【算法系列 四】 String
1. 字符串循环左移(九度OJ1362),要求时间复杂度O(N),空间复杂度O(1)
这是一道基本的题目,简单说来就是三次翻转
比如:abcdef 左移两位 cdefab
过程:
ab 翻转 ba
cdef 翻转 fedc
将上面两个翻转后的结果拼接 bafedc
再翻转cdefab得到结果
代码:
import java.io.IOException;
import java.util.Scanner;
public class Main
{
public static void main(String[] args) throws IOException
{
Scanner cin = new Scanner(System.in);
int N;
String str;
while (cin.hasNext())
{
str = cin.next();
N = cin.nextInt();
N = N % str.length();
String a = str.substring(0, N);
String b = str.substring(N);
StringBuffer abuffer = new StringBuffer(a);
StringBuffer bbuffer = new StringBuffer(b);
StringBuffer areverse = abuffer.reverse();
StringBuffer breverse = bbuffer.reverse();
StringBuffer creverse = areverse.append(breverse);
System.out.println(creverse.reverse().toString());
}
}
} 另外:循环左移K位等价于循环右移n-K位
2. 完美洗牌算法,要求时间复杂度O(N),时间复杂度O(1)
将{a1,a2,a3,...,an,b1,b2,b3,...,bn}变成{a1,b1,a2,b2,a3,b3,...,an,bn}
0、朴素的想法:记录一半的数据,依次重新插入。显然空间复杂度是O(N)。需要做点“高级”的分析。
1、题目要求空间复杂度为O(1),显然除了固定数目的临时变量不能额外开辟内存。这个要求变相的告诉我们:只能在原始数组上就地整理,不能新申请数组。
2、对原始位置的变化做如下分析:
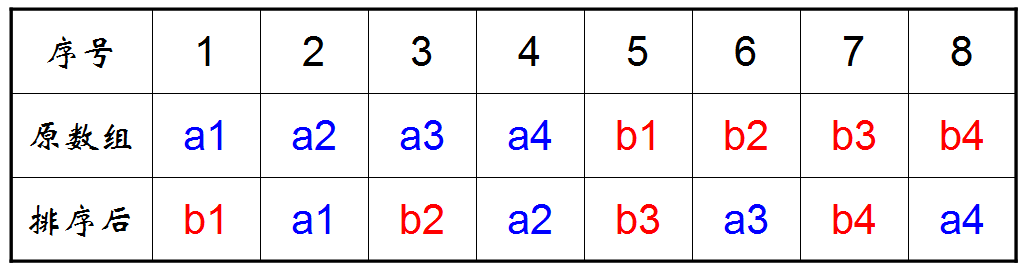
依次kao察每个位置的变化规律:
a1:1 -> 2
a2:2 -> 4
a3:3 -> 6
a4:4 -> 8
b1:5 -> 1
b2:6 -> 3
b3:7 -> 5
b4:8 -> 7
2.1、立刻可以发现变化规律:
对于原数组位置i的元素,新位置是(2*i)%(2n+1),注意,这里用2n表示原数组的长度。后面依然使用该表述方式。
2.2、有了该表达式:i' = (2*i)%(2n+1),困难的不是寻找元素在新数组中的位置,而是为该元素“腾位置”。如果使用暂存的办法,空间复杂度必然要达到O(N),因此,需要换个思路。
2.3、我们这么思kao:a1从位置1移动到位置2,那么,位置2上的元素a2变化到了哪里呢?继续这个线索,我们得到一个“封闭”的环:
1 -> 2 -> 4 -> 8 -> 7 -> 5 -> 1
沿着这个环,可以把a1、a2、a4、b4、b3、b1这6个元素依次移动到最终位置;显然,因为每次只移动一个元素,代码实现时,只使用1个临时空间即可完成。(即:a=t;t=b;b=a)
此外,该变化的另外一个环是:
3 -> 6 -> 3
沿着这个环,可以把a3、b2这2个元素依次移动到最终位置。
2.4、上述过程可以通过若干的“环”的方式完整元素的移动,这是巧合吗?事实上,该问题的研究成果已经由Peiyush Jain在10nian前公开发表在A Simple In-Place Algorithm for In-Shuffle, Microsoft, July, 2004中。原始论文直接使用了一个结论,这里不再证明:对于2*n =(3^k-1)这种长度的数组,恰好只有k个环,且每个换的起始位置分别是1,3,9,...3^(k-1)。
对于2.3的例子,长度为8,是3^2-1,因此,只有2个环。环的其实位置分别是1和3。
2.5、至此,完美洗牌算法的“主体工程”已经完工,只存在一个“小”问题:如果数组长度不是(3^k-1)呢?
