Hadoop 1.2.1分布式集群搭建
| 项目 | 详细 |
|---|---|
| 集群规模 | 3 |
| 主节点命名 | master |
| 从节点命名 | salve1,slave2 |
| 宿主机环境 | Window 7 Ultimate SP1 |
| 虚拟机版本 | VirtualBox-4.3.10-92957-Win.exe |
| master操作系统 | CentOS-6.5-i386-LiveCD.iso |
| master存储 | 1G内存,24G硬盘 |
| slave操作系统 | CentOS-6.5-i386-minimal |
| slave存储 | 512M内存,20G硬盘 |
| jdk版本 | jdk-8u25-linux-i586.rpm |
| hadoop版本 | hadoop-1.2.1-bin.tar.gz |
解压好的Hadoop就处于单机模式,此时输入输出目录都为本机文件系统。
所谓伪分布式模式不过是集群节点数量为0。
因此这里直接说明Hadoop完全分布式模式的配置。
master节点的系统设置
1.建立一个用户
建立一个普通用户来进行日常操作:
useradd tom
passwd tom
2.关闭防火墙和SELinux
为研究方便,关闭系统防火墙。
在一般情况下,我们不需要SELinux复杂的保护,所以将其设置为无效的状态。
关闭防火墙:
service iptables stop
service ip6tables stop
chkconfig iptables off
chkconfig ip6tables off关闭SELinux:
修改/etc/sysconfig/selinux
SELINUX=enforcing
↓
SELINUX=disabled接着执行如下命令
setenforce 0
getenforce
3.修改hostname和hosts
- 将/etc/sysconfig/network內的HOSTNAME改成master,下次启动时hostname就会更改为master;
- 执行”hostname master”命令,临时修改hostname为master;
- 用exit命令退出shell,再次登录。
在/etc/hosts文件中,添加以下三行内容(IP视具体情况而定):
192.168.1.131 master
192.168.1.132 slave1
192.168.1.133 slave24.开启sshd服务
系统安装好之后,如果没有开启sshd服务,则将其开启:
service sshd start
chkconfig sshd on
5.设置ssh免密码登录
切换到tom用户,执行以下命令生成密钥对:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
ssh-keygen代表生成密钥;-t表示指定生成的密钥类型;-P用于提供密语;-f指定生成的密钥文件。
这个命令会在.ssh文件夹下创建id_dsa及id_dsa.pub两个文件,这是一对私钥和公钥,把id_dsa.pub(公钥)追加到授权的key中去。
ssh-copy-id master
此命令将id_dsa.pub内容添加到~/.ssh/authorized_keys的末尾。
6.关闭不需要的服务
使用下面命令进行关闭不需要的服务:
for SERVICES in bluetooth cpuspeed mdmonitor postfix udev-post; do chkconfig ${SERVICES} off; done
注意:haldaemon和messagebus不要关闭,关闭后键盘鼠标无响应。
查看已开启服务:
chkconfig --list | grep "3:on"
slave节点的系统配置
1.同master节点的设置
新建用户tom
关闭防火墙,关闭SELinux,关闭不需要的服务
修改hostname和hosts文件
2.网络连接问题
网卡接口关闭与激活:
ifdown eth0 #关闭网络
ifup eth0 #启动网络
设置网卡开机启动:
编辑/etc/sysconfig/network-scripts/ifcfg-eth0
onboot=yes
3.复制另一个slave
在做完系统配置,安装配置完jdk和hadoop后,我使用virtualbox的复制功能,复制另一个slave节点,注意需要更改其网络地址。但是在复制的slave2上执行ifup eth0后提示:device eth0 does not seem to be present, delaying initialization。
解决方法如下:
1. 将/etc/sysconfig/network-scripts/ifcfg-eth0里的MAC地址一行删掉
2. 删除/etc/udev/rules.d/70-persistent-net.rules
3. 重启机器
4.使master可以无密码登录slave
这个操作是在master端执行的,将生成的公钥添加到authorized_keys中,并将authorized_keys上传到slave的.ssh中。
scp ./.ssh/authorized_keys slave1:~/.ssh/
scp ./.ssh/authorized_keys slave2:~/.ssh/
安装jdk
1.rpm方式安装
先从oracle网站下载jdk-8u25-linux-i586.rpm,执行以下命令安装jdk:
rpm -ivh jdk-8u25-linux-i586.rpm
所有文件安装于“/usr/java”目录下,其目录结构如下:

default指向实际的jdk目录,jdk版本升级时,只需要修改default即可,无需做其他改动。
另外安装程序在/usr/bin下创建了几个链接:
2.添加Java环境变量
在“/etc/profile”文件的尾部添加以下内容:
# set java environment
export JAVA_HOME=/usr/java/default
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin执行下面命令使其配置立即生效:
source /etc/profile
注意,source只对当前用户有效,所以需要先切换到tom用户再执行。
安装Hadoop 1.2.1
1.源码方式安装
先下载hadoop-1.2.1-bin.tar.gz,然后进行安装:
su -
