HBase的三种操作方式
在《Hadoop 2.2.0和HBase 0.98.11伪分布式》中已经安装好了伪分布式的HBase,而且可以启动起来了。
执行hbase shell命令进入shell,出现SLF4J: Class path contains multiple SLF4J bindings.错误,将其中一个SLF4J删掉即可:
mv apple/hbase/lib/slf4j-log4j12-1.6.4.jar apple/hbase/lib/slf4j-log4j12-1.6.4.jar.bak
然后依次执行下表中的命令来测试HBase:
| 作用 | 命令 |
|---|---|
| 查看有哪些表 | list |
| 创建表test,只有一个data列族 | create 'test', 'data' |
| 插入数据 | put 'test', '2343', 'data:name', 'helo' |
| 扫描表 | scan 'test' |
| 禁用表 | disable 'test' |
| 删除表 | drop 'test' |
java API
通过java API来使用HBase。
先试试能不能建一个表。
import java.io.IOException;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.HColumnDescriptor;
public class Test {
public static void main(String[] args)
throws MasterNotRunningException, ZooKeeperConnectionException, IOException
{
Configuration conf = new Configuration();//从配置文件生成
HBaseAdmin admin = new HBaseAdmin(conf);
HTableDescriptor tableDesc = new HTableDescriptor("test");
tableDesc.addFamily(new HColumnDescriptor("info"));
admin.createTable(tableDesc);
}
}javac -cp $(hbase classpath) Test.java
java -cp .:$(hbase classpath) Test
这是我尝试了多次才给整对的,尤其是.:$(hbase classpath),如果没有那个点,会提示找不到类,就是不知道Test是什么东西。
带插入数据的。
import java.io.IOException;
import java.util.List;
import java.util.ArrayList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
public class Test {
public static void main(String[] args)
throws MasterNotRunningException, ZooKeeperConnectionException, IOException
{
String tableName = "test";
String familyName = "info";
//创建表
Configuration conf = new Configuration();
HBaseAdmin admin = new HBaseAdmin(conf);
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
tableDesc.addFamily(new HColumnDescriptor(familyName));
admin.createTable(tableDesc);
//单条插入
HTable table = new HTable(conf, tableName);
Put putRow = new Put("first".getBytes());
putRow.add(familyName.getBytes(), "name".getBytes(), "zhangsan".getBytes());
putRow.add(familyName.getBytes(), "age".getBytes(), "24".getBytes());
putRow.add(familyName.getBytes(), "city".getBytes(), "chengde".getBytes());
putRow.add(familyName.getBytes(), "sex".getBytes(), "male".getBytes());
table.put(putRow);
//多条插入
List<Put> list = new ArrayList<Put>();
Put p = null;
p = new Put("second".getBytes());
p.add(familyName.getBytes(), "name".getBytes(), "wangwu".getBytes());
p.add(familyName.getBytes(), "sex".getBytes(), "male".getBytes());
p.add(familyName.getBytes(), "city".getBytes(), "beijing".getBytes());
p.add(familyName.getBytes(), "age".getBytes(), "25".getBytes());
list.add(p);
p = new Put("third".getBytes());
p.add(familyName.getBytes(), "name".getBytes(), "zhangliu".getBytes());
p.add(familyName.getBytes(), "sex".getBytes(), "male".getBytes());
p.add(familyName.getBytes(), "city".getBytes(), "handan".getBytes());
p.add(familyName.getBytes(), "age".getBytes(), "28".getBytes());
list.add(p);
p = new Put("fourth".getBytes());
p.add(familyName.getBytes(), "name".getBytes(), "liqing".getBytes());
p.add(familyName.getBytes(), "sex".getBytes(), "female".getBytes());
p.add(familyName.getBytes(), "city".getBytes(), "guangzhou".getBytes());
p.add(familyName.getBytes(), "age".getBytes(), "18".getBytes());
list.add(p);
table.put(list);
}
}attention:单条插入时,所有列的时间戳都是一样的;多条插入时,多行数据的所有列的时间戳也都是一样的。
其他API见参考文献。
mr程序操作HBase
对前边的wordcount进行改进,将结果存储到HBase上,先来看代码。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends TableReducer<Text, IntWritable, Put> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
Put putrow = new Put(key.toString().getBytes());
putrow.add("info".getBytes(), "name".getBytes(),result.toString().getBytes());
context.write(null, putrow);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = HBaseConfiguration.create();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
TableMapReduceUtil.initTableReducerJob("test", IntSumReducer.class, job);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}javac -cp $(hbase classpath) -d temp WordCount.java
jar -cvf sort.jar -C temp .
然后运行MapReduce程序,参考文献中有两种运行的方法,这里选用第2种。打开hbase-env.sh,line 32左右,将其改为:
export HBASE_CLASSPATH=/home/tom/sort.jar$HBASE_CLASSPATH
因为$HBASE_CLASSPATH本身末尾就带了个冒号,这种写法把sort.jar放到了$HBASE_CLASSPATH后面,所以没问题。
然后执行
hbase WordCount /input/
现在至少这个mr程序可以运行了,细节稍后描述。
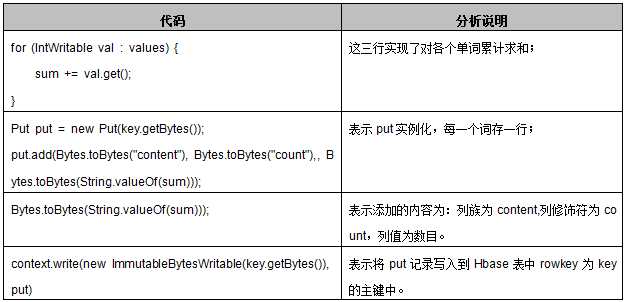
在main函数里新建表而不是用已存在的表:
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
public static void main(String[] args) throws Exception {
String tablename = "wordcount";
Configuration conf = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(conf);
if(admin.tableExists(tablename)) {
System.out.println("table exists!recreating.......");
admin.disableTable(tablename);
admin.deleteTable(tablename);
}
HTableDescriptor htd = new HTableDescriptor(tablename);
HColumnDescriptor tcd = new HColumnDescriptor("info");
htd.addFamily(tcd);//创建列族
admin.createTable(htd);//创建表
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 1) {
System.err.println("Usage: WordCountHbase <in>");
System.exit(2);
}
Job job = new Job(conf, "WordCountHbase");
job.setJarByClass(WordCount.class);
//使用TokenizerMapper类完成Map过程;
job.setMapperClass(TokenizerMapper.class);
TableMapReduceUtil.initTableReducerJob(tablename, IntSumReducer.class, job);
//设置任务数据的输入路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//调用job.waitForCompletion(true) 执行任务,执行成功后退出;
System.exit(job.waitForCompletion(true) ? 0 : 1);
}过时的API
几乎所有的程序编译时都提示了
注: *.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation重新编译。
因为我使用了过时的API,但我现在不知道新的API是什么,怎么写,以后再说。
参考文献
HBase 常用Shell命令
http://www.cnblogs.com/nexiyi/p/hbase_shell.html
Hbase Java API详解
http://www.cnblogs.com/tiantianbyconan/p/3557571.html
如何执行hbase的mapreduce job
http://blog.csdn.net/xiao_jun_0820/article/details/28636309
如何用MapReduce程序操作hbase
http://blog.csdn.net/liuyuan185442111/article/details/45306193