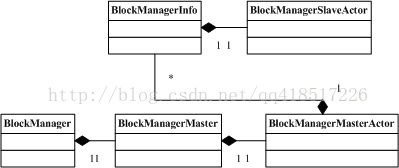
从类图可知,BlockManagerMasterActor和BlockManagerSlaveActor主要用作通信,BlockManager封装了很多需要用到的方法。
Spark会在Driver端和Executor端创建各自的BlockManager,通过BlockManager对存储管理模块进行操作
由于存储管理模块的通信层是master-slave架构,下图描述了通信层中各个类所扮演的角色
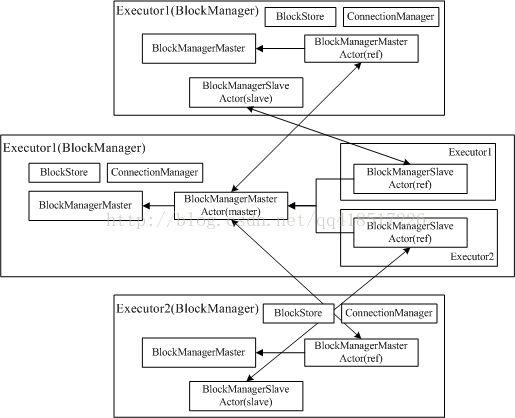
其中master的BlockManager包含了所有slave的BlockManager信息,便于master和slave相互通信
对于master和slave,BlockManager的创建有所不同:
- master(Driver):BlockManagerMaster拥有BlockManagerMasterActor的actor和BlockManagerSlaveActor的ref
- slave(Executor):BlockManagerMaster拥有BlockManagerMasterActor的ref和BlockManagerSlaveActor的actor
通信层消息的传递,可以看下BlockManagerMasterActor和BlockManagerSlaveActor的receive方法
注册存储管理模块
当BlockManager被创建出来后需要向Driver(master)进行注册,首先slave上的BlockManager会调用initialize()初始化自己
private def initialize() {
master.registerBlockManager(blockManagerId, maxMemory, slaveActor)//向master注册自己
BlockManagerWorker.startBlockManagerWorker(this)//启动BlockManagerWorker
if (!BlockManager.getDisableHeartBeatsForTesting(conf)) {
heartBeatTask = actorSystem.scheduler.schedule(0.seconds, heartBeatFrequency.milliseconds) {//设置心跳定时器
Utils.tryOrExit { heartBeat() }
}
}
}
向BlockManagerMasterActor发送消息注册自己,同时启动BlockManagerWorker和设置heartbeat定时器,定时发送心跳。可以看到在注册自身的时候向Driver传递了自身的slaveActor,Driver收到slaveActor以后会将与之对应的的BlockManagerInfo存储到hashmap,以便后续通过slaveActor向Executor发送消息
private def register(id: BlockManagerId, maxMemSize: Long, slaveActor: ActorRef) {
if (!blockManagerInfo.contains(id)) {
blockManagerIdByExecutor.get(id.executorId) match {
case Some(manager) =>
// A block manager of the same executor already exists.
// This should never happen. Let's just quit.
logError("Got two different block manager registrations on " + id.executorId)
System.exit(1)
case None =>
blockManagerIdByExecutor(id.executorId) = id
}
blockManagerInfo(id) =
new BlockManagerInfo(id, System.currentTimeMillis(), maxMemSize, slaveActor)
}
listenerBus.post(SparkListenerBlockManagerAdded(id, maxMemSize))
}
这个版本有点奇怪,Driver端初始化BlockManager的时候也会把自己的slaveActor注册进来,之前在网上找了些文章,它们的版本就不会,它们的源码在开始的时候有个判断,如果是在Driver端就不进行任何操作
存储层架构
我们已经知道RDD是由不同分区组成的,我们所进行的转换和执行操作都是在每一块独立的分区上各自进行的。而在存储管理模块你不,RDD又被视为由不同的数据块组成,对于RDD的存取是以数据块为单位(这儿的数据块和HDFS上的数据块不等价),本质上分区和数据块是等价的,只是看待的角度不同。同时,在Spark存储管理模块中存取数据的最小单位是数据块,所有的操作都是以数据块为单位的。对于数据块的存取涉及存储管理模块的存储层,下面我们看下存储曾的UML类图
- BlockStore:负责将数据在内存或磁盘存取,DiskStore还包含了DiskBlockObjectWriter,这个类一是为Shuffle写数据到磁盘,二是为MapPartitionRDD的外排
- DiskBlockManager:创建和维护逻辑Block和物理存储位置的关系
- ShuffleBlockManager:管理Shuffle文件的
- ConnectionManager:负责与其他计算节点建立连接,并负责数据的发送和接受
- BlockManagerWorker:监听远程的数据块存取请求并进行处理
数据块(Block)
存储管理模块中管理着各种不同的数据块,而这些数据块的表示主要是由类BlockId,这些数据块为Spark框架提供了不同的功能,下面我们将简单概述Spark存储管理模块中所管理的几种主要数据块
- RDD数据块:用来标记所缓存的RDD数据。RDD.iterator=>SparkEnv.get.cacheManager.getOrCompute()=>RDDBlockId,BlockManager.get(RDDBlockId)/put(RDDBlockId)
- Shuffle数据块:用来标识持久化的Shuffle数据。ShuffleMapTask=>ShuffleBlockManager.forMapTask=>ShuffleBlockId,BlockManager.getDiskWriter(ShuffleBlockId)
- 任务返回结果数据块:用来标识存储在存储管理模块内存的任务返回结果。Executor=>TaskResultBlockId,BlockManager.putBytes(TaskResultBlockId),当任务返回结果很大时,会引起Akka帧溢出,这时有种方案是将返回结果以块的形式放入存储管理模块,然后在Driver端获取该数据块即可,Driver端=>BlockManager.getRemoteBytes(TaskResultBlockId)
- 广播变量数据块:用来标识所存储的广播变量数据
参考:http://jerryshao.me/architecture/2013/10/08/spark-storage-module-analysis/
<原创,转载请注明出处http://blog.csdn.net/qq418517226/article/details/42711067>