结巴包的使用自己探究【总共5点】
Python进行分词的各种调试:
1.分词
第一步,最原始的分词法,jieba.cut 分词目标:从txt中导入语言,然后用结巴分词
import jieba
f=open('d://shuju.txt','r')
test_sent=f.read()
words=jieba.cut(test_sent)
print('/'.join(words))
.join的方法在Python基础教程里面有说明,是根据切分的地方加上前面想加的东西【这里为/】
第一步得出的答案如下:

我们可以发现,有一些词分错了。比如:改变传统 本来应该是两个词,被分成一个词了 大数据本来是一个词,却被分为两个词了 大/数据
接下来第二步:添加自定义词典
2.自定义字典
函数:jieba.load_userdict(filename) 是加载一个词典的。词典里面可以写三个,词,词性,
添加之后,还可以动态修改词典,用add和del
代码如下 中间空格处是添加的代码:
import jieba
jieba.load_userdict('d://userdict.txt') #载入自定义词典
import jieba.posseg as pseg
#这个词典里可以是以前就有的,可以是空的然后我们继续加
jieba.add_word('大数据')
f=open('d://shuju.txt','r')
test_sent=f.read()
words=jieba.cut(test_sent)
print('/'.join(words))
这时候再run,发现,大数据那个词,已经被成功的分为一个词了

接下来,把 改变传统 分成两个词,方法:suggest_freq(segment,True)
import jieba
jieba.load_userdict('d://userdict.txt') #载入自定义词典
import jieba.posseg as pseg
#这个词典里可以是以前就有的,可以是空的然后我们继续加
jieba.add_word('大数据')
jieba.suggest_freq(('改变','传统'),tune=True)
f=open('d://shuju.txt','r')
test_sent=f.read()
words=jieba.cut(test_sent)
print('/'.join(words))把改变,和传统用两个词写出来,还要加一个小括号!然后此时,设为True,代表能分开。这时候,改变传统 就能分为改变/传统
【P.S.:我试了想把改变传统用回一个词,但是改成false没成功,还是被分为两个词,所以如果想分回来改变传统,方法就是“把那个改变传统的两个字节符分开,然后还是用True】
3.关键词提取
jieba.analyse.extract_tags(sentence,topK=你想返回最大几个关键词,withWeight=False/True返回这些关键词的权重值,allowPOS仅包括指定词性的词)
代码:
import jieba
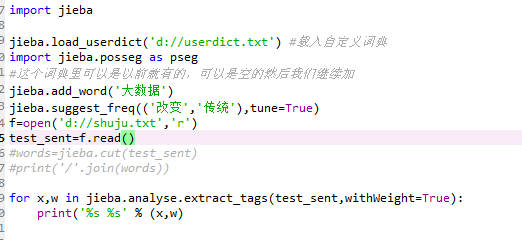
jieba.load_userdict('d://userdict.txt') #载入自定义词典
import jieba.posseg as pseg
#这个词典里可以是以前就有的,可以是空的然后我们继续加
jieba.add_word('大数据')
jieba.suggest_freq(('改变','传统'),tune=True)
f=open('d://shuju.txt','r')
test_sent=f.read()
#words=jieba.cut(test_sent)
#print('/'.join(words))
for x,w in jieba.analyse.extract_tags(test_sent,withWeight=True):
print('%s %s' % (x,w)) #这个print的用法是,用% 后面括号里的()第一个值x,替换第一个%s 第二个值w,替换第二个%s得到的结果如下:

4.词性标注
倘若不用jieba.cut 而是用jieba.posseg那个,即pseg的话 ,是不仅可以分词,还可以看到每个词的词性
result=pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
5.并行处理
这个仅在Linux系统上使用。Windows上面用不了