2.5.1、若2n!=(3^k-1),则总可以找到最大的整数m,使得m<n,并且2m=(3^k-1)。
2.5.2、对于长度为2m的数组,调用2.3和2.4中的方法整理元素,剩余的(2n-2m)长度,递归调用2.5.1即可。
2.5.3、在2.5.2中,需要交换一部分数组元素:

(下面使用[a,b]表示从a到b的一段子数组,包括端点)
①图中斜线阴影部分的子数组[1,m]应该和[n 1,n m]组成一个序列,调用2.3和2.4中的算法;
②因此,数组[m,n-m]循环左移n-m次即可。(注:字符串旋转是有空间复杂度O(1)的算法的,详情请看本文第一题)
2.6、以上,完成了该问题的全部求解过程。关于2*n =(3^k-1)满足k个环的问题,赘述很长,不妨kao察一下ψ(3)和ψ(9)。这里,ψ(N)即欧拉函数,表示小于N的自然数中,和N互素的数目。
2.7、原始问题要输出a1,b1,a2,b2……an,bn,而完美洗牌却输出的是b1,a1,b2,a2,……bn,an。解决办法非常简单:忽略原数组中的a1和bn,对于a2,a3,……an,b1,b2,……bn-1调用完美洗牌算法,即为结论。
3. 最长公共子序列(九度OJ 1042)
动态规划思想

思想简单描述:
如果两个字符串最后一位相同,则最后一位字符肯定是最长公共子序列的最后一位。
如果最后一位不同,则有可能第一个字符串中的最后一位是公共子序列,也可能是第二个字符串中的最后一位。当然也可能都不是则LCS(Xm,Yn)=LCS(Xm-1,Yn-1),但是这种情况包含在max{LCS(Xm-1,Yn),LCS(Xm,Yn-1)}中。
所以得出上面的式子。
Coding:
最直观的代码就是递归:
import java.io.IOException;
import java.util.Scanner;
public class Main
{
static char[] x = new char[50];
static char[] y = new char[50];
public static void main(String[] args) throws IOException
{
Scanner cin = new Scanner(System.in);
String a, b;
while (cin.hasNext())
{
a = cin.next();
b = cin.next();
x = a.toCharArray();
y = b.toCharArray();
int res = LCS(x.length - 1, y.length - 1);
System.out.println(res);
}
}
public static int LCS(int i, int j)
{
if (i < 0 || j < 0)
{
return 0;
}
if (x[i] == y[j])
{
return LCS(i - 1, j - 1) + 1;
}
else
{
int aa = LCS(i, j - 1);
int bb = LCS(i - 1, j);
return aa > bb ? aa : bb;
}
}
} 但是递归的效率太低,并且有太多的重复操作。
我们使用打表的方式来避免递归操作:
使用一个二维数组C[m,n]来保存LCS
C[i,j]代表Xi,Yj的最长公共子序列
当i=0或者j=0时代表有一个字符串为空,则C[i,j] =0

import java.io.IOException;
import java.util.Scanner;
public class Main
{
static char[] x = new char[50];
static char[] y = new char[50];
public static void main(String[] args) throws IOException
{
Scanner cin = new Scanner(System.in);
String a, b;
while (cin.hasNext())
{
a = cin.next();
b = cin.next();
x = a.toCharArray();
y = b.toCharArray();
int res = LCS(x.length, y.length);
System.out.println(res);
}
}
public static int LCS(int i, int j)
{
int[][] c = new int[50][50];
for (int k = 0; k <= i; k++)
{
