推荐系统中的相似度计算方法总结
相似度的计算是推荐系统非常重要的环节,包括:用户与用户之间的相似度,物品与物品之间的相似度或者用户与物品的相关性。
下面以在协同过滤中计算两个用户的相似度来介绍几种常用的相似度计算方法。其中有些方法只适用于协同过滤,有些适应于更多其他推荐方法。
1)共同邻居。直接计算两个用户的交集
![]()
2)Jaccard系数。基于共同邻居的一个显著问题是用户的物品集越大,越可能与其他用户相似。Jaccard系数消除了这一影响:

3)皮尔逊相关系数。皮尔逊相关系数法是基于用户的协同过滤中最常使用的相似度计算方法。研究表明,在计算用户相似度方面,皮尔逊相关系数法比其他相似度计算方法要好一些。具体定义如下:
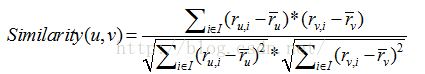
其中I表示用户u和v共同评价过的物品,![]() 表示u对i的评分,
表示u对i的评分,![]() 表示u所有评价的物品的平均分。
表示u所有评价的物品的平均分。
4)约束的皮尔逊相关系数。与皮尔逊相关系数的唯一区别是将![]() 换成
换成![]() ——系统评分值域的中间值。
——系统评分值域的中间值。

5)向量余弦法。向量余弦法最常被应用在基于物品的协同过滤和基于内容的推荐方法中。在基于内容的推荐中,物品用向量模型表示,计算两个物品的相似度相当于计算代表两个物品的向量的余弦值。向量余弦法的数学描述如下:
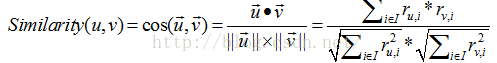
除了上面介绍的相似度计算方法外,常见的方法还包括斯皮尔曼相关系数法(SRC)以及其他改进算法,具体见文献[1,2]。
【参考文献】
[1] Breese, D. Heckerman, C. Kadie. Empirical analysis of predictive algorithms for collaborative filtering. In:Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence. Madison: Morgan-Kaufmann,1998,43-52.
[2] X. Su,T. M. Khoshgoftaar. A survey of collaborative filtering techniques. Advances in Articial Intelligence,2009,2009(4):1-19.