字符串匹配(KMP 算法 含代码)
主要是针对字符串的匹配算法进行讲解
- 有关字符串的基本知识
- 传统的串匹配法
- 模式匹配的一种改进算法KMP算法
- 网上一比较易懂的讲解
- 小例子
- 1计算next
- 2计算nextval
- 代码
有关字符串的基本知识
串(string或字符串)是由零个或多个字符组成的有限序列,一般记为![]() 其中s是串的名,用单引号括起来的字符序列是串的值;ai(1<=i<=n)可以是字母、数值或其他字符;串中字符的数组 n称为串的长度。零个字符的串称为空串,它的长度为0
其中s是串的名,用单引号括起来的字符序列是串的值;ai(1<=i<=n)可以是字母、数值或其他字符;串中字符的数组 n称为串的长度。零个字符的串称为空串,它的长度为0
串中任意个连续的字符组成的子序列称为该串的子串。包含子串的串相应的称为主串。通常称字符在序列中的序号为该字符在串中的位置。子串在主串中的位置则以子串的第一个字符在主串中的位置来表示。
下面主要说一下串的模式匹配算法
传统的串匹配法
算法的基本思想是:从主串S的第pos个字符起和模式的第一个字符比较,若相等,则继续逐个比较后续字符;否则从主串的下一个字符起再重新和模式的字符比较。依次类推,直至模式T中的每个字符依次和主串S中的一个连续的字符序列相等,则匹配成功,函数值为和模式T中第一个字符相等的字符在主串S中的序号,否则称匹配不成功,函数值为零。
此算法在最坏情况下的时间复杂度为O(m*n)
模式匹配的一种改进算法(KMP算法)
网上一比较易懂的讲解
字符串匹配的KMP算法
字符串匹配是计算机的基本任务之一。
举例来说,有一个字符串”BBC ABCDAB ABCDABCDABDE”,我想知道,里面是否包含另一个字符串”ABCDABD”?
许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。
下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.
首先,字符串”BBC ABCDAB ABCDABCDABDE”的第一个字符与搜索词”ABCDABD”的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.
就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.
接着比较字符串和搜索词的下一个字符,还是相同。
5.
直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把”搜索位置”移到已经比较过的位置,重比一遍。
7.

一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是”ABCDAB”。KMP算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.

已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符B对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2(”AB”),对应的”部分匹配值”为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
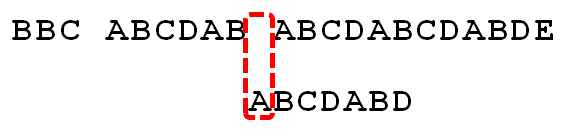
因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:”前缀”和”后缀”。 “前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
15.
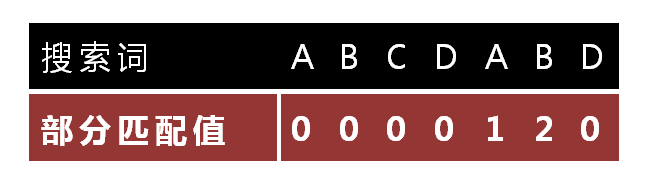
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
- “A”的前缀和后缀都为空集,共有元素的长度为0;
- “AB”的前缀为[A],后缀为[B],共有元素的长度为0;
- “ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- “ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- “ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为1;
- “ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,长度为2;
- “ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.