c[k][0] = 0;
}
for (int k = 0; k <= j; k++)
{
c[0][k] = 0;
}
for (int k = 1; k <= i; k++)
{
for (int k2 = 1; k2 <= j; k2++)
{
if (x[k - 1] == y[k2 - 1])
{
c[k][k2] = c[k - 1][k2 - 1] + 1;
}
else
{
c[k][k2] = (c[k][k2 - 1] > c[k - 1][k2] ? c[k][k2 - 1]
: c[k - 1][k2]);
}
}
}
return c[i][j];
}
} 时间复杂度O(m*n)
4. 最长递增子序列(Leetcode 300)
例如:10, 9, 2, 5, 3, 7, 101, 18
输出:2, 3, 7, 101
很简单的思路就是,使用最长公共子序列来解决这个问题
最长公共子序列的解法在第3题中已经解释了。
解决最长递增子序列只需要
将原序列:10, 9, 2, 5, 3, 7, 101, 18
将原序列排序后的序列: 2, 3, 5, 7, 9, 10, 18, 101
这两个序列求最长公共子序列,得到的序列就是最长递增子序列
代码:
public class Solution {
public int lengthOfLIS(int[] nums) {
Integer[] s = new Integer[nums.length];
for (int i = 0; i < nums.length; i++)
{
s[i] = nums[i];
}
TreeSet<Integer> treeSet = new TreeSet<Integer>(Arrays.asList(s));
s = treeSet.toArray(new Integer[0]);
int[][] c = new int[nums.length + 1][nums.length + 1];
for (int i = 0; i <= nums.length; i++)
{
c[i][0] = 0;
}
for (int i = 0; i <= s.length; i++)
{
c[0][i] = 0;
}
for (int i = 1; i <= nums.length; i++)
{
for (int j = 1; j <= s.length; j++)
{
if (nums[i - 1] == s[j - 1])
{
c[i][j] = c[i - 1][j - 1] + 1;
}
else
{
c[i][j] = c[i - 1][j] > c[i][j - 1] ? c[i - 1][j]
: c[i][j - 1];
}
}
}
return c[nums.length][s.length];
}
}
由于是递增子序列,所以排序后的序列需要去重,这里用TreeSet即做了排序又去了重。时间复杂度O(n*n)
当然我们也可以使用动态规划的思想去解决这个问题
维护一个dp[]数组,dp[i]的意思是,必须以arr[i]结尾的最大递增子序列是多少。
比如arr = {1,2,3,2}
那么dp[3]的意思是,必须以arr[3]=2为最后的最大递增子序列,即{1,2}
那么我们知道了dp[i]后,如何得到dp[i+1]呢。
根据最大递增子序列的定义我们就能知道,dp[i+1]是dp[0...i]中最大的值dp[j],并且arr[j]<arr[i+1],这样我们也得到了一个O(n*n)的算法
public class Solution
{
public int lengthOfLIS(int[] nums)
{
if(nums.length == 0)
return 0;
int[] dp = new int[nums.length];
dp[0] = 1;
for (int i = 1; i < nums.length; i++)
{
int max = 0;
for (int j = i - 1; j >= 0; j--)
{
if (dp[j] > max && nums[j] < nums[i])
{
max = dp[j];
}
}
dp[i] = max + 1;
}
int max = 0;
for (int i = 0; i < dp.length; i++)
{
if(dp[i] > max)
{
max = dp[i];
}
}
return max;
}
} 最大递增子序列就是dp数组中最大的一个值
那么我们发现求dp[i]时需要遍历dp[0...i-1]的所有元素,能否优化这个操作呢?
