全文索引----solr服务器更新全量索引
一 配置数据源
1.1 数据库
我们使用单表作为测试数据源,包括三个字段,id,title,content,方便测试,使用varchar作为主键数据类型。结构如下:
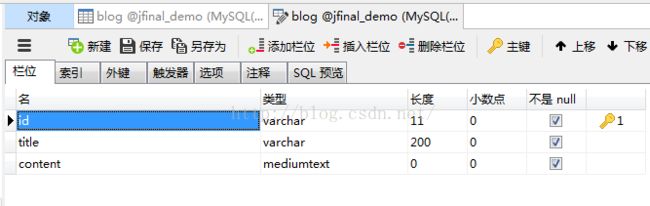
数据源配置内容如下:
<pre name="code" class="html"><span style="font-size:18px;"><dataConfig>
<dataSource name="jfinal_demo" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://192.168.21.20:3306/jfinal_demo" user="root" password="123456" batchSize="-1" />
<document name="testDoc">
<entity name="blog" dataSource="jfinal_demo" pk="id" query="select * from blog">
<field column="id" name="id"/>
<field column="title" name="title"/>
<field column="content" name="content"/>
</entity>
</document>
</dataConfig></span>
1.3 配置schema.xml
索引文件配置如下:
<span style="font-size:18px;"><pre name="code" class="html"><field name="id" type="text_general" indexed="true" stored="true" /> <field name="title" type="text_general" indexed="true" stored="true" /> <field name="content" type="text_general" indexed="true" stored="true" /></span>
二 使用solr Admin客户端更新索引
2.1 更新操作如下:
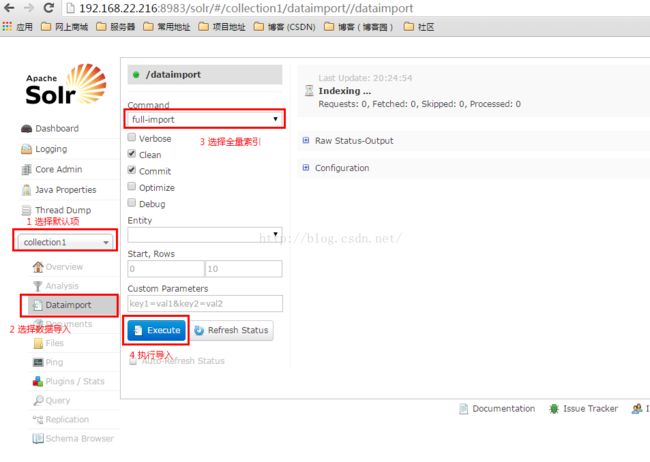
2.2 测试
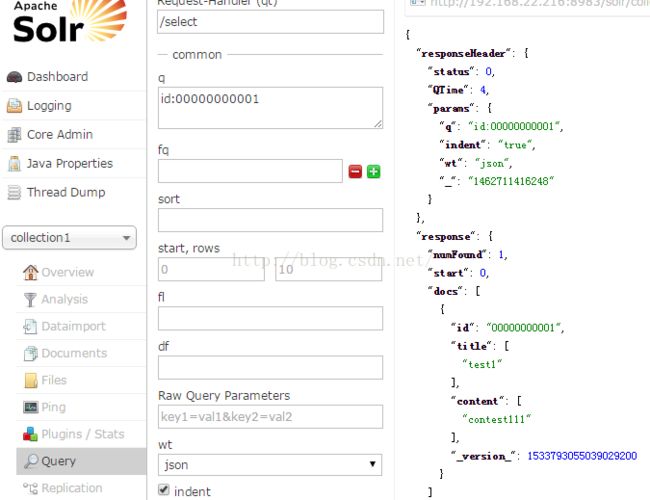
说明:使用solr Admin客户端方式,简单,快捷,直观性强,适用于数据测试。
三 使用http请求更新索引
3.1 原理 我们知道,所有的solr操作最终都会转化为一个http的get请求访问服务器,所以,我们可以模仿客户端直接通过http请求来更新索引。
3.2 实现
本文使用HttpURLConnection对象来完成http请求,代码如下:
<span style="font-size:18px;"><span style="white-space:pre"> </span>/**
* 访问URL,全量索引
*/
public static Boolean runHttpGet(){
Boolean flag = false;
//设置请求的路径
String strUrl="http://192.168.22.216:8983/solr/dataimport?command=full-import";
//将请求的参数进行UTF-8编码,并转换成byte数组=
try {
//创建一个URL对象
URL url=new URL(strUrl);
//打开一个HttpURLConnection连接
HttpURLConnection urlConn=(HttpURLConnection)url.openConnection();
//设置连接超时的时间
urlConn.setDoOutput(true);
//在使用post请求的时候,设置不能使用缓存
urlConn.setUseCaches(false);
//设置该请求为post请求
urlConn.setRequestMethod("GET");
urlConn.setInstanceFollowRedirects(true);
//配置请求content-type
urlConn.setRequestProperty("Content-Type", "application/json, text/javascript");
//执行连接操作
urlConn.connect();
//发送请求的参数
DataOutputStream dos=new DataOutputStream(urlConn.getOutputStream());
dos.flush();
dos.close();
if(urlConn.getResponseCode()==200){
flag = true;
//显示
InputStreamReader isr = new InputStreamReader(urlConn.getInputStream(), "utf-8");
int i;
String strResult = "";
// read
while ((i = isr.read()) != -1) {
