13、集合
十三、集合
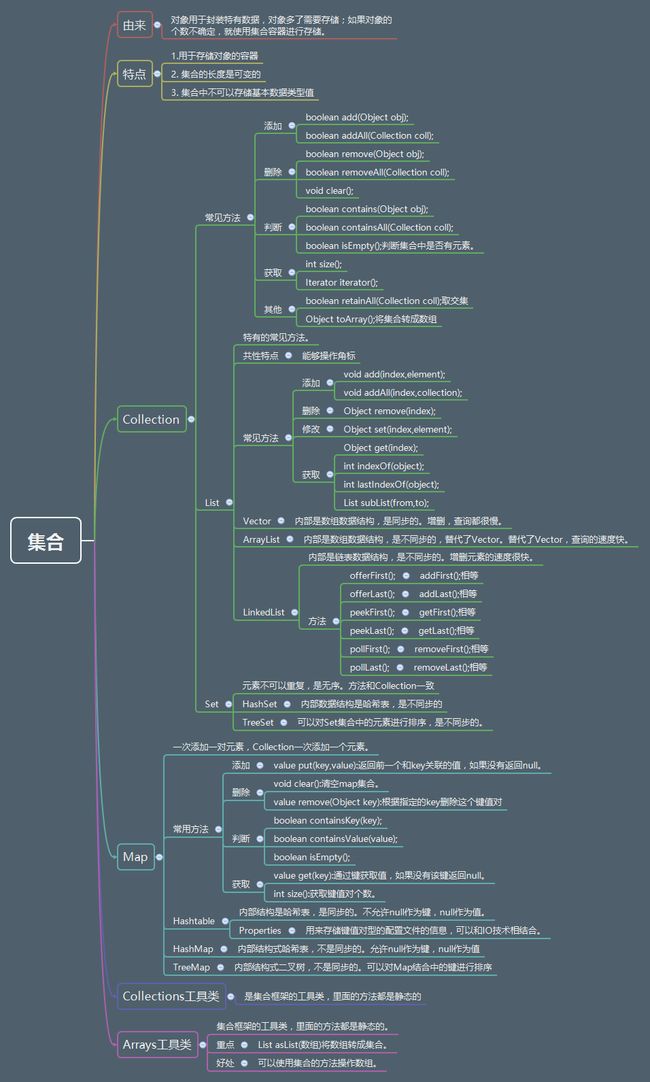
1、集合框架体系图

2、系统框架图(xmind)
3、tips
——1.集合概述
集合容器因为内部的数据结构不同,有多种具体容器。不断的向上抽取,就形成了集合框架。
数组和集合的区别:
数组虽然也可以存储对象,但长度是固定的;集合长度是可变的。
数组中可以存储基本数据类型,集合只能存储对象。
——2.迭代器Iterator
取出元素的方式:迭代器 —— Iterator iterator();
该对象必须依赖于具体容器,因为每一个容器的数据结构都不同,所以该迭代器对象是在容器中进行内部实现的,也就是iterator方法在每个容器中的实现方式是不同的。对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可,也就是iterator方法。Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
在迭代器过程中,不要使用集合操作元素,容易出现异常:java.util.ConcurrentModificationException。可以使用Iterator接口的子接口ListIterator来完成在迭代中对元素进行更多的操作。
——3.Collection
|--List:有序(存入和取出的顺序一致),元素都有索引(角标),允许重复元素:List集合可以完成对元素的增删改查。
|--Vector:内部是数组数据结构,是同步的。增删,查询都很慢。
|--ArrayList:内部是数组数据结构,是不同步的,替代了Vector。替代了Vector,查询的速度快。
|--LinkedList:内部是链表数据结构,是不同步的。增删元素的速度很快。
|--Set:元素不能重复,无序。
——5.Set,hashSet
哈希表确定元素是否相同:
1. 判断的是两个元素的哈希值是否相同。如果相同,再判断两个对象的内容是否相同。
2. 判断哈希值相同,其实判断的是对象的HashCode方法。判断内容相同,用的是equals方法。
如果哈希值不同,不需要判断equals。(TreeSet判断元素唯一性的方式:就是根据比较方法的返回结果是否是0,是0,就是相同元素,不存。)
——6.TreeSet排序
1)TreeSet对元素进行排序的方式一: 让元素自身具备比较功能,元素就需要实现Comparable接口,覆盖compareTo方法。
2)如果不要按照对象中具备的自然顺序进行排序。如果对象中不具备自然顺序。可以使用TreeSet集合第二种排序方式:
让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。将该类对象作为参数传递给TreeSet集合的构造函数。
3)如果自定义类实现了Comparable接口,并且TreeSet的构造函数中也传入了比较器,那么将以比较器的比较规则为准。TreeSet集合的底层是二叉树进行排序的。
——7.Map与Collection
1)Map:一次添加一对元素
Collection:一次添加一个元素
2)Map也称为双列集合
Collection集合称为单列集合
其实Map集合中存储的就是键值对,map集合中必须保证键的唯一性,键有了判断依据,HashMap中的值就被覆盖。
Map在有映射关系时,可以优先考虑,在查表法中的应用较为多见。
Map
|--Hashtable:内部结构是哈希表,是同步的。不允许null作为键,null作为值。
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap:内部结构式哈希表,不是同步的。允许null作为键,null作为值。
|--TreeMap:内部结构式二叉树,不是同步的。可以对Map结合中的键进行排序。
(hashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持)
——8.数组与集合的转换
1.集合转数组
使用的就是Collection接口中的toArray方法。可以对集合中的元素操作的方法进行限定,不允许对其进行增删。
toArray方法需要传入一个指定类型的数组。
如何定义长度:
如果长度小于集合的size,那么该方法会创建一个同类型并和集合相同的size的数组。如果长度大于集合的size,那么该方法就会使用指定的数组,存储集合中的元素,其他位置默认为null。所以建议,最后长度就指定为,集合的size
4、练习
——1.hashSet
//需求:往HashSet集合中存储Person对象。如果姓名和年龄相同,视为同一个人,视为相同元素。
import java.util.Iterator;
import java.util.HashSet;
class personDemo2
{
public static void main(String[] args)
{
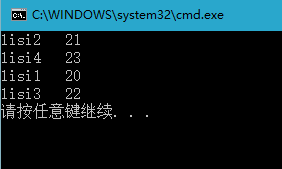
HashSet hs = new HashSet();
hs.add(new person("lisi1",20));
hs.add(new person("lisi2",21));
hs.add(new person("lisi3",22));
hs.add(new person("lisi4",23));
hs.add(new person("lisi2",21));
Iterator it = hs.iterator();
while(it.hasNext())
{
person p = (person)(it.next());
System.out.println(p.getname()+" "+p.getage());
}
}
}
class person
{
private String name;
private int age;
public person(){}
public person(String name,int age)
{
this.name = name;
this.age = age;
}
//设置名字方法
public void setname(String name)