“部分匹配”的实质是,有时候,字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么它的”部分匹配值”就是2(”AB”的长度)。搜索词移动的时候,第一个”AB”向后移动4位(字符串长度-部分匹配值),就可以来到第二个”AB”的位置。
小例子
求字符串 ‘ababaabab’的next和nextval,结果如下
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| s[ j ] | a | b | a | b | a | a | b | a | b |
| next | 0 | 1 | 1 | 2 | 3 | 4 | 2 | 3 | 4 |
| nextval | 0 | 1 | 0 | 1 | 0 | 4 | 1 | 0 | 1 |
(1)计算next
计算next的时候需要遵循的规则如下
A、 j = 0 next[j] = 0
B、如果存在 Max{ k | k 属于 (1,j-1) 且‘P1…Pk-1’= ‘Pj-k+1…Pj-1’ } (next[j] = k)
C、其他情况 next[j] = 1
| j | ( 1, k-1 ) | str(1,k-1) | ( j-k+1 , j-1 ) | str( j-k+1, j-1) | 规则 | next[ j ] |
|---|---|---|---|---|---|---|
| 2 | NULL | NULL | NULL | NULL | C | 1 |
| 3 | (1,1) | a | (2,2) | b | C | 1 |
| 4 | (1,2) | ab | (2,3) | ba | ||
| 4 | (1,1) | a | (3,3) | a | B | 2 |
| 5 | (1,3) | aba | (2,4) | bab | ||
| 5 | (1,2) | ab | (3,4) | ab | B | 3 |
| 6 | (1,4) | abab | (2,5) | baba | ||
| 6 | (1,3) | aba | (3,5) | aba | B | 4 |
| 7 | (1,5) | ababa | (2,6) | babaa | ||
| 7 | (1,4) | abab | (3,6) | abaa | ||
| 7 | (1,3) | aba | (4,6) | baa | ||
| 7 | (1,2) | ab | (5,6) | aa | ||
| 7 | (1,1) | a | (6,6) | a | B | 2 |
| 8 | (1,6) | ababaa | (2,7) | babaab | ||
| 8 | (1,5) | ababa | (3,7) | abaab | ||
| 8 | (1,4) | abab | (4,7) | baab | ||
| 8 | (1,3) | aba | (5,7) | aab | ||
| 8 | (1,2) | ab | (6,7) | ab | B | 3 |
| 9 | (1,7) | ababaab | (2,8) | babaaba | ||
| 9 | (1,6) | ababaa | (3,8) | abaaba | ||
| 9 | (1,5) | ababa | (4,8) | baaba | ||
| 9 | (1,4) | abab | (5,8) | aaba | ||
| 9 | (1,3) | aba | (6,8) | aba | B | 4 |
(2)计算nextval
nextval[i]的求解需要比较s中next[i]所在位置的字符是否与s[i]的字符一致,如果一致则用s[next[i]]的nextval的值作为nextval[i],如果不一致,则用next[i]做为nextval[i]。
| i | next[i] | s[i] | s[ next[i] ] | yes/no | nextval[i] |
|---|---|---|---|---|---|
| 1 | 0 | a | NULL | no | next[i] = 0 |
| 2 | 1 | b | a | no | next[i] = 1 |
| 3 | 1 | a | a | yes | s[ next[i] ]的nextval = 0 |
| 4 | 2 | b | b | yes | s[2]nextval = 1 |
| 5 | 3 | a | a | yes | s[2]nextval = 0 |
| 6 | 4 | a | b | no | next[6] = 4 |
| 7 | 2 | b | b | yes | s[2] nextval = 1 |
| 8 | 3 | a | a | yes | s[3] nextval = 0 |
| 9 | 4 | b | b | yes | s[4]nextval = 1 |
代码
该代码参考 数据结构(C语言版) 严蔚敏 吴伟民 编著。。。
/** * @filename kmp.cc * @Synopsis KMP algorithm * @author XIU * @version 1 * @date 2016-04-21 */
// 此代码中所用的数组,或者是字符串都是从下标1开始
#include<iostream>
#include<string.h>
using namespace std;
/* ============================================================================*/
/** * @Synopsis the next index data of the model string s_mode * * @Param s_mode: the string * @Param next : the next array * @Param len : the length of the string */
/* ============================================================================*/
void get_next( string s_mode, int *next, int len )
{
int i = 1;
int j = 0;
next[1] = 0;
//cout << len << endl;
while( i<len )
{
if( j==0 || s_mode[i] == s_mode[j] )
{
++i;
++j;
if( i>len ) break;
next[i] = j;
if( j>len ) break;
//下面的是修正的next算法(nextval)。
/* if( s_mode[i] != s_mode[j]) next[i] = j; else next[i] = next[j]; */
}
else
{
j = next[j];
}
}
for( int i=1; i<len; i++ )
{
cout << next[i] << " ";
}
cout << endl;
}
/* ============================================================================*/
/** * @Synopsis 利用模式串s_mode中的next函数求s_model在主串 s_primary中第pos个字符之后的位置 * * @Param s_primary * @Param s_mode * @Param pos * @Param next * * @Returns */
/* ============================================================================*/
int Index_KMP( string s_primary, string s_mode, int pos, int *next )
{
int i = pos;
int j = 1;
int len_p = s_primary.size();
int len_m = s_mode.size();
while( i < len_p && j < len_m )
{
if( j == 0 || s_primary[i] == s_mode[j] )
{
++i;
++j;
}
else
j = next[j];
}
if( j >= len_m )
return i - len_m;
else
return 0;
}
/* ============================================================================*/
/** * @Synopsis output function to check the result * * @Param s_primary * @Param s_mode * @Param len * @Param next * @Param index */
/* ============================================================================*/
void output( string s_primary, string s_mode, int len, int *next, int index )
{
cout << "s_primary = " << s_primary << endl;
cout << "s_mode = " << s_mode << endl;
for( int i=1; i<len; i++ )
{
cout << next[i] << " ";
}
cout << endl;
cout << "index = " << index << endl;
}
int main()
{
string s_primary = " acabaabaabcacaabc";
string s_mode = " abaabcac";
int len = s_mode.size() ;
int *next = new int[len];
get_next( s_mode, next, len );
int tmp = Index_KMP( s_primary, s_mode, 1, next );
output( s_primary, s_mode, len, next, tmp );
delete [] next;
return 0;
}参考网址
【1】字符串匹配的KMP算法 - 阮一峰的网络日志
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
【2】KMP算法详解 - joylnwang的专栏 - 博客频道 - CSDN.NET
http://blog.csdn.net/joylnwang/article/details/6778316
【3】经典算法研究系列:六、教你初步了解KMP算法、updated - 结构之法 算法之道 - 博客频道 - CSDN.NET
http://blog.csdn.net/v_JULY_v/article/details/6111565