opencv中detectMultiScale函数的使用
HOGDescriptor::detectMultiScale(const GpuMat& img, vector<Rect>& found_locations, doublehit_threshold=0, Size win_stride=Size(), Size padding=Size(), double scale0=1.05, int group_threshold=2)
该函数表示对输入的图片img进行多尺度行人检测 img为输入待检测的图片;
found_locations为检测到目标区域列表;
参数3为程序内部计算为行人目标的阈值,也就是检测到的特征到SVM分类超平面的距离;
参数4为滑动窗口每次移动的距离。它必须是块移动的整数倍;
参数5为图像扩充的大小;
参数6 :scale0为比例系数,即被检测图像每一次被压缩的比例,这个可以从OPENCV的hog.cpp源文件中看出:
for( levels = 0; levels < nlevels; levels++ )
{
//若待检测图像的尺寸小于检测窗口的尺寸,则停止检测
levelScale.push_back(scale);
if( cvRound(img.cols/scale) < winSize.width ||
cvRound(img.rows/scale) < winSize.height ||
scale0 <= 1 )
break;
scale *= scale0;
}
之前一直理解的是检测窗口会不断的按照比例系数放大,其实检测窗口是固定不变的,是待检测图像按照比例系数缩小。
参数7为组阈值,即校正系数,当一个目标被多个窗口检测出来时,该参数此时就起了调节作用,为0时表示不起调节作用。
最后对检测出来的目标矩形框,要采用一些方法处理,比如说2个目标框嵌套着,则选择最外面的那个框。 因为hog检测出的矩形框比实际人体框要稍微大些,所以需要对这些矩形框大小尺寸做一些调整。
在进行交通灯检测的程序编写中,经过各种调整,还是使用detectMultiScale(src, found,0,Size(8,8), Size(32,32), 1.05, 2)最终通过了,其他的参数一直报错。其中第五个参数为Size(0,0)时,检测出的矩形框数量为65个,Size(32,32)时检测出的矩形框为83个,调整为Size(64,64)后检测到的矩形框增加为109个,说明这个参数的尺寸越大,好像检测量越大,检测出的矩形框越多。暂时是这么认为的,以后想清楚了再来更新吧。
下面的一组实验结果是对第4个参数的理解,第四个参数越大,检测窗口移动的步长越大,检测的目标个数越小。(检测是在训练样本数量很少的情况下完成的,提高训练样本数量可以增加检测的精度)
下图是参数为detectMultiScale(src, found,0,Size(4,4), Size(0,0), 1.05, 2)的检测结果,矩形框个数为38个
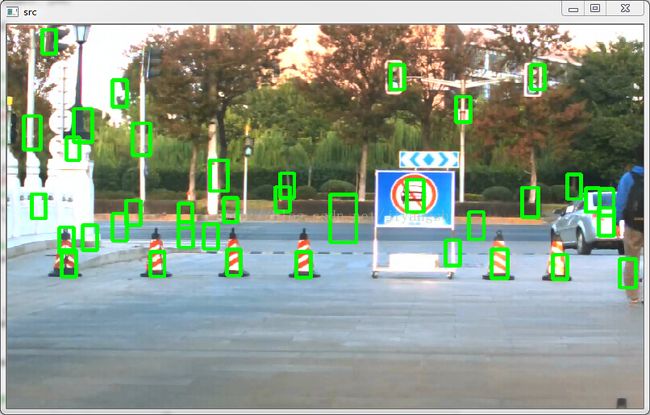
下图是参数为detectMultiScale(src, found,0,Size(16,16), Size(0,0), 1.05, 2)的检测结果,矩形框个数为88个

当第4个参数为Size(64,64)时,检测窗口仅为12个。detectMultiScale(src, found,0,Size(32,32), Size(0,0), 1.05, 2)

继续写更新对于HOG函数的理解:
HOGDescriptor myHOG(Size(15,30),Size(5,10),Size(5,5),Size(5,5),9,1,-1.0,0,0.2,true,64);发现将第一个参数(即检测窗口的尺寸)设置的较小时可以检测到更小的目标,待检测的目标的尺寸要至少大于检测窗口的尺寸才可以被检测到。
滑动窗口的步长(第3个参数)设置的较小时也可以增加检测精度。