详解kafka架构原理与安装部署
一、什么是kafka
kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
重点内容
二、kafka架构
Kafka内在就是分布式的,一个Kafka集群通常包括多个broker。为了均衡负载,将话题分成多个分区,每个broker存储一或多个分区。多个生产者和消费者能够同时生产和获取消息。
架构中的主要组件解析如下:
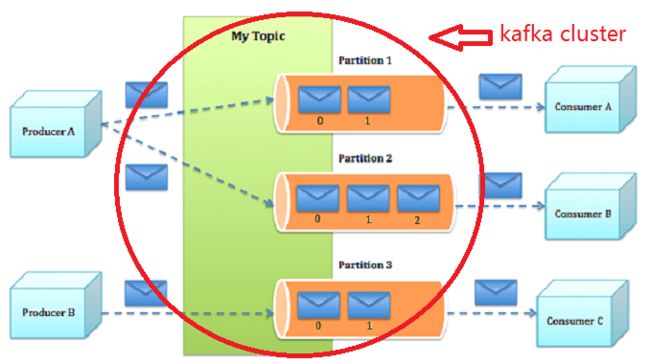
- 话题(Topic)是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名。
- 生产者(Producer)是能够发布消息到话题的任何对象。 已发布的消息保存在一组服务器中,它们被称为Broker或Kafka集群。
- 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
三、kafka存储结构设计
kafka存储布局是在话题的每个分区对应一个逻辑日志。物理上,一个日志为相同大小的一组分段文件。每次生产者发布消息到一个分区,代理就将消息追加到最后一个段文件中。当发布的消息数量达到设定值或者经过一定的时间后,段文件真正写入磁盘中。写入完成后,消息公开给消费者。其结构如下图所示:
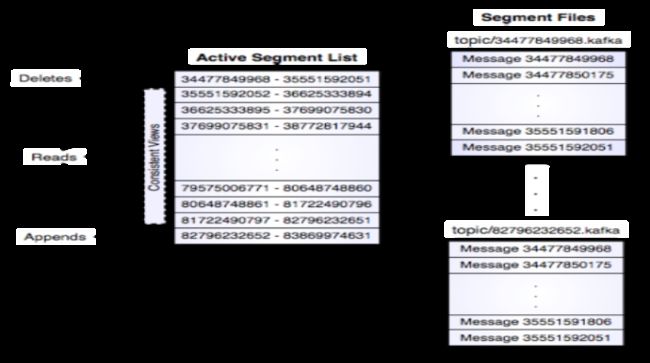
消费者始终从特定分区顺序地获取消息,如果消费者知道特定消息的偏移量,也就说明消费者已经消费了之前的所有消息。消费者向代理发出异步拉请求,准备字节缓冲区用于消费。每个异步拉请求都包含要消费的消息偏移量。Kafka利用sendfile API高效地从代理的日志段文件中分发字节给消费者。
四、kafka 应用代码示例
Kafka生产者代码示例:
public KafkaMailProducer(String topic, String directoryPath) {
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "localhost:9092");
producer = new kafka.javaapi.producer.Producer<Integer, String>(new ProducerConfig(props));
this.topic = topic;
this.directoryPath = directoryPath;
}
public void run() {
Path dir = Paths.get(directoryPath);
try {
new WatchDir(dir).start();
new ReadDir(dir).start();
} catch (IOException e) {
e.printStackTrace();
}
} 上面的代码片断展示了Kafka生产者API的基本用法,例如设置生产者的属性,包括发布哪个话题的消息,可以使用哪个序列化类以及代理的相关信息。这个类的基本功能是从邮件目录读取邮件消息文件,然后作为消息发布到Kafka代理。目录通过java.nio.WatchService类监视,一旦新的邮件消息Dump到该目录,就会被立即读取并作为消息发布到Kafka代理。
Kafka消费者代码示例:
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("zookeeper.connect", KafkaMailProperties.zkConnect);
props.put("group.id", KafkaMailProperties.groupId);
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
public void run() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext())
System.out.println(new String(it.next().message()));
}上面的代码演示了基本的消费者API。正如我们前面提到的,消费者需要设置消费的消息流。在Run方法中,我们进行了设置,并在控制台打印收到的消息。
五、kafka的安装部署
(提示:在安装kafka之前,需要先安装部署zookeeper 集群。请参考:http://blog.csdn.net/u010330043/article/details/51209939)
kafka的安装步骤如下:
步骤一 解压
步骤二 修改server.properties
broker.id=1
zookeeper.connect=cs2:2181,cs3:2181,cs4:2181步骤三 将zookeeper集群启动
步骤四 在每一台节点上启动broker
bin/kafka-server-start.sh config/server.properties步骤五 在kafka集群中创建一个topic
bin/kafka-topics.sh --create --zookeeper weekend05:2181 --replication-factor 3 --partitions 1 --topic order步骤六 用一个producer向某一个topic中写入消息
bin/kafka-console-producer.sh --broker-list weekend:9092 --topic order步骤七 用一个comsumer从某一个topic中读取信息
bin/kafka-console-consumer.sh --zookeeper weekend05:2181 --from-beginning --topic order步骤八 查看一个topic的分区及副本状态信息
bin/kafka-topics.sh --describe --zookeeper weekend05:2181 --topic order参考文献: Apache Kafka: Next Generation Distributed Messaging System