Linux内核链表深度分析
链表简介:
链表是一种常用的数据结构,它通过指针将一系列数据节点连接成一条数据链。相对于数组,链表具有更好的动态性,建立链表时无需预先知道数据总量,可以随机分配空间,可以高效地在链表中的任意位置实时插入或者删除数据。链表的开销主要是访问的顺序性和组织链的空间损失。
1. 链表对比
传统链表和内核链表
传统链表:一般指的是单向链表
struct List
{
struct list *next;//链表结点指针域
};
内核链表:双向循环链表 设计初衷是设计出一个通用统一的双向链表!
struct list_head
{
struct list_head *head, *prev;
};
list_head结构包含两个指向list_head结构体的指针
prev和next,由此可见,内核的链表具备双链表功能,实际上,通常它都组织成双向循环链表
2. 内核链表使用
1. INIT_LIST_HEAD:创建链表
2. list_add:在链表头插入节点
3. list_add_tail:在链表尾插入节点
4. list_del:删除节点
5. list_entry:取出节点
6. list_for_each:遍历链表
(如果我们不知道这些函数的参数以及函数内部实现,学习查阅这些函数的参数或者实现代码最好的方法还是直接查看内核源码,结和前面的用sourceInsight工具直接搜索这些函数的名字)
下面举个例子:比如查阅INIT_LIST_HEAD函数,
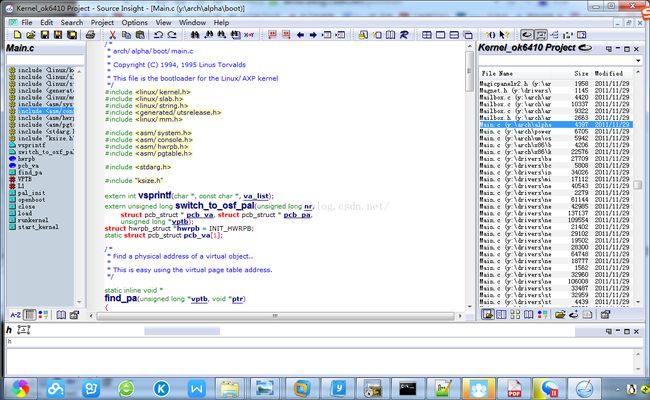
这个是先将内核源码导入sourceInsight工程里面!源码可以在官网上下载,然后在Linux下解压(文件名Linux分大小写,windows不分大小写),然后通过Samba和映射网络驱动器功能(前面的sourceInsight博文有讲到),点击R图标左边的那个图标(像一个打开的一本书)

这样可以很快的查看到代码实现部分:在内核Mkregtale.c文件中
/*
* This is a simple doubly linked list implementation that matches the
* way the Linux kernel doubly linked list implementation works.
*/
struct list_head {
struct list_head *next; /* next in chain */
struct list_head *prev; /* previous in chain */
};
这个不含数据域的链表,可以嵌入到任何数据结构中,例如可按如下方式定义含有数据域的链表:
struct score
{
int num;
int English;
int math;
struct list_head list;//链表链接域
};
struct list_head score_head;//所建立链表的链表头
INIT_LIST_HEAD(&score_head);//初始化链表头 完成一个双向循环链表的创建
上面的红色部分初始化一个已经存在的list_head对象,score_head为一个结构体的指针,这样可以初始化堆栈以及全局区定义的score_head对象。调用INIT_LIST_HEAD()宏初始化链表节点,将next和prev指针都指向其自身,我们就构造了一个空的双循环链表。
初始化一个空链表:其实就是链表头,用来指向第一个结点!定义结点并且初始化!然后双向循环链表就诞生了
/* Initialise a list head to an empty list */
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
list_add:在链表头插入节点
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif
list_add_tail:在链表尾插入节点
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
用法示例:
struct score
{
int num;
int English;
int math;
struct list_head list;//链表链接域
};
struct list_head score_head;//所建立链表的链表头
//定义三个节点 然后插入到链表中
struct score stu1, stu2, stu3;
list_add_tail(&(stu1.list), &score_head);//使用尾插法
Linux 的每个双循环链表都有一个链表头,链表头也是一个节点,只不过它不嵌入到宿主数据结构中,即不能利用链表头定位到对应的宿主结构,但可以由之获得虚拟的宿主结构指针。
list_del:删除节点
/* Take an element out of its current list, with or without
* reinitialising the links.of the entry*/
static inline void list_del(struct list_head *entry)
{
struct list_head *list_next = entry->next;
struct list_head *list_prev = entry->prev;
list_next->prev = list_prev;
list_prev->next = list_next;
}
list_entry:取出节点
/**
* list_entry - get the struct for this entry
* @ptr:the &struct list_head pointer.
* @type:the type of the struct this is embedded in.
* @member:the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
list_for_each:遍历链表
#define list_for_each(pos, head) \
for (pos = (head)->next; prefetch(pos->next), pos != (head); \
pos = pos->next)</span></span>
struct score stu1, stu2, stu3;
struct list_head *pos;//定义一个结点指针
struct score *tmp;//定义一个score结构体变量
//遍历整个链表,每次遍历将数据打印出来
list_for_each(pos, &score_head)//这里的pos会自动被赋新值
{
tmp = list_entry(pos, struct score, list);
printk(KERN_WARNING"num: %d, English: %d, math: %d\n", tmp->num, tmp->English, tmp->math);
}
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos:the &struct list_head to use as a loop cursor.
* @n:another &struct list_head to use as temporary storage
* @head:</span>the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
3. 内核链表实现分析

