python 爬虫实战--登陆学校教务系统获取成绩信息
1. 前言
之前写的爬虫都是不需要使用cookie的, 这次我们瞄上了学校的教务系统, 每次登陆都那么几个步骤好费劲啊, 写个爬虫直接获取成绩多好啊~~
2. 项目分析
首先, 我们的目标页面是: http://yjs.ustc.edu.cn/
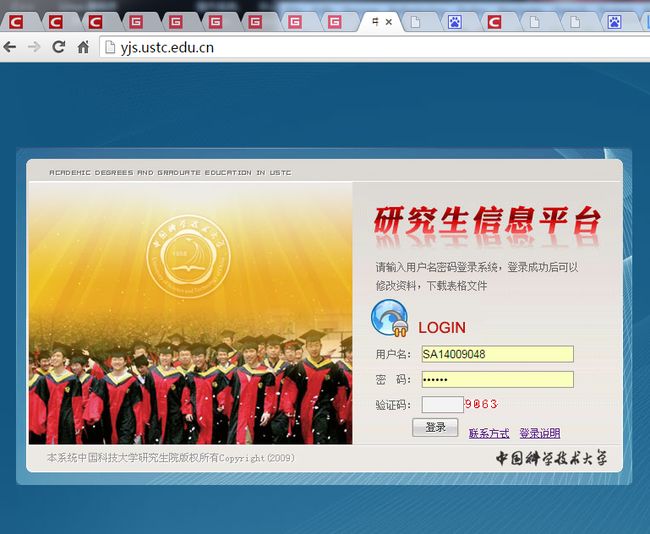
查看网页源码

我们发现我们框选出来的地址就是我们验证码的地址:
http://yjs.ustc.edu.cn/checkcode.asp利用chrome 自带的抓包功能, 我们模拟登陆
先输入账号, 密码, 以及验证码,点击登陆
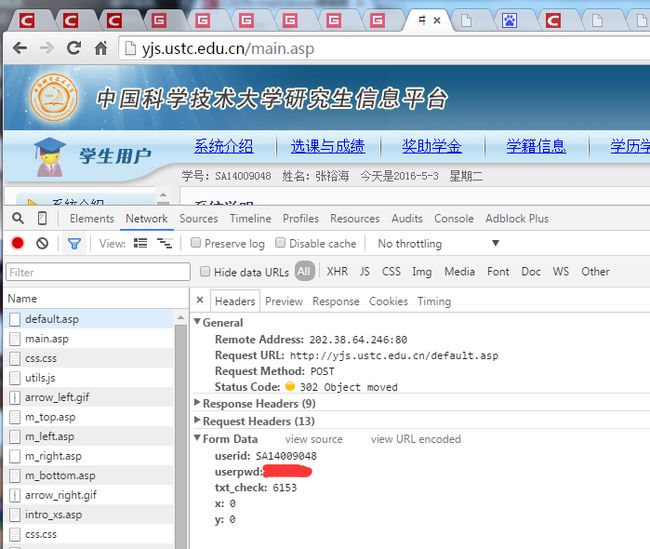
我们发现, 302 是临时重定向, 也就是说登陆成功之后, 转向我们最终页面, 但是我们实际的账号, 密码, 验证码信息都是发向这个地址的
http://yjs.ustc.edu.cn/default.asp然后, 我们找到我们成绩查询的页面
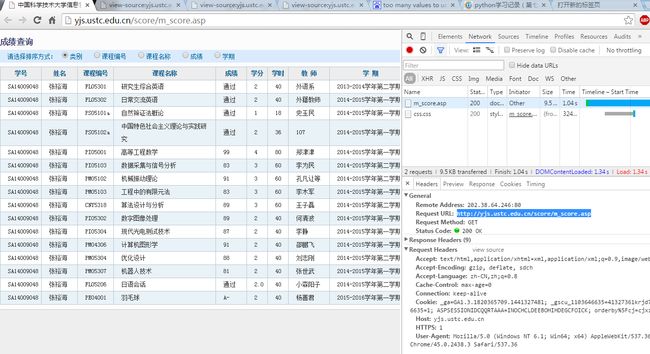
http://yjs.ustc.edu.cn/score/m_score.asp
上图是成绩页面的源码, 很容易可以分析得到正则表达式为
string = r'<td class.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>(.*?)</td.*?td.*?"bt06".*?>(.*?)</td.*?"bt06".*?>(.*?)</td.*?td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?</td>'至此, 几个关键的连接地址都被我们找到了
3. 验证码处理思路
对于验证码的处理, 主要有3种思路,
1. 把学校网站上的验证码全部down下来, 做成一个数据库, 直接查询即可
2. 使用ocr识别
3. 人工识别
我们这里为了简单起见, 采用人工识别的方法, 先将网页中的验证码down下来, 然后手工识别他
4. 其他
这个项目还有几个点需要注意:
1. python 伪装成浏览器进行登录, 设置 headers
2. cookie 连接
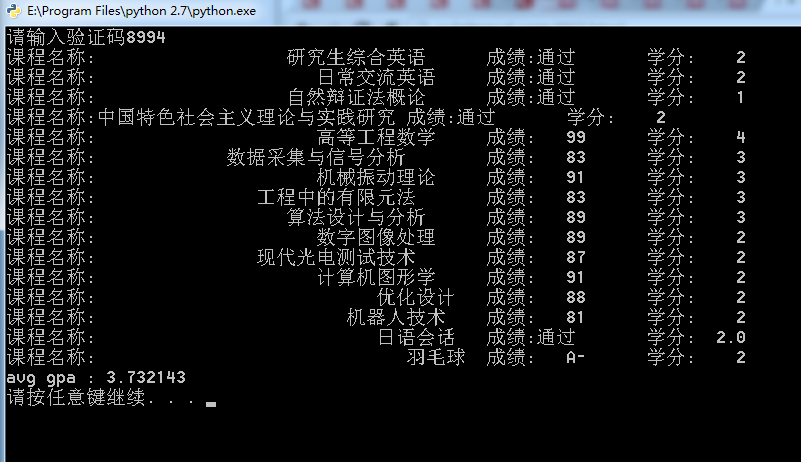
5. 运行效果图
6. code
# -*- coding:utf-8 -*-
''' Created on 2016-5-2 获取 教务系统 信息 @author: ThinkPad User '''
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import urllib
import urllib2
import re
import cookielib
import sys
import os
import string
class YJSSpider:
# 模拟登陆研究生教务系统
def __init__(self):
self.baseURL = ""
self.enable = True
self.charaterset = "gb2312"
string = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2438.3 Safari/537.36"
self.headers = {'User-Agent' : string}
self.cookie = cookielib.CookieJar()
self.hander = urllib2.HTTPCookieProcessor(self.cookie)
self.opener = urllib2.build_opener(self.hander)
# 验证码处理
def getCheckCode(self):
# 验证码连接
checkcode_url = "http://yjs.ustc.edu.cn/checkcode.asp"
request = urllib2.Request(checkcode_url, headers=self.headers)
picture = self.opener.open(request).read()
# 将验证码写入本地
local = open("checkcode.jpg", "wb")
local.write(picture)
local.close()
# 调用系统默认的图片查看程序查看图片
os.system("checkcode.jpg")
# 手工识别验证码
txt_check = raw_input(str("请输入验证码").encode(self.charaterset))
return txt_check
# 模拟登陆
def login(self, userid, userpwd):
# 获取验证码
txt_check = self.getCheckCode()
postData = {"userid":userid, "userpwd":userpwd, "txt_check":txt_check}
data = urllib.urlencode(postData)
