《python爬虫实战》:模拟登陆
前面几篇博文基本上都是在不需要进行登陆的网页上面的进行内容的抓取。如果有的网页时需要我们先登陆后才能看到的,那么如果要爬取这些上面的网页的内容,就需要先模拟登陆,然后进行数据的抓取。这篇博文是自己学习的如何进行模拟登陆,将其记录下来。
本博文将其知乎网:http://www.zhihu.com为例。
第一步:获取知乎网首页的html源码
用简单的get方法来获取知乎网首页的html源码,实现代码如下:
#encoding=utf-8
#模拟登陆,以知乎网为例
import urllib2
import urllib
import re
class SimuLogin:
def __init__(self,url):
self.url=url
#爬取知乎首页的html源码
def getPageHtml(self):
user_agent="Mozilla /5.0 (Windows NT (6.1))"
headers={"User-Agent":user_agent}
request=urllib2.Request(self.url,headers=headers)
html=urllib2.urlopen(request)
print html.read() #测试输出
return html.read()
#测试
url=raw_input("input a url:")
sLogin=SimuLogin(url)
sLogin.getPageHtml()上面的代码与前几篇博文的代码一模一样,但是在我们爬取知乎网首页的html源码时,报错。报错如下:
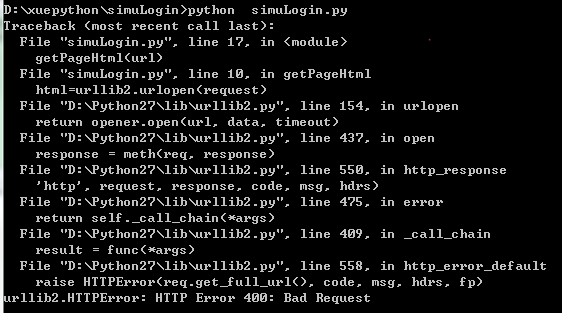
网上查资料,说是有可能是那个网站阻止了这类的访问,只要在请求中加上伪装成浏览器的header就可以了,但是以上的代码确实已经加上了请求头,居然报错,开始检查代码,看是否有自己写错的地方,发现没有,自己就写了自己写的第一个爬百度的html的代码,如下:
#encoding=utf-8
import urllib2
#response=urllib2.urlopen("http://www.xingjiakmite.com")
response=urllib2.urlopen("http://www.baidu.com")
print response.read()居然还是报相同的错,现在我都开始怀疑是我的环境有问题,实在是郁闷,找了半天的原因,最后的原因居然是:我把Fiddler 这个软件打开了,这个软件切断了我的所有爬虫的请求。
今天花了点时间,重新折腾了下关于这个模拟登陆,需要下面4个参数,但是只有_xsrf是需要我们在登陆首页获取的,因此,步骤如下:

1、首先获取要登陆页面的“_xsrf”的值
实现代码如下:
def getXSRF(data):
#<input type="hidden" name="_xsrf" value="e9d826c0fa34d68b3320d10c60df8588">
pattern= re.compile(r'<input type="hidden" name="_xsrf" value="(.*?)"',re.S)
strlist = re.findall(pattern,data)
print u"xsrf:"+strlist[0] #测试输出
return strlist[0]
url="http://www.zhihu.com/"
response=urllib2.urlopen(url)
#print response.read().decode("utf-8")
data=response.read()
_xsrf=getXSRF(data) #得到_xsrf,之后就可以模拟登陆了2、模拟浏览器并通过post来传送参数数据
实现代码如下:
header = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.zhihu.com',
'Dnt': '1'
}
#获取opener
def getopener(head):#接收一个head参数
#第一步:得到一个cookie实例对象来保存Cookie内容
cookie=cookielib.CookieJar()
#第二步:利用urllib2库中的HTTPCookieProcessor得到一个cookie的处理器
pro=urllib2.HTTPCookieProcessor(cookie)
#第三步:得到opener
opener=urllib2.build_opener(pro)
header=[]
for key,value in head.items():
elem=(key,value)
header.append(elem)
opener.addheaders=header
return opener
#模拟浏览器
opener=getopener(header)
url+="login/email"
id="[email protected]"
password="123456"
postDict={"_xsrf":_xsrf,
"email":id,
"password":password,
"rememberme":"true"
}
postData=urllib.urlencode(postDict).encode()
html=opener.open(url,postData)
print html.read()#
print html.info().get("Content-Encoding")到这里原以为就能够登陆成功,但是,还差一步,知乎现在有验证码,因此,还需要破解验证码之后才能登陆成功,下次来研究下怎么来获取验证码。
完整代码如下:
#encoding=utf-8
import urllib2
import urllib
import cookielib
import re
import gzip
#解压gzip包
def ungzip(data):
try: #尝试解压
print(u"解压中...")
data=gzip.decompress(data)
print(u"解压完成")
except:
print(u"未经压缩,无需解压")
return data
header = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.zhihu.com',
'Dnt': '1'
}
#获取opener
def getopener(head):#接收一个head参数
#第一步:得到一个cookie实例对象来保存Cookie内容
cookie=cookielib.CookieJar()
#第二步:利用urllib2库中的HTTPCookieProcessor得到一个cookie的处理器
pro=urllib2.HTTPCookieProcessor(cookie)
#第三步:得到opener
opener=urllib2.build_opener(pro)
header=[]
for key,value in head.items():
elem=(key,value)
header.append(elem)
opener.addheaders=header
return opener
def getXSRF(data):
#<input type="hidden" name="_xsrf" value="e9d826c0fa34d68b3320d10c60df8588">
pattern= re.compile(r'<input type="hidden" name="_xsrf" value="(.*?)"',re.S)
strlist = re.findall(pattern,data)
print u"xsrf:"+strlist[0] #测试输出
return strlist[0]
# response=urllib2.urlopen("http://www.xingjiakmite.com")
url="http://www.zhihu.com/"
response=urllib2.urlopen(url)
#print response.read().decode("utf-8")
data=response.read()
_xsrf=getXSRF(data) #得到_xsrf,之后就可以模拟登陆了
#模拟浏览器
opener=getopener(header)
url+="login/email"
id="[email protected]"
password="123456"
postDict={"_xsrf":_xsrf,
"email":id,
"password":password,
"rememberme":"true"
}
postData=urllib.urlencode(postDict).encode()
html=opener.open(url,postData)
print html.read()#到这里原以为就能够登陆成功,但是,还差一步,知乎现在有验证码,因此,还需要破解验证码之后才能登陆成功
print html.info().get("Content-Encoding")
#对数据进行解压
data=ungzip(html.read().decode())
print data小结
原以为用python进行模拟登陆会比较简单,经过自己尝试,发现还是有点不简单呀,到目前为止,还没有成功登陆,还有验证码这个问题没有解决,呜呜。最近由于新项目的启动,很忙,没有时间做这块了,呜呜。