4. 移植内核链表(这里先贴出一个使用内核链表的内核模块小例程)
mylist.c文件
#include<linux/module.h>
#include<linux/init.h>
#include<linux/list.h>//包含内核链表头文件
struct score
{
int num;
int English;
int math;
struct list_head list;//链表链接域
};
struct list_head score_head;//所建立链表的链表头
//定义三个节点 然后插入到链表中
struct score stu1, stu2, stu3;
struct list_head *pos;//定义一个结点指针
struct score *tmp;//定义一个score结构体变量
int mylist_init()
{
INIT_LIST_HEAD(&score_head);//初始化链表头 完成一个双向循环链表的创建
stu1.num = 1;
stu1.English = 59;
stu1.math = 99;
//然后将三个节点插入到链表中
list_add_tail(&(stu1.list), &score_head);//使用尾插法
stu2.num = 2;
stu2.English = 69;
stu2.math = 98;
list_add_tail(&(stu2.list), &score_head);
stu3.num = 3;
stu3.English = 89;
stu3.math = 97;
list_add_tail(&(stu3.list), &score_head);
//遍历整个链表,每次遍历将数据打印出来
list_for_each(pos, &score_head)//这里的pos会自动被赋新值
{
tmp = list_entry(pos, struct score, list);
printk(KERN_WARNING"num: %d, English: %d, math: %d\n", tmp->num, tmp->English, tmp->math);
}
return 0;
}
void mylist_exit()
{
//退出时删除结点
list_del(&(stu1.list));
list_del(&(stu2.list));
printk(KERN_WARNING"mylist exit!\n");
}
module_init(mylist_init);
module_exit(mylist_exit);
Makefile文件
obj-m := mylist.o KDIR := /home/kernel/linux-ok6410 all: make -C $(KDIR) M=$(PWD) modules CROSS_COMPILE=arm-linux- ARCH=arm clean: rm -f *.o *.ko *.order *.symvers

在终端上加载运行内核模块:
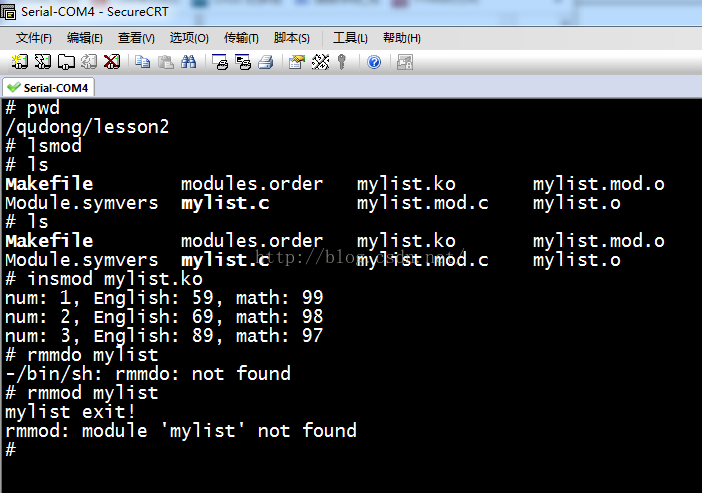
这里rmmod 时会有个错误!不过没大事!百度有很多解决方案!