request_url = "http://yjs.ustc.edu.cn/default.asp"
request_new = urllib2.Request(request_url, headers=self.headers)
response = self.opener.open(request_new, data)
# 抓取网页
def getHtml(self, url):
try:
request_score = urllib2.Request(url, headers=self.headers)
response_score = self.opener.open(request_score)
return response_score.read().decode("gb2312", 'ignore').encode("utf8")
except urllib2.URLError, e:
if hasattr(e, "reason"):
string = "连接bbs 失败, 原因" + str(e.reason)
print string.encode(self.charaterset)
return None
# 获取成绩信息
def getScore(self):
# get score
score_url = "http://yjs.ustc.edu.cn/score/m_score.asp"
content = self.getHtml(score_url)
if not content:
print "获取成绩失败"
return
string = r'<td class.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>(.*?)</td.*?td.*?"bt06".*?>(.*?)</td.*?"bt06".*?>(.*?)</td.*?td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?<td.*?"bt06".*?>.*?</td>'
pattern = re.compile(string, re.S)
res = re.findall(pattern, content)
class_name = []
class_grade = []
class_credit = []
for item in res:
class_name.append(item[0])
class_grade.append(item[1])
class_credit.append(item[2])
#record = unicode("课程名称:%40s\t成绩:%5s\t学分:%5s" % (item[0].strip(), item[1].strip(), item[2].strip()), "utf8")
#print item[0].encode("utf8"), item[1], item[2]
#print record
return [class_name, class_grade, class_credit]
# 科大的gpa 转化公式, 不全, 我们只写了自己成绩中对应的部分
def convert2GPA(self, grade):
if grade == "通过":
return None
if grade == "A-":
return 3.7
try:
grade_int = int(grade)
if grade_int >= 95:
return 4.3
if grade_int >= 90:
return 4.0
if grade_int >= 85:
return 3.7
if grade_int >= 82:
return 3.4
if grade_int >= 78:
return 3.1
return None
except:
return None
# 成绩显示
def display(self):
result = self.getScore()
name = result[0]
grade = result[1]
credit = result[2]
sum = 0
count = 0
for i in range(len(name)):
record = unicode("课程名称:%40s\t成绩:%5s\t学分:%5s" % (name[i], grade[i], credit[i]), "utf8")
print record.encode(self.charaterset)
gpa = self.convert2GPA(grade[i])
if not gpa:
continue
sum += gpa * string.atof(credit[i])
count += string.atof(credit[i])
avg = sum / count
print str("avg gpa : %f" % avg).encode(self.charaterset)
if "__main__" == __name__:
userid = "SA14009048"
# 这里改成自己的账号和密码信息
userpwd = "xxxxxx"
yjs = YJSSpider()
yjs.login(userid, userpwd)
yjs.display()
os.system("pause")