mv hadoop-1.2.1-bin.tar.gz /usr/
cd /usr/
tar -zxvf hadoop-1.2.1-bin.tar.gz
mv hadoop-1.2.1 hadoop
chown -R tom:tom hadoop2.加入环境变量
在“/etc/profile”末尾添加:
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin使配置生效:
source /etc/profile
安装jdk和hadoop的总结
执行以下命令:
su -
rpm -ivh jdk-8u25-linux-i586.rpm
mv hadoop-1.2.1-bin.tar.gz /usr/
cd /usr/
tar -zxvf hadoop-1.2.1-bin.tar.gz
mv hadoop-1.2.1 hadoop
chown -R tom:tom hadoop在实践中我发现前两节中有些环境变量不是必须配置的,最终在“/etc/profile”末尾添加这些即可:
# java and hadoop environment
export CLASSPATH=.:/usr/java/default/jre/lib/rt.jar:/usr/java/default/lib/dt.jar:/usr/java/default/lib/tools.jar
export PATH=$PATH:/usr/java/default/bin:/usr/hadoop/bin然后使配置生效:
source /etc/profile
配置Hadoop
Hadoop配置文件在conf目录下,由于Hadoop发展迅速,代码量急剧增加,代码开发分为了core,hdfs和map/reduce三部分,配置文件也被分成了三个core-site.xml、hdfs-site.xml、mapred-site.xml。core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
1.配置hadoop-env.sh
hadoop-env.sh里定义了hadoop特定的环境变量,将第9行改为:
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
↓
export JAVA_HOME=/usr/java/default2.配置core-site.xml
core-site.xml是核心配置文件,这里配置的是HDFS的地址和端口号。
先在/usr/hadoop目录下建立tmp文件夹,作为hadoop的临时目录。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
3.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<configuration>4.配置mapred-site.xml
配置的是JobTracker的地址和端口。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
</configuration>5.配置masters
master
masters这个文件配置的是SecondaryNameNode的地址,slave节点其实不需要这个配置文件。
6.配置slaves
slave01
slave02
7.slave节点
将这6个配置文档覆盖salve1和slave2的配置文档。
8.启动及验证
1)格式化HDFS文件系统
只需一次,下次启动不再需要格式化。
hadoop namenode -format
2)启动hadoop
start-all.sh
3)验证hadoop
验证方式一:用“jps”命令
验证方式二:用“hadoop dfsadmin -report”
用这个命令可以查看Hadoop集群的状态。
验证方式三:通过web接口查看
通过浏览器访问master:500030和master:500070可浏览到MapReduce和namenode的页面。
4)关闭hadoop
stop-all.sh
执行一个wordcount
将两个本地的文件拷贝到hdfs上,调用hadoop示例程序wordcount对其进行单词统计。
echo “hello world” > file01
echo “hello hadoop” > file02
hadoop fs -mkdir input
hadoop fs -copyFromLocal ./file0* input
hadoop jar /usr/hadoop/hadoop-examples-1.2.1.jar wordcount input output
hadoop fs –cat user/root/output/part-r-00000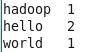
本文来自:http://blog.csdn.net/liuyuan185442111
参考文献
1.RHEL/CentOS 6.x系统服务详解
http://www.ha97.com/4815.html
2.Hadoop集群(第1期)_CentOS安装配置
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503770.html
3.不要关闭:haldaemon和messagebus服务,鼠标和键盘会没反应
http://www.linuxsir.org/bbs/thread340711.html
4.device eth0 does not seem to be present, delaying initialization
http://blog.sina.com.cn/s/blog_77126fa501018s3d.html
5.Hadoop集群(第5期)_Hadoop安装配置
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
6.centOS下单机配置hadoop攻略
http://blog.sina.com.cn/s/blog_6641cdab01018hy8.html
7.《Hadoop实战》P32”一个具体的配置”
http://www.linuxidc.com/Linux/2013-08/88600.htm
8.深入理解Linux修改hostname
http://www.cnblogs.com/kerrycode/p/3595724.html