WordCount单词计数详解
1. 环境介绍:Centos6.4,Hadoop-1.1.2,eclipse8.5
2. 刚刚接触mapreduce编程的时候总是不明白它是如何进行分割,如何分组,如何shuffer。尤其会对map函数,reduce函数中的参数类型感到疑惑。
因此自己整理了一下自己对mapreduce程序经典案例单词计数的理解。
3. WordCount单词计数完整代码(其中注释部分为非必须,分区和规约函数也是非必须部分)
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
publicclassWordCount {
staticfinal String INPUT_PATH= "hdfs://192.168.56.171:9000/WordCount/word";
staticfinal String OUT_PATH = "hdfs://192.168.56.171:9000/WordCount/out";
publicstaticvoid main(String[] args) throws IOException,
InterruptedException,ClassNotFoundException, URISyntaxException {
Configurationconf= newConfiguration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH),conf);
final Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
final Job job = new Job(conf, WordCount.class.getSimpleName());
// 打包运行时必须执行的秘密方法
job.setJarByClass(WordCount.class);
// 1 指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入文件进行格式化,把输入文件每一行解析成键值对
// job.setInputFormatClass(TextInputFormat.class);
// 2 指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(LongWritable.class);
// 3 分区
// job.setPartitionerClass(MyPartitioner.class);
// 有一个reduce任务运行
job.setNumReduceTasks(1);
// 4 TODO排序、分组+
// 5 TODO规约
job.setCombinerClass(MyCombiner.class);
// 6 指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 7 指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
// job.setOutputFormatClass(TextOutputFormat.class);
// 把job提交给JobTracker运行
job.waitForCompletion(true);
}
staticclass MyMapper extends
Mapper<LongWritable,Text, Text, LongWritable> {
// LongWritable, Text和Text, LongWritable分别是输入与输出的数据类型
protectedvoid map(LongWritable k1, Text v1, Context context)
// k1指v1的偏移量,v1是指输入的文本数据,有下面的输出语句可得知,
// v1为一行的数据
throws IOException,InterruptedException {
System.out.println("k1=" + k1 + " ,v1="+ v1);
// 把v1转换成String类型,并以空格为分隔,存储在String字符数组中
final String line = v1.toString();
final String[] splited = line.split(" ");
for (String word : splited) {
// 使用context.write将此键值对输出,传递给reduce函数。
// 而且此键值对类型与上面设定的输出的数据类型相同。
context.write(new Text(word), new LongWritable(1L));
System.out.println("Mapper输出<" + word + "," + 1 + ">");
}
};
}
/*
* Combiner的使用,当map生成的数据过大时,可以精简压缩传给Reduce的数据,又不影响最重点数据,
* reduce的输入每个key值所对应的value都是1,这会占用很大的带宽。
* Combiner的使用可以使在map的输出在给于reduce之前做一下合并或计算,把具有相同key的value做一个计算,
* 那么传给reduce的数据就会少很多,减轻了网络压力。
* 通过代码可以看出Combiner是用reducer来定义的,因此多数的情况下Combiner和reduce处理的是同一种逻辑。
* 只是reduce函数在内部完成的计算,通过Combiner的合并计算,使计算效率大大提高。
*/
staticclass MyCombiner extends
Reducer<Text,LongWritable, Text, LongWritable> {
publicvoid reduce(Text k2,Iterable<LongWritable> v2, Context context)
throws IOException,InterruptedException {
// 显示次数表示reduce函数调用了多少次,表示课有多少个分组
System.out.println("Combiner输入分组<" + k2.toString() + ">");
longtimes = 0L;
for (LongWritable count : v2) {
times += count.get();
// 显示次数表示k2,v2的键值对数量
System.out.println("Combiner输入键值对<" + k2.toString() + ","
+count.get()+ ">");
}
context.write(k2, new LongWritable(times));
// 显示次数表示k2,v2的键值对数量
System.out.println("Combiner最终输入键值对<" + k2.toString() + "," + times
+">");
}
}
staticclass MyReducer extends
// Text, LongWritable和Text, LongWritable分别是输入与输出的数据类型
// 且Reducer函数的输入类型对应Mapper函数的输出类型。
Reducer<Text,LongWritable, Text, LongWritable> {
// 将相同的键的值放入到迭代器v2s中进行遍历。
protectedvoid reduce(Text k2,Iterable<LongWritable> v2s, Context ctx)
throws IOException,InterruptedException {
longtimes = 0L;
for (LongWritable count : v2s) {
times += count.get();
System.out.println("Reducer输入键值对<" + k2.toString() + ","
+count.get()+ ">");
}
ctx.write(k2, new LongWritable(times));
};
}
}
4. Word文件内容为:
Deer Bear River
Car Car River
Deer Car Bear
5. Mapreduce对其的处理模式如图
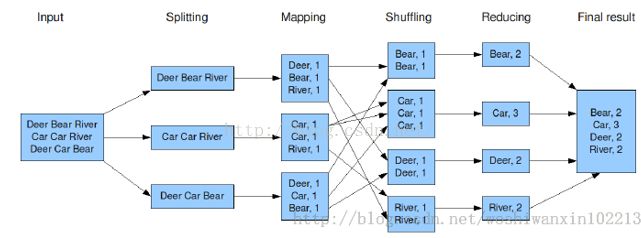
6. 程序运行后输出结果:
Bear 2
Car 3
Deer 2
River 2
7. 通过对程序的修改使输出到eclipse的控制台内容更直观:
7.1Map端输出的内容。
k1=0,v1=Deer Bear River
Mapper输出<Deer,1>
Mapper输出<Bear,1>
Mapper输出<River,1>
k1=16,v1=Car Car River
Mapper输出<Car,1>
Mapper输出<Car,1>
Mapper输出<River,1>
k1=30,v1=Deer Car Bear
Mapper输出<Deer,1>
Mapper输出<Car,1>
Mapper输出<Bear,1>
7.2Combiner端输出的内容。
Combiner输入分组<Bear>
Combiner输入键值对<Bear,1>
Combiner输入键值对<Bear,1>
Combiner最终输入键值对<Bear,2>
Combiner输入分组<Car>
Combiner输入键值对<Car,1>
Combiner输入键值对<Car,1>
Combiner输入键值对<Car,1>
Combiner最终输入键值对<Car,3>
Combiner输入分组<Deer>
Combiner输入键值对<Deer,1>
Combiner输入键值对<Deer,1>
Combiner最终输入键值对<Deer,2>
Combiner输入分组<River>
Combiner输入键值对<River,1>
Combiner输入键值对<River,1>
Combiner最终输入键值对<River,2>
7.2Reducer端输出的内容。
Reducer输入键值对<Bear,2>
Reducer输入键值对<Car,3>
Reducer输入键值对<Deer,2>
Reducer输入键值对<River,2>
通过对控制台输出的内容的理解,可以对mapreduce的计算流程有一个更加清晰的认识。