DeepSRDCF-tracking
介绍DeepSRDCF之前,首先介绍SRDCF。
今天对SRDCF算法做一些笔记[paper:Learning Spatially Regularized Correlation Filters for Visual Tracking]
这篇文章同样是目前比较好的,在VOT2015年的排名第四。他是KCF的一种变形[KCF-SRDCF-DeepSRDCF].下面详细介绍paper.速度4fps.
1.paper 特点
a) 在KCF/DCF基础上改善了boundary effects,加入惩罚项[spatial regularization function that penalizes(惩罚) filter coefficients residing outside the target region].
b) 不同的scale搜索,处理尺度的问题。
c) 在求解corelation filters时,利用iterative Gauss-Seidel method在线学习。
2. details
a) 目的: 从一组train samples中学习一个corralation filter[DCF算法,paper中利用的是circular struct+FFT加速运算]。
b) 由于标准的DCF有许多缺点[boundary effects,容易over-fitting,Score离center远时较差。。。]所以本文在此有所改进,那么标准的DCF是怎样的呢?标准的DCF就是一个监督学习,学习一个linear classifier&linear regressor,可是SVM等也是同样的思想,两者最大的不同在于DCF利用的时circular correlation 来training and detection.circular correlation filters的两大优势为:第一,训练样本多样化(有各种样本的平移【KCF】);第二,FFT加速运算,适用于online-tracking.
标准的DCF原理如下:
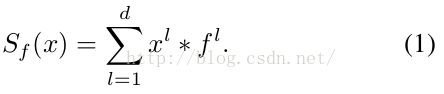
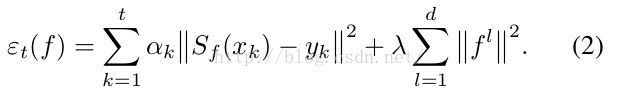
首先式(1)中,S为响应值,X为search region中的特征,f为学习的filters系数,‘*’表示循环卷积[可以参见KCF原理],式(2)为loss function,然后利用循环矩阵来求解[详细参见KCF算法], 缺点循环卷积带来boundary effects:

c) 提出SRDCF算法,在DCF的基础上添加正则化项:空间权重函数(惩罚项,w),将式(2)的式子修改如下:
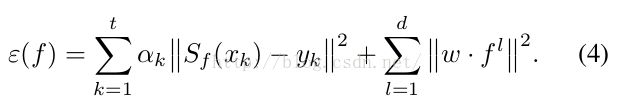
其中惩罚权重w满足(负)Gauss分布,超过边界的w更大,表示惩罚越大[注意不是label中的高斯分布,不要弄混淆了],所以归一化后,loss function如下:

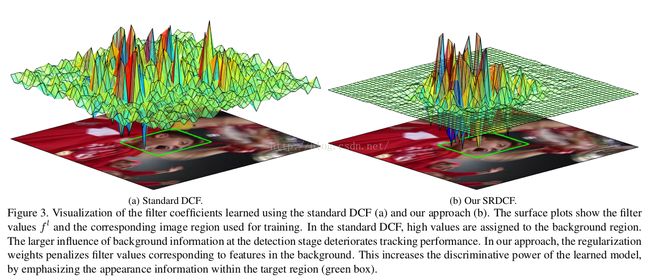
对式(5),利用FFT和循环矩阵的性质进行计算,这样学习到的滤波系数可视化对比如下:
最终求解等价于求解线性方程组
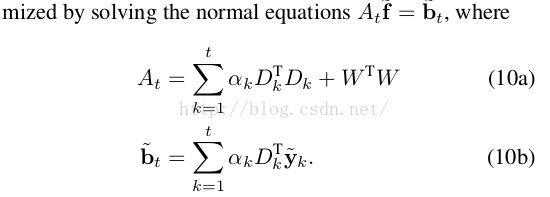
由于采用circular 算法,某些等式可以简化,所以提出Gauss-seidel method来简化【略】。
d) 有了上面的求解,那么在跟踪的时候,根据第一帧的ground-truth,就可以进行训练,迭代等式如下(第一帧的信息可以求迭代需要的初始化的值):
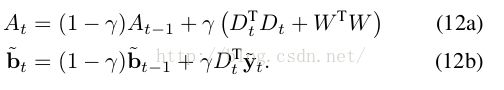
e) 训练好了后,用于detection,the location of the target in a new frame t is estimated by applying the filter f ˆ t−1 that has been updated in the previous frame,首先,we apply the filter at multiple resolutions to estimate changes in the target size.则选择一定的候选框,并做放缩处理,最后crop为同样的size[作为循环矩阵的输入].
f) 搜索采用Sub-grid策略,即用t-1的滤波系数,滑动step>1pixel,这样根据score,大致定位(可以考虑金字塔策略),再在频域,对每一个尺度,利用如下公式迭代求解最佳匹配的位置:
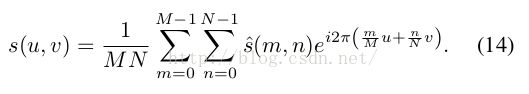
g) 文章最后利用了多种特征。In addition to the HOG features used in [12], the submitted variant of SRDCF also employs Colour Names and greyscale features. These features are averaged over the 4 × 4 HOG cells and then concatenated, giving a 42 dimensional feature vector at each cell
DeepSRDCF[Convolutional Features for Correlation Filter Based Visual Tracking]
他是在SRDCF的基础上,将hand-crafted的特征换为CNN的特征,作者并没有公布源代码,是基于Matconvnet来做的。
1. paper特点
1)探索了不同conv的特征的不同影响,得出利用第一层conv的特征效果最好。
2)利用PCA将第一层的特征降为40-D: the DeepSRDCF employs convolutional features from a pre-trained network.A Principal Component Analysis is used to reduce the feature dimensionality of the extracted activations。