假设存在一个序列d[1..9] ={ 2,1 ,5 ,3 ,6,4, 8 ,9, 7},可以看出来它的LIS长度为5。
下面一步一步试着找出它。
我们定义一个序列B,然后令 i = 1 to 9 逐个查看这个序列。
此外,我们用一个变量Len来记录现在最长算到多少了
首先,把d[1]有序地放到B里,令B[1] = 2,就是说当只有1一个数字2的时候,长度为1的LIS的最小末尾是2。这时Len=1
然后,把d[2]有序地放到B里,令B[1] = 1,就是说长度为1的LIS的最小末尾是1,d[1]=2已经没用了,很容易理解吧。这时Len=1
接着,d[3] = 5,d[3]>B[1],所以令B[1+1]=B[2]=d[3]=5,就是说长度为2的LIS的最小末尾是5,很容易理解吧。这时候B[1..2] = 1, 5,Len=2
再来,d[4] = 3,它正好加在1,5之间,放在1的位置显然不合适,因为1小于3,长度为1的LIS最小末尾应该是1,这样很容易推知,长度为2的LIS最小末尾是3,于是可以把5淘汰掉,这时候B[1..2] = 1, 3,Len = 2
继续,d[5] = 6,它在3后面,因为B[2] = 3, 而6在3后面,于是很容易可以推知B[3] = 6, 这时B[1..3] = 1, 3, 6,还是很容易理解吧? Len = 3 了噢。
第6个, d[6] = 4,你看它在3和6之间,于是我们就可以把6替换掉,得到B[3] = 4。B[1..3] = 1, 3, 4, Len继续等于3
第7个, d[7] = 8,它很大,比4大,嗯。于是B[4] = 8。Len变成4了
第8个, d[8] = 9,得到B[5] = 9,嗯。Len继续增大,到5了。
最后一个, d[9] = 7,它在B[3] = 4和B[4] = 8之间,所以我们知道,最新的B[4] =7,B[1..5] = 1, 3, 4, 7, 9,Len = 5。
于是我们知道了LIS的长度为5。
注意,这个1,3,4,7,9不是LIS,它只是存储的对应长度LIS的最小末尾。有了这个末尾,我们就可以一个一个地插入数据。虽然最后一个d[9] = 7更新进去对于这组数据没有什么意义,但是如果后面再出现两个数字 8 和 9,那么就可以把8更新到d[5], 9更新到d[6],得出LIS的长度为6。
然后应该发现一件事情了:在B中插入数据是有序的,而且是进行替换而不需要挪动——也就是说,我们可以使用二分查找,将每一个数字的插入时间优化到O(logN)~~~~~于是算法的时间复杂度就降低到了O(NlogN)~!
代码如下(代码中的数组B从位置0开始存数据):
public class Solution
{
public int lengthOfLIS(int[] nums)
{
if (nums.length == 0)
return 0;
int[] dp = new int[nums.length];
int[] B = new int[nums.length];
dp[0] = 1;
B[0] = nums[0];
int begin = 0;
int middle = 0;
int end = 0;
int right = 0;
for (int i = 1; i < nums.length; i++)
{
begin = 0;
end = right;
while (begin <= end)
{
middle = (begin + end) / 2;
if (nums[i] > B[middle])
{
begin = middle + 1;
}
else
{
end = middle - 1;
}
}
right = right > begin ? right : begin;
B[begin] = nums[i];
dp[i] = begin + 1;
}
int max = 0;
for (int i = 0; i < dp.length; i++)
{
if (dp[i] > max)
{
max = dp[i];
}
}
return max;
}
}
5. KMP算法(LeetCode 28)
给定文本串text与模式串pattern。从文本串text中找到模式串pattern第一次出现的位置。
KMP是一种线性时间复杂度的字符串匹配算法,它是对暴力算法的改进。
文本串长度为N,模式串长度为M,KMP算法时间复杂度为O(M+N),空间复杂度为O(M)(next数组)
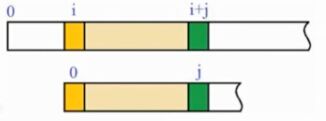
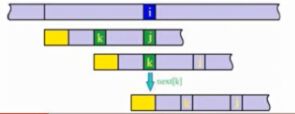
暴力算法思想很简单,就是不断匹配,如上图,文本串从i位置开始,模式串从0位置开始匹配,若匹配失败,则文本串从i+1位置开始,模式串回溯到0位置。
暴力求解的时间辅助度为O(M*N),空间复杂度为O(1)
而KMP算法的思想则是尽量减少回溯的发生

如上图两个字符串,当发现绿色部分与黄色部分不相等时,如果是暴力算法,则模式串要从0开始重新匹配,而KMP的思想则是,如果A和B是相同的,d与黄色部分不相等,不需要从0开始比较,可以从c开始比较。
因为A与B是相同的,能比较到绿色和黄色是否相等,即绿色前面和黄色前面是相等的,所以A与黄色前面字符串是相等的。这样就减少了回溯。
所以KMP的问题就归结到如果求出模式串中的最大相等的k前缀与k后缀。

那么该如何高效地求得next[j]呢?
