spark spark streaming + kafka receiver方式消费消息
kafka + spark streaming 集群
前提:
spark 安装成功,spark 1.6.0
zookeeper 安装成功
kafka 安装成功
步骤:
在worker1中启动kafka 生产者:
root@worker1:/usr/local/kafka_2.10-0.9.0.1# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test

在worker2中启动消费者:
root@worker2:/usr/local/kafka_2.10-0.9.0.1# bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test

生产者生产的消息,消费者可以消费到。说明kafka集群没问题。进入下一步。
在master中启动spark-shell
./spark-shell --master local[2] --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0
笔者用的spark 是 1.6.0 ,读者根据自己版本调整。
shell中的逻辑代码(wordcount):
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Durations, StreamingContext}
val ssc = new StreamingContext(sc, Durations.seconds(5))
// 第二个参数是zk的client host:port
// 第三个参数是groupID
KafkaUtils.createStream(ssc, "master:2181,worker1:2181,worker2:2181", "StreamingWordCountSelfKafkaScala", Map("test" -> 1)).map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start
生产者再生产消息:

spark streaming的反应:
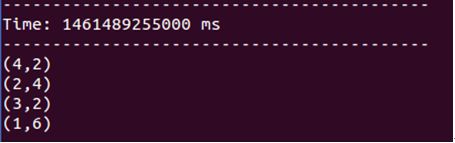
返回worker2查看消费者

可见,groupId不一样,相互之间没有互斥。
上述是使用 createStream 方式链接kafka
还有更高效的方式,请使用createDirectStream
参考:
http://spark.apache.org/docs/latest/streaming-kafka-integration.html
感谢王家林老师的知识分享
王家林老师名片:
中国Spark第一人
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
YY课堂:每天20:00现场授课频道68917580
王家林:DT大数据梦工厂创始人、Spark亚太研究院院长和首席专家、大数据培训专家、大数据架构师。
Spark、Flink、Docker、Android技术中国区布道师。
国内最早一批从事Android、Hadoop、Spark、Docker的研究者,在Spark、Hadoop、Android、Docker等方面有丰富的源码、实务和性能优化经验。是该领域的知名咨询顾问、培训专家;
Spark最佳畅销书《大数据spark企业级实战》和《Spark大数据实例开发教程》作者;
Android移动互联网兴起以来,近10本的IT畅销书作者;
为大量企业进行技术培训和服务,包括:
三星、惠普、爱立信、摩托罗拉、索尼、华为、夏普、南方航空公司、中国国际航空公司、金立、海信、长虹、英特尔、阿尔法特、中国联通、华三、AIA、亿迅、中国电信、网龙、福赛、中国人寿、阳光保险、兴业银行等。
找我报名有会员价哦。