Python正则表达式,re模块
1.re.split 会根据模式的匹配项来分割字符串
[, ]代表了逗号或空格,如果以这个作为分割的话,实验如下:
import re
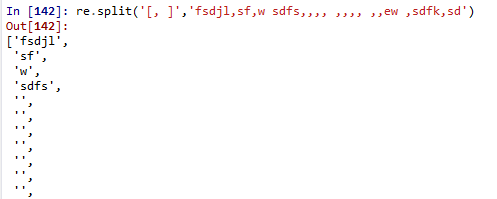
我发现,当用了[, ]这个时,它的确可以根据空格【或】逗号来进行分割,但是,当遇到多个空格和逗号连续出现的时候,就不行了。
因此,方法是在[, ]后面加一个+加号。代表重复1-无限次。
这样,便成功了。
2.re. findall以列表【list】形式返回给定模式的所有匹配项
比如,要在字符串中查找所有单词,可以像下面这么做:
>>> import re >>> pat = '[a-zA-Z]+'
>>> text = '"Hm...err -- are you sure?" he said, sounding insecure.'
>>> re.findall(pat,text) ['Hm', 'err', 'are', 'you', 'sure', 'he', 'said', 'sounding', 'insecure']
3.re.sub的作用在于:使用给定的替换内容将匹配模式的子符串(最左端并且重叠子字符串)替换掉。
>>> import re >>> pat = '{name}' >>> text = 'Dear {name}...' >>> re.sub(pat, 'Mr. Gumby',text) 'Dear Mr. Gumby...'
如果字符串很长且包含很多特殊字符,而你又不想输入一大堆反斜线,可以使用这个函数:
>>> re.escape('www.python.org') 'www\\.python\\.org' >>> re.escape('but where is the ambiguity?') 'but\\ where\\ is\\ the\\ ambiguity\\?'
匹配对象和组
简单来说,组就是放置在圆括号里内的子模块,组的序号取决于它左侧的括号数。组0就是整个模块,所以在下面的模式中:
‘There (was a (wee) (cooper)) who (lived in Fyfe)’
包含组有:
0 There was a wee cooper who lived in Fyfe
1 was a wee cooper
2 wee
3 cooper
4 lived in Fyfe
re 匹配对象的重要方法

下面看实例:
>>> import re >>> m = re.match(r'www\.(.*)\..{3}','www.python.org') >>> m.group() 'www.python.org' >>> m.group(0) 'www.python.org' >>> m.group(1) 'python' >>> m.start(1) 4 >>> m.end(1) 10 >>> m.span(1) (4, 10)
group方法返回模式中与给定组匹配的字符串,如果没有组号,默认为0 ;如上面:m.group()==m.group(0) ;如果给定一个组号,会返回单个字符串。
start 方法返回给定组匹配项的开始索引,
end方法返回给定组匹配项的结束索引加1;
span以元组(start,end)的形式返回给组的开始和结束位置的索引。
----------------------------