next数组有如下递推关系:
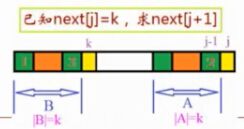
当next[j]=k,且p[k]==p[j]时,则很明显next[j+1]=next[j]+1
当p[k]不等于p[j]
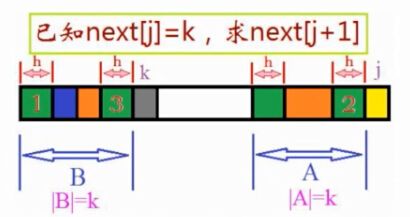
记next[k]=h,所以上图中的1,3,2都是相等的,即1和2是相等的,那么只需要比较蓝色部分和p[j]是否相等,如果相等又回到了第一种情况,如果不相同则再查看next[h]
代码:
public class Solution
{
public int strStr(String haystack, String needle)
{
if(needle.length() == 0)
{
return 0;
}
if(haystack.length() == 0)
{
return -1;
}
int ans = -1;
int needle_n = needle.length();
int haystack_n = haystack.length();
int[] next = new int[needle_n];
goNext(next, needle);
char[] haystackchar = haystack.toCharArray();
char[] needlechar = needle.toCharArray();
int i = 0;
int j = 0;
while (i < haystack_n)
{
if (j == -1 || haystackchar[i] == needlechar[j])
{
++i;
++j;
}
else
{
j = next[j];
}
if(j == needle_n)
{
ans = i - needle_n;
break;
}
}
return ans;
}
public void goNext(int[] next, String needle)
{
next[0] = -1;
int j = 0;
int k = -1;
int length = needle.length();
char[] p = needle.toCharArray();
while (j < length - 1)
{
// k表示next[j - 1],p[k]是前缀,p[j]是后缀
if (k == -1 || p[k] == p[j])
{
++j;
++k;
next[j] = k;
}
else
{
k = next[k];
}
}
}
} 优化:
如果i与j不相等,按照上述描述,应该讲模式串移到next[j]处,假设next[j]=k,如果k与j是相等的,那么k与i必然不相等,所以还要继续移到next[k]处。
那么何不直接将next[j]=next[k]呢,少了一步比较,效率更高。
public void goNext(int[] next, String needle)
{
next[0] = -1;
int j = 0;
int k = -1;
int length = needle.length();
char[] p = needle.toCharArray();
while (j < length - 1)
{
// k表示next[j - 1],p[k]是前缀,p[j]是后缀
if (k == -1 || p[k] == p[j])
{
++j;
++k;
if(p[k] == p[j])
{
next[j] = next[k];
}else
{
next[j] = k;
}
}
else
{
k = next[k];
}
}
} KMP(没有优化)的最好情况是,模式串中不存在相等的k前缀和k后缀,则next数组都是-1。一旦不匹配就跳过,比较次数是N
最差情况是,模式串中所有字符都是相等的,next数组是递增序列-1,0,1,2……
最差情况:

比较次数<2N
当优化后的KMP,最差情况也变成了最好情况

比较次数为N
6. Power Strings(POJ 2406)
求字符串的最小周期串,
例如
ababab的最小周期串是ab,重复了3次
aaaa的最小周期串是a,重复了4次
很直观的想法就是,暴力求解,
假设字符串是ababab
先拿一个字符a试,无法遍历babab
再拿两个字符试ab,可以遍历abab。
总之拿字符串长度能够整除的数去尝试。
import java.io.IOException;
import java.util.Scanner;
public class Main
{
public static void main(String[] args) throws IOException
{
Scanner cin = new Scanner(System.in);
String str;
while (cin.hasNext())
{
str = cin.next();
if(str.equals("."))
{
break;
}
for (int i = 1; i <= str.length(); i++)
{
if(str.length() % i != 0)
{
continue;
}
String pattern = str.substring(0, i);
String temp = str;
while(temp.length() > 0)
{
if(temp.startsWith(pattern))
{
temp = temp.substring(i);
}else {
break;
}
}
if(temp.length() == 0)
{
System.out.println(str.length()/i);
break;
}
}
}
}
} 时间辅助度为O(n^2),有没有更好的方法呢?
我们想到了KMP

求KMP中的next数组(非优化求法),记p =len - next[len],如果len%p==0,则p就是最小周期长度。
证明:
如上图,黄色部分就是next中的最长相等前后缀,两个绿色部分相等,即上图中下面部分的1=1,又1=2,而且2=2……如此迭代,,如果整个字符串的长度整除1,刚好能够遍历完整个字符串,则1就是最小周期长度。
代码:
import java.io.IOException;
import java.util.Scanner;
public class Main
{
public static void main(String[] args) throws IOException
{
Scanner cin = new Scanner(System.in);
String str;
int[] next = new int[1000001];
while (cin.hasNext())
{
str = cin.next();
if(str.equals("."))
{
break;
}
getNext(next , str);
int minlength = str.length() - next[str.length()] ;
if(str.length() % minlength == 0)
{
System.out.println(str.length() / minlength);
}else {
System.out.println(1);
}
}
}
public static void getNext(int[] next ,String str)
{
int length = str.length();
char[] p = str.toCharArray();
next[0] = -1;
int k = -1;
int j = 0;
while(j < length)
{
if(k == -1 || p[k] == p[j])
{
++j;
++k;
next[j] = k;
}else {
k = next[k];
}
}
}
}
7. 用二进制来编码字符串“abcdabaa",需要能够根据编码,解码回原来的字符串,最少需要__位的二进制字符串?
使用哈夫曼树来解决这个问题:
哈夫曼树是基于统计的编码方式,概率高的字符使用较短编码,例子如下:
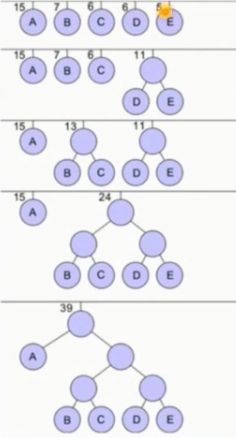
结点上面的数字表示频数。
同理,上述题目中使用哈夫曼树得到的结果就是:
a:1
b:01
c:001
d:000
所以需要14位。
因为哈夫曼编码是前缀编码,即任何一个字符的编码都不是另外一个字符编码的前缀。所以是可以解码唯一的。
8. 最长回文子串(Leetcode 5)
给定一个字符串,求它的最长回文子串的长度。
最直接的方法就是枚举每个子串,看看是否是回文子串,然后保存最长的子串。
由于奇数和偶数子串不同,所以要遍历两次。每个字符遍历时都当做回文的中心向两边扩展遍历。
public class Solution
{
public String longestPalindrome(String s)
{
char[] c = s.toCharArray();
int max = 1;
int maxBegin = 0;
int maxEnd = 0;
int temp = 0;
int tempBegin = 0;
int tempEnd = 0;
for (int i = 0; i < c.length; i++)
{
//奇数
for (int j = 0; i - j >= 0 && i + j < c.length; j++)
{
if (c[i - j] != c[i + j])
{
break;
}
temp = j * 2 + 1;
tempBegin = i - j;
tempEnd = i + j;
}
if (temp > max)
{
max = temp;
maxBegin = tempBegin;
maxEnd = tempEnd;
}
//偶数
for (int j = 0; i - j >= 0 && i + j + 1 < c.length; j++)
{
if (c[i - j] != c[i + j + 1])
{
break;
}
temp = j * 2 + 2;
tempBegin = i - j;
tempEnd = i + j + 1;
}
if (temp > max)
{
max = temp;
maxBegin = tempBegin;
maxEnd = tempEnd;
}
}
return s.substring(maxBegin, maxEnd + 1);
}
} 时间复杂度为O(n^2)
时间复杂度那么高的原因是每次都要重新扩展,i为中心的扩展并没有影响到i+1,导致很多重复扩展。
有没有什么好的方法能够降低时间复杂度呢?
这里就提到了著名的Manacher算法。
首先Manacher算法不再需要区分奇数回文和偶数回文,它使用一种技巧回避了这个问题。
它将子串中都加入特殊字符
比如aba -> #a#b#a# abba -> #a#b#b#a#
这样都只用kao虑奇数情况往外扩展就可以了。
那么如何使扩展更高效呢?
这里使用了3个变量来辅助扩展
pArr[] 这个是回文半径,pArr[i]表示以i为中心的回文半径
pR表示已遍历过的回文半径的最大边界的下一个
index表示pR的回文中心
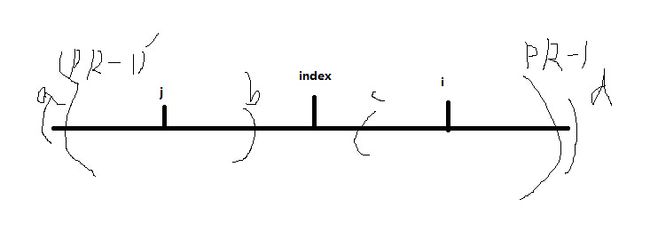
那么当遍历到i时,分为以下几种情况,取j和i于index对称
因为此时j的回文已经遍历过了,我们希望通过j来直接得到i的回文,而不需要进行扩展
1. j的回文包含在index回文中,那么由图可以知道,必然i的回文就等于j的回文

2. j的回文不包含在index内,出了边界,可以得知a不等于d(因为如果相等,index的回文会扩展到d),a==b==c,所以c不等于d。那么必然i的回文会比j的范围要小一点,i的回文的右边界一定是pR-1处
3.j的回文与左边界重合,此时很明显a==b==c==d,但是i的回文不一定只到d,它可以继续尝试扩展
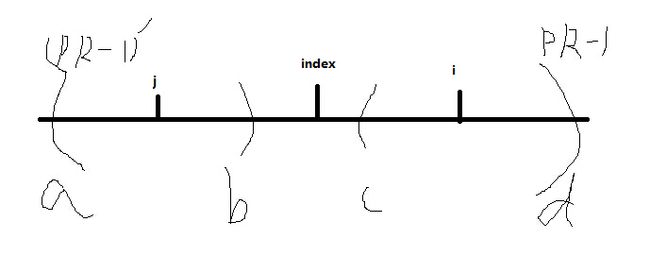
4.i在最大回文边界之外,此时没有优化手段,直接由i进行扩展

从以上的情况中我们发现,只有3,4需要进行扩展,并且3的只需要扩展一部分。这样大大优化了扩展的次数,降低了时间复杂度,Manacher的时间复杂度为O(n),因为pR最大包括整个字符串。
代码:
public class Solution
{
public String longestPalindrome(String s)
{
char[] d = s.toCharArray();
StringBuffer sb = new StringBuffer();
for (int i = 0; i < s.length(); i++)
{
sb.append("#");
sb.append(d[i]);
}
sb.append("#");
char[] c = sb.toString().toCharArray();
int[] pArr = new int[c.length];
int pR = 0;
int index = 0;
int begin = 0;
int end = 0;
int max = 0;
for (int i = 0; i < c.length; i++)
{
if (pR > i)
{
if (pArr[2 * index - i] < pR - i)//情况1
{
pArr[i] = pArr[2 * index - i];
}
else//情况2,3
{
pArr[i] = pR - i;
}
}
else//情况4
{
pArr[i] = 1;
}
while (i + pArr[i] < c.length && i - pArr[i] >= 0
&& c[i + pArr[i]] == c[i - pArr[i]])
{
pArr[i]++;
}
if (pArr[i] + i > pR)
{
pR = i + pArr[i];
index = i;
}
if(pArr[i] > max)
{
max = pArr[i];
begin = i - pArr[i] + 1;
end = i + pArr[i] - 1;
}
}
StringBuffer res = new StringBuffer();
for (int i = begin + 1; i < end; i++)
{
if (c[i] != '#')
{
res.append(c[i]);
}
}
return res.toString();
}
}
字符串总结:
字符串查找:CRUD
KMP/BM
map/set;RBtree
hash
trie树
对字符串本身操作
全排列
Manacher
回文划分
系列:
【算法系列 一】 Linked List
【算法系列 二】 Stack
【算法系列 三】 Quene
【算法系列 四】 String
Reference:
1. 七月算法十月算法在线班
2. http://ask.julyedu.com/question/33
3. http://qiemengdao.iteye.com/blog/1660229
4. http://v.qq.com/page/s/j/g/s0157v08yjg.html?start=3