OpenMP并行化实例----Mandelbrot集合并行化计算
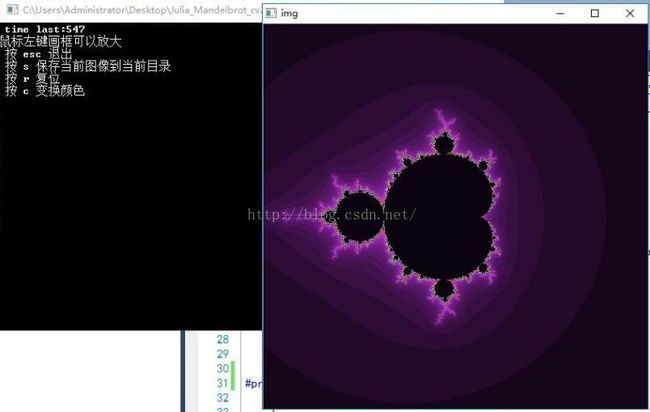
在理想情况下,编译器使用自动并行化能够管理一切事务,使用OpenMP指令的一个优点是将并行性和算法分离,阅读代码时候无需考虑并行化是如何实现的。当然for循环是可以并行化处理的天然材料,满足一些约束的for循环可以方便的使用OpenMP进行傻瓜化的并行。
为了使用自动并行化对Mandelbrot集合进行计算,必须对代码进行内联:书中首次使用自动并行化时候,通过性能分析发现工作在线程中并未平均分配。
#include <stdio.h>
#include <malloc.h>
#define SIZE 4000
int inSet(double ix,double iy)
{
int iterations = 0;
double x = ix,y = iy;
double x2 = x*x, y2 = y*y;
while ((x2 + y2 < 4) && (iterations < 1000))
{
y = 2*x*y + iy;
x = x2 -y2 +ix;
x2 = x*x;
y2 = y*y;
iterations++;
}
return iterations;
}
int main()
{
int *matrix[SIZE];
for (int i = 0; i < SIZE; i++)
{
matrix[i] = (int* )malloc( SIZE*sizeof(int) );
}
#pragma omp parallel for
for (int x = 0 ;x <SIZE; x++)
{
for (int y =0;y <SIZE;y++)
{
double xv = ((double)x -(SIZE/2)) / (SIZE/4);
double yv = ((double)y -(SIZE/2)) / (SIZE/4);
matrix[x][y] = inSet(xv,yv);
}
}
for (int x =0; x<SIZE;x++)
{
for (int y =0;y<SIZE;y++)
{
if (matrix[x][y] == -7)
{
printf(" ");
}
}
}
return 0;
}
当我们看到 分形图的时候应该可以很快的理解负荷不均衡从那里产生,分形图中大部分点不在集合中,这部分点只需要少量的迭代就可以确定,但有些在集合中的点则需要大量的迭代。
当然我再一次见识到了OpenMP傻瓜化的并行操作机制,纠正工作负荷不均衡只要更改并行代码调度子句就可以了,使用动态指导调度,下面代码是增加了OpenCV的显示部分:
#include "Fractal.h"
#include <Windows.h>
#include <omp.h>
int Fractal::Iteration(Complex a, Complex c)
{
double maxModulus = 4.0;
int maxIter = 256;
int iter = 0;
Complex temp(0,0) ;
while ( iter < maxIter && a.modulus() < maxModulus)
{
a = a * a ;
a += c;
iter++;
}
return iter;
}
cv::Mat Fractal::generateFractalImage(Border border, CvScalar colortab[256] )
{
cv::Size size(500,500);
double xScale = (border.xMax - border.xMin) / size.width;