{
this.name = name;
}
//获取名字方法
public String getname()
{
return this.name;
}
//设置年龄方法
public void setage(int age)
{
this.age = age;
}
//获取年龄方法
public int getage()
{
return this.age;
}
public int hashCode()
{
return name.hashCode()+age*39;
}
//判断两个元素是否相等的方法
public boolean equals(Object obj)
{
//判断类型
if(this == obj)
return true;
if(!(obj instanceof person))
throw new ClassCastException("类型错误");
person p = (person)obj;
//判断年龄和姓名是否相同,两者需同时成立
return this.name.equals(p.name) && this.age == p.age;
}
}
运行结果:
——2.ArrayList
//定义功能去除ArrayList中的重复元素。
import java.util.ArrayList;
import java.util.Iterator;
class ArrayListTest
{
public static void main(String[] args)
{
ArrayList al = new ArrayList();
al.add(new person("lisi1",20));
al.add(new person("lisi1",21));
al.add(new person("lisi4",24));
al.add(new person("lisi2",22));
al.add(new person("lisi4",24));
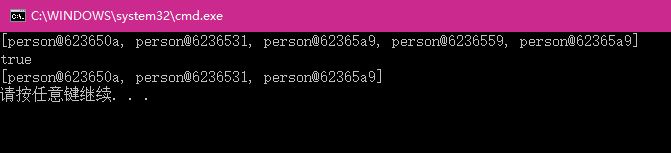
System.out.println(al);
al = getSingleElements(al);
//remove底层用的还是equals方法
System.out.println(al.remove(new person("lisi2",22)));
System.out.println(al);
}
public static ArrayList getSingleElements(ArrayList al)
{
//定义一个临时容器
ArrayList temp = new ArrayList();
//迭代al集合
Iterator it = al.iterator();
while(it.hasNext())
{
Object obj = it.next();
//判断被迭代到的元素是否在临时容器存在
//contains方法依靠的是equals方法
if(!temp.contains(obj))
temp.add(obj);
}
return temp;
}
}
运行结果:
——3.TreeSet
/**
* 声明类Student,包含3个成员变量:name、age、score,创建5个对象装入TreeSet,
* 按照成绩排序输出结果(考虑成绩相同的问题)。
*/
import java.util.TreeSet;
import java.util.Iterator;
import java.lang.Comparable;
public class TreeSetDemo
{
public static void main(String[] args)
{
//定义TreeSet,泛型为Student
TreeSet<Student> stu = new TreeSet<Student>();
//添加5个Student类
stu.add(new Student("lisi",20,67));
stu.add(new Student("wangwu",21,71));
stu.add(new Student("zhaoliu",20,66));
stu.add(new Student("zhangsan",21,66));
stu.add(new Student("chener",20,100));
//迭代输出
Iterator<Student> it = stu.iterator();
while(it.hasNext())
{
Student s = (Student)it.next();
System.out.println(s.getName()+","+s.getAge()+","+s.getScore());
}
}
}
//定义Student类并实现Comparable接口
class Student implements Comparable<Object>
{
private String name;
private int age;
private int score;
Student(String name,int age,int score)
{
this.name = name;
this.age = age;
this.score = score;
}
public String getName()
{
return this.name;
}
public int getAge()
{
return this.age;
}
public int getScore()
{
return this.score;
}
//实现接口,将comparaTo方法重写
public int compareTo(Object obj)
{
if(!(obj instanceof Student))
throw new RuntimeException("类型不正确");
Student s = (Student)obj;
//将输入的对象的成绩与前一个进行对比,值大于与小于分别排序
int num = new Integer(this.score).compareTo(new Integer(s.score));
