Lock wait timeout
昨天开发过程中,调试一段代码的时候程序抛出了Lock wait timeout excaption。
Caused by: java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1055)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:956)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3558)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3490)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1959)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2109)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2643)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2077)
at com.mysql.jdbc.PreparedStatement.execute(PreparedStatement.java:1356)
这个太奇怪了,因为没有并发存在(只有一个人在访问数据库),而且所有的操作都是在一个Service里面,事务的传播机制是PROPAGATION_REQUIRED (autocommit为默认值),按道理来说这些操作是在一个事务里面的,不应该会出现这种状况啊。
首先查看数据库:information_schema.trx, information_schema.innodb_locks,information_schema.innodb_lock_waits
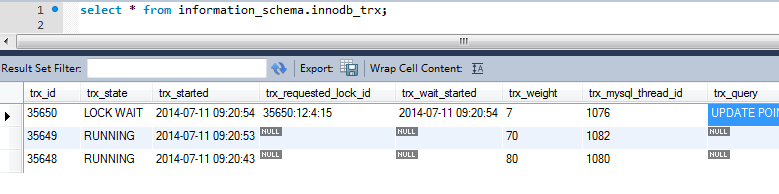

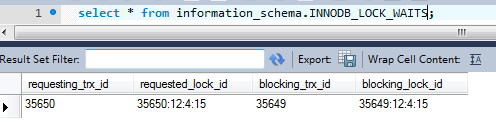
问题大概能看出来了,innodb_locks这两个锁加在同一个表的同一个index上面,一个是X锁,一个是S锁,而这两个锁有分别属于不同的trx,所以会出现锁等待的问题。可是让我比较纳闷的是,为什么数据库这边会有三个trx??不应该是一个吗?当场我就斯巴达了。在程序里大家都是由一个事物来管理呀,这一点百思不得其解,后来查看程序这边debug的log,发现程序这边也是有三个事务,额……
第二天早上在地铁上跟Adrian(一个项目组,而且合租房子)说起这个事情,聊着聊着发现我昨天一直忽略了重要的一点:这个系统数据库这边是分库分表的!
在这里简单介绍一下数据库这边,数据库设计这边是分库分表的,有两个库:DBA和DBB,两个库在同一台机器上;在每个库内,有一些表是分表的,像tablea0, tablea1这样(分表跟这次lock的问题关系不大)。所有需要分表的记录都直接或者间接关联到某个user下面,分库分表的策略都是根据userID来做的,根据userID计算出shardValue然后选择datasource和table。如果不需要分库分表,那么就访问默认的datasource,这里是DB_A。
出问题的代码,简单表述如下:
public class TestServiceImpl {
public void methodA() {
this.methodB();
foreach DB{
this.methodC();
}
}
//由于有分表,所以shardValue不同,操作的表不同。这里shardValue取决于有多少个表。
private void methodB() {
executeSQL:
update table_b_single
inner join (
select id from (
select id from DB_A.table_a_0
union all
select id from DB_A.table_a_1
union all
select id from DB_B.table_a_0
union all
select id from DB_B.table_a_1
) as tempTable
) tempA
on table_b.id = tempA.id
set table_b.name='newName';
}
private void methodC() {
executeSQL:
insert into table_a_{shardValue} values (...);
}
}
问题产生原因大致是这样的: 先说methodC,methodC中的SQL是在单个数据库中完成的,但是呢需要在每个库中都执行methodC中的SQL,由于事务不可能跨数据库,所以每次执行的时候在数据库层面使用不同的事务(起码每次在不同的库里执行,用到的DataSource都不一样)。methodC执行的时候会在tablea{shardValue}表的聚簇索引(主键索引)上面加X锁(写锁)。
然后是methodB,tablebsingle不需要分表,里面的记录和任何userID都没有关系,这样一来每次对tablebsignle进行操作,使用的datasource都是默认的datasource(DB_A),但是inner join里面的查询操作需要从两个数据库四张表获取数据,相应的会在这四张表上面都加锁(主键索引加S锁)。
很显然,对于methodA,数据库层面不可能只用一个事务,毕竟methodC和methodB的操作都会涉及到不同数据库,这样就解释了informationschema.innodbtrx里面会查出来多个事务。然后其实在程序层面也是用到了不同的事务,主要是这样的,这里分库分表用到了summercool这样一个框架,这个框架可以管理不同数据库的事务,也就是说,连接不同数据库程序用到的事务不一样,但是summercool会管理好这些不同的事务,使其对于开发人员来说可以视其操作在一个事务里,即使这操作需要用到不同数据库。这个地方可能有点绕啊,这么来说吧,对于开发人员来说summercool会确保methodA里面的操作具有原子性,即使methodC失败,methodB也会回滚。虽然methodB和methodC会用到不同的事务,但是呢对于开发人员来说这部分是透明的,无须自己管理。有点类似总分的感觉,如下图(三个不同颜色的矩形框表示三个事务),如果还是不懂恕楼主无能,解释不清。summercool的事务管理这部分我并没有去查阅详细代码,adrian看过这部分代码,表示大致是这个样子的。 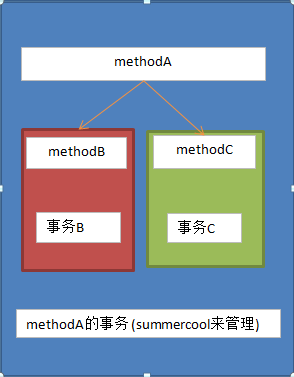
然后默认的autocommit为true,在methodB执行之后,事务并没有提交,那么methodB中的操作在两个数据库四张表上加的S锁并没有释放,而这个时候执行methodC,我们前面提到了,这两个操作并不会使用同样的事务,而这个时候methodC中的操作需要在tablea{shardValue}上面加X锁,那自然无法获取(都被methodB的操作加了S锁),一直被阻塞。
尝试交换methodB和methodC的执行顺序,同样会发生lock time out,但是这种情况下会变成S锁被X锁阻塞。
基本上应该就是这个样子,也算难得的一次经验。
PS:分库分表这种策略在做报表统计的时候,会有很多不方便的地方,因为需要统计的数据在不同表不同datasource里面。