double yScale = (border.yMax - border.yMin) / size.height;
cv::Mat img(size, CV_8UC3);
#pragma omp parallel for schedule(dynamic)
for (int y=0; y<size.height; y++)
{
for (int x=0; x<size.width; x++)
{
double cx = border.xMin + x * xScale;
double cy = border.yMin + y * yScale;
Complex a(0.0, 0.0);
Complex c(cx, cy);
int nIter ;
if (type == MANDELBROT)
{
nIter = Iteration(a, c);
}
else if (type == JUALIA)
{
nIter = Iteration(c, offset);
}
int colorIndex = (nIter) % 255;
cv::Vec3b color;
color.val[0] = colortab[colorIndex].val[0];
color.val[1] = colortab[colorIndex].val[1];
color.val[2] = colortab[colorIndex].val[2];
img.at<cv::Vec3b>(y,x) = color;
}
}
return img;
}
#pragma omp parallel for schedule(dynamic) 子句
schedule子句:
schedule(type[, size]),
参数type是指调度的类型,可以取值为static,dynamic,guided,runtime四种值。其中runtime允许在运行时确定调度类型,因此实际调度策略只有前面三种。
参数size表示每次调度的迭代数量,必须是整数。该参数是可选的。当type的值是runtime时,不能够使用该参数。
动态调度dynamic
动态调度依赖于运行时的状态动态确定线程所执行的迭代,也就是线程执行完已经分配的任务后,会去领取还有的任务。由于线程启动和执行完的时间不确定,所以迭代被分配到哪个线程是无法事先知道的。
当不使用size 时,是将迭代逐个地分配到各个线程。当使用size 时,逐个分配size个迭代给各个线程。
动态调度迭代的分配是依赖于运行状态进行动态确定的,所以哪个线程上将会运行哪些迭代是无法像静态一样事先预料的。
加速结果:
1.放大加速结果

2.未加速时候的放到功能,基本是3-5倍这个水平,也就是相当于台式机cpu 的个数?本人的猜测
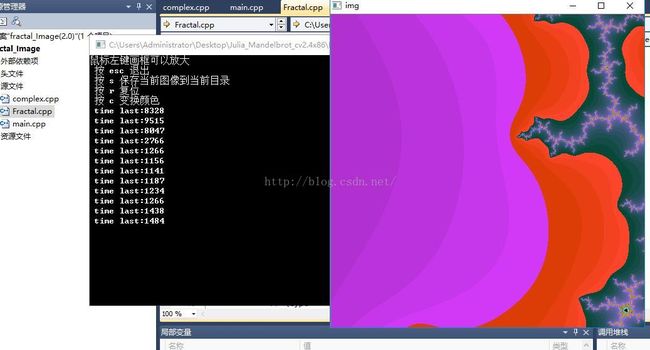
3.图像计算结果(未加速)
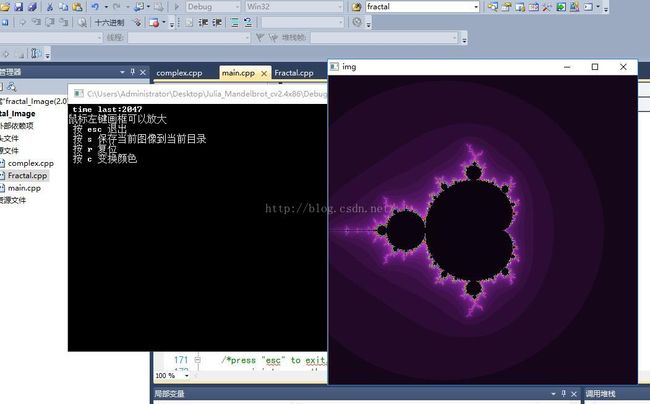
4. 动态加速结果

代码:http://download.csdn.net/detail/wangyaninglm/9516035
参考文献:
http://baike.baidu.com/view/1777568.htm?fromtitle=Mandelbrot%E9%9B%86%E5%90%88&fromid=1778748&type=syn
http://www.cnblogs.com/easymind223/archive/2013/01/19/2867620.html
戈夫. 多核应用编程实战[M]. 人民邮电出版社, 2013.
http://openmp.org/mp-documents/OpenMP3.1-CCard.pdf
http://blog.csdn.net/gengshenghong/article/details/7000979