strResult = strResult + (char) i;
}
//System.out.println(strResult.toString());
isr.close();
}
} catch (Exception e) {
e.printStackTrace();
}
return flag;
}</span>
当然,我们在实际使用中,会定时来完成索引更新,所以我们可以通过quartz做任务调度,这里不再示范代码,有兴趣的读者可以根据实际情况去完成。3.3 测试
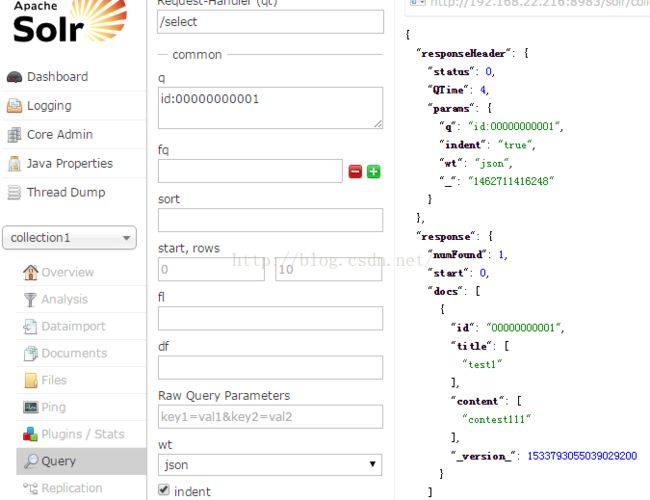
四 使用官方Scheduler实现索引更新
4.1 概述
Solr官方提供了强大的Data Import Request Handler,同时提供了ScheDuler,示例中的Scheduler只支持增量索引,不支持定期全量索引,有网友经过改装,增加了全量索引定时器。我在这里只做介绍,博客地址:
引用如下:
4.2 jar包配置
将 apache-solr-dataimportscheduler-1.0.jar 和solr自带的 apache-solr-dataimporthandler-.jar, apache-solr-dataimporthandler-extras-.jar 放到solr.war的lib目录下面
4.3 配置web.xml
修改solr.war中web.xml,在servlet节点钱面增加:<span style="font-size:18px;"> <listener>
<listener-class>
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
</listener-class>
</listener></span>
4.4 配置索引更新文件
将apache-solr-dataimportscheduler-.jar 中 dataimport.properties 取出并根据实际情况修改,然后放到 solr.home/conf (不是solr.home/core/conf) 目录下面
dataimport.properties配置项说明:
<span style="font-size:18px;">################################################# # # # dataimport scheduler properties # # # ################################################# # to sync or not to sync # 1 - active; anything else - inactive syncEnabled=1 # which cores to schedule # in a multi-core environment you can decide which cores you want syncronized # leave empty or comment it out if using single-core deployment syncCores=core1,core2 # solr server name or IP address # [defaults to localhost if empty] server=localhost # solr server port # [defaults to 80 if empty] port=8080 # application name/context # [defaults to current ServletContextListener's context (app) name] webapp=solr # URL params [mandatory] # remainder of URL params=/dataimport?command=delta-import&clean=false&commit=true # schedule interval # number of minutes between two runs # [defaults to 30 if empty] interval=1 # 重做索引的时间间隔,单位分钟,默认7200,即5天; # 为空,为0,或者注释掉:表示永不重做索引 reBuildIndexInterval=7200 # 重做索引的参数 reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true # 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000; # 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期 reBuildIndexBeginTime=03:10:00</span>
4.5 重启solr服务器
4.6 第三种方式较为简单,并且不需要额外的程序支持,所以建议使用。
五 总结
全量索引简单直接,但是在数据量较大时,系统需要消耗过多的IO资源,所以需要将索引的更新时间间隔设置较大,这样可能会造成数据在短时间内不同步,但是这样会影响用户体验度,时效性较强的系统不建议使用全量索引方式。