//当num值等于0时说明两个对象成绩相同,之后比较姓名进行次级排序
if(num == 0)
return this.name.compareTo(s.name);
return num;
}
}
运行结果:

——4.hashMap
/*
每一个学生都有对应的归属地。
学生Student,地址String。
学生属性:姓名,年龄。
注意:姓名和年龄相同的视为同一个学生。
保证学生的唯一性。
思路:1、描述学生类
2、定义一个Map集合,存储学生对象和地址值
3、获取Map中的元素
*/
import java.util.*;
//描述学生类
class Student implements Comparable<Student>
{
private String name;
private int age;
Student(String name,int age)
{
this.name=name;
this.age=age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
//复写hashCode
public int hashCode()
{
return name.hashCode()+age*33;
}
//复写equals,比较对象内容
public boolean equals(Object obj)
{
if(!(obj instanceof Student))
throw new ClassCastException("类型不匹配");
Student s=(Student)obj;
return this.name.equals(s.name)&&this.age==s.age;
}
//复写compareTo,以年龄为主
public int compareTo(Student c)
{
int num=new Integer(this.age).compareTo(new Integer(c.age));
if(num==0)
{
return this.name.compareTo(c.name);
}
return num;
}
//复写toString,自定义输出内容
public String toString()
{
return name+"..."+age;
}
}
class HashMapTest
{
public static void main(String[] args)
{
HashMap<Student,String > hm=new HashMap<Student,String >();
hm.put(new Student("zhangsan",12),"beijing");
hm.put(new Student("zhangsan",32),"sahnghai");
hm.put(new Student("zhangsan",22),"changsha");
hm.put(new Student("zhangsan",32),"USA");
hm.put(new Student("zhangsan",12),"tianjing");
keyset(hm);
}
//keySet取出方式
public static void keyset(HashMap<Student,String> hm)
{
Iterator<Student> it=hm.keySet().iterator();
while(it.hasNext())
{
Student s=it.next();
String addr=hm.get(s);
System.out.println(s+":"+addr);
}
}
}
运行结果:
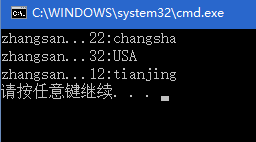
——5.TreeMap
/*
思路:1、将字符串转换为字符数组
2、定义一个TreeMap集合,用于存储字母和字母出现的次数
3、用数组去遍历集合,如果集合中有该字母则次数加1,如果集合中没有则存入
4、将TreeMap集合中的元素转换为字符串
*/
import java.util.*;
class CharCount
{
public static void main(String[] args)
{
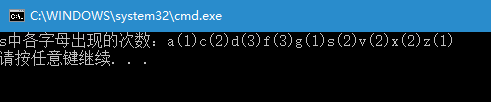
String s="sdfgzxcvasdfxcvdf";
System.out.println("s中各字母出现的次数:"+charCount(s));
}
//定义一个方法获取字符串中字母出现的次数
public static String charCount(String str)
{
char[] cha=str.toCharArray();//转换为字符数组
//定义一个TreeMap集合,因为TreeMap集合会给键自动排序
TreeMap<Character,Integer> tm=new TreeMap<Character,Integer>();
int count=0;//定义计数变量
for (int x=0;x<cha.length ;x++ )
{
if(!(cha[x]>='a'&&cha[x]<='z'||cha[x]>='A'&&cha[x]<='Z'))
continue;//如果字符串中非字母,则不计数
Integer value=tm.get(cha[x]);//获取集合中的值
if(value!=null)//如果集合中没有该字母,则存入
count=value;
count++;
tm.put(cha[x],count);//存入键值对
count=0;//复位计数变量
}
StringBuilder sb=new StringBuilder();//定义一个容器
//遍历集合,取出并以题目格式存入容器中
for(Iterator<Character> it=tm.keySet().iterator();it.hasNext();)
{
Character ch=it.next();
Integer value=tm.get(ch);
sb.append(ch+"("+value+")");
}
return sb.toString();//返回字符串
}
}
运行结果: