利用pyhton 生成PDF文件
这次利用python的reportlab 和 mathplotlib 生成一个月报PDF 脚本,每月执行一次,自动邮件发给各个项目,我的思路是利用matplotlib将数据库中的数据获取制成jpeg格式的图片,然后读入PDF文件(我要作的图是曲线图,reportlab好像这块不是很强,我也没了解深入,或许有,我不知道)首先我会生成一个pagetemplate,包含有很多Frame,Frame就是一个长宽一定的区域,里面你可以填充很多flowables,表格,图片,文本段,模板制定以后就是渲染数据,最终生成PDF然后邮件附件发出去。
略微说下reportlab:
建议先看下reportlab user guide 重点看下第5章,使用他的高级接口制作,一定要先了解下图的意思
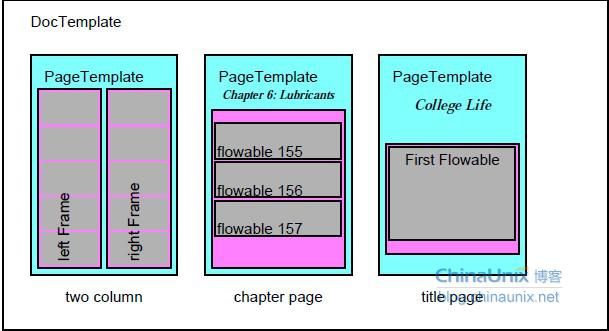
其他我好像没有什么要说的啦,搞清楚这张图,好好看第5章再加google看一些示例代码基本都能搞定,至于matplotlib我推荐看网址 http://hyry.dip.jp:8000/pydoc/matplotlib_intro.html 例子很多基本没有问题,主要是我对图片的制作要求不是很高吧,如果需要更精美的图片,自行去研究吧,不说了,上代码,不足之处是肯定有的,我个人觉得代码的可用性不是很高,很多都是可以加以优化方便扩展的,但是各取所需吧,脚本分为三个大类,制作图片,收集数据,生成PDF
先看制作图片的:
DrawPic.py
点击(此处)折叠或打开
- #! /usr/bin/python
- #coding:utf-8
- import matplotlib
- import datetime
- import numpy as np
- from numpy import arange
- import matplotlib.pyplot as plt
- from matplotlib.dates import DayLocator, HourLocator, DateFormatter, drange
- #######设置字体########
- cnfont = matplotlib.font_manager.FontProperties(fname='/homexxx/stsong.ttf')
-
- class drawpic:
- '''用来生成图片'''
- def __init__(self,data=[],name='',sdate='',edate=''):
- self.sdate=sdate #起始日期
- self.edate=edate #结束日期
- self.data=data # 做图数据列表集合
- self.name=name
- self.start_list=self.sdate.split('-')
- self.end_list=self.edate.split('-') #由于drange的关系,需要取前一天日期
- self.k=datetime.datetime(int(self.end_list[0]),int(self.end_list[1]),int(self.end_list[2]))+ datetime.timedelta(1)
-
- def _Gpic(self,xlabel,ylabel,title):
- '''xlabel 表示x轴的标签
- ylabel 表示y轴的标签
- start 起始日期
- end 结束日期
- '''
-
- plt.figure(figsize=(8,2.5))
- #设定x轴
- #date1 = datetime.datetime( self.year,self.month, self)
- date2 = datetime.datetime(self.k.year,self.k.month,self.k.day)
- date1 = datetime.datetime(int(self.start_list[0]),int(self.start_list[1]),int(self.start_list[2]))
- delta = datetime.timedelta(hours=24) #设置副刻度每小时间隔
- dates=drange(date1,date2,delta) #x 轴
- ax = plt.gca()
- ax.plot_date(dates,self.data,linestyle='-',color="blue",marker='o')
- ax.set_xlabel(xlabel) #设置坐标轴名称
- ax.set_ylabel(ylabel)
- ax.set_title(title,fontproperties=cnfont,fontsize=14)
- #plt.ylim() 设置坐标轴范围
- #plt.xlim()
- plt.subplots_adjust(bottom = 0.15)
- plt.grid() #打开网格
- ax.xaxis.set_major_locator( DayLocator() )
- ax.xaxis.set_minor_locator( HourLocator(arange(0,25,1)) )
- ax.xaxis.set_major_formatter( DateFormatter('%d') )
- for label in ax.xaxis.get_ticklabels():
- label.set_rotation(45) #设置标签倾斜45度
- ax.fmt_xdata = DateFormatter('%Y-%m-%d %H:%M:%S')
- plt.savefig(self.name)
这段比较简单就是按data格式按照时间轴制作图片,给相应的标题,X轴名称,Y轴名称,不加累述了
收集数据类:
本段我认为是该脚本的最难的地方,要将数据库中的东西转化为特定的数据格式,注释中有描述,上代码
GerData.py
最后一个脚本生成PDF的脚本:
点击(此处)折叠或打开
- #!/usr/bin/python
- #coding:utf-8
- #
- import MySQLdb
- from DrawPic import drawpic
- import calendar
- import subprocess
- import time
- import datetime
-
- class GatherData:
- '''
- 这个类主要用来收集数据,通过链接mysql数据库
- '''
- def __init__(self,host,dbname,user,passwd):
- '''
- 初始化mysql连接
- '''
- self.host=host
- self.dbname=dbname
- self.user=user
- self.passwd=passwd
- self.conn=MySQLdb.connect(host=self.host,db=self.dbname,user=self.user,passwd=self.passwd)
- self.cursor=self.conn.cursor()
-
- def date_range(self,start,end):###列出2个日期间的所有天数
- r = (end+datetime.timedelta(days=1)-start).days
- return [start+datetime.timedelta(days=i) for i in range(r)]
-
- def _construct(self,stard,endd):
-
- '''
- 生成数据处理list,下面是demo
- [{dep:'xx',pro:'xxx',email:'xxx@xxx.com',data:{'cost':data1,'loadim':xx.jpeg,'cdntraim':xx2.jpeg,'idctraim':xx3.jpeg,'events':data2}]
- ...
- ]
- '''
- arr=[]
- D={} #数据字典
- d={} #临时字典
- m=[] #当月天数
- d1={} #临时字典
- d_evs={} #统计事件的临时字典
- g={} #统计时间临时字典
- startstamp=time.mktime(time.strptime(stard,'%Y-%m-%d')) #起始时间戳
- endstamp=time.mktime(time.strptime(endd,'%Y-%m-%d'))#结束时间戳
- sql_1='''
- select a.f_name as dep ,b.f_name as project,c.type,c.num,c.sum from t_department a,t_project b,
- (select f_depart_id,f_project_id,f_costing_type as type ,sum(f_costing) as sum,count(*) as num from t_costing_daily
- where f_date between '%s' and '%s' group by f_project_id,f_costing_type) c
- where c.f_depart_id=a.f_depart_id and c.f_project_id=b.f_pro_id ''' % (stard,endd) #部门与项目的对应关系,已经成本费用所占比例
-
- sql_2='''
- select a.f_name as dep ,b.f_name as project,c.num,c.f_date from t_department a,t_project b,(select f_depart_id,f_project_id,sum(f_flow_num) as num ,f_date from t_flows where f_type=2 and f_date between '%s' and '%s' group by f_project_id,f_date) c where c.f_depart_id=a.f_depart_id and c.f_project_id=b.f_pro_id ''' %(stard,endd) #计算CDN 流量
-
- sql_3='''
- select a.f_name as dep ,b.f_name as project,c.num,c.f_date from t_department a,t_project b,
- (select f_depart_id,f_project_id,sum(f_flow_num) as num ,f_date from t_flows where f_type=3 and f_date between '%s' and '%s' group by f_project_id,f_date) c
- where c.f_depart_id=a.f_depart_id and c.f_project_id=b.f_pro_id ''' % (stard,endd)#计算主机IDC流量
-
- sql_4='''
- select b.f_name as dep,a.f_name as project,c.avgload,c.f_date from t_project a,t_department b,
- (select f_project_id,(sum(f_avg_load)/count(*)) as avgload,f_date from t_load_daily where f_date between '%s' and '%s' group by f_project_id,f_date order by f_date) c
- where c.f_project_id=a.f_pro_id and a.f_depart_id=b.f_depart_id ''' % (stard,endd)#计算每个月的项目负载
-
- sql_5='''select c.f_name,a.f_occur_time from t_accident a,test_db_kingnet_oa.t_source b,test_db_kingnet_oa.t_project c where a.f_project=f_num and c.f_pro_id=b.f_pro_id and a.f_occur_time >%s and a.f_occur_time < %s ''' % (startstamp,endstamp)
-
- #本月天数
- #c=calendar.Calendar()
- #dates=c.itermonthdates(2012,3)
- #for date in dates:
- # if str(date).startswith('2012-03'):
- # m.append(date)
- st=stard.split('-')
- en=endd.split('-')
- start=datetime.date(int(st[0]),int(st[1]),int(st[2]))
- end=datetime.date(int(en[0]),int(en[1]),int(en[2]))
- m=self.date_range(start,end)
-
-
- #分别执行sql语句生成数据
- #本段生成成本数据
- self.cursor.execute(sql_1)
- rows=self.cursor.fetchall()
- for i in rows:
- try:
- d[i[0:2]].append(list(i)[2::])
- except KeyError,e:
- d[i[0:2]]=[]
- d[i[0:2]].append(list(i)[2::])
- for k,v in d.items():
- D[k]=[{'cost':v}]
-
- d={} #置空临时字典
- #本段生成CDN流量
- self.cursor.execute(sql_2)
- rows=self.cursor.fetchall()
- for r in rows:
- try:
- d[r[0:2]].append(r[2])
- d1[r[0:2]].append(r[3])
- except KeyError,e:
- d[r[0:2]]=[]
- d1[r[0:2]]=[]
- d[r[0:2]].append(r[2])#值
- d1[r[0:2]].append(r[3])#时间
- #遍历时间字典,将本月缺失天数补0
- for k,v in d1.items():
- for j in m: #遍历本月天数
- if not j in v:
- d[k].insert(m.index(j),0) #补0
-
-
- for k,v in d.items():
- if D.has_key(k):
- D[k].append({'cdn':v})
- d={} #清空
- d1={} #清空
- #本段生成CDN流量
- self.cursor.execute(sql_3)
- rows=self.cursor.fetchall()
- for r in rows:
- try:
- d[r[0:2]].append(r[2])
- d1[r[0:2]].append(r[3])
- except KeyError,e:
- d[r[0:2]]=[]
- d1[r[0:2]]=[]
- d[r[0:2]].append(r[2])
- d1[r[0:2]].append(r[3])
-
- for k,v in d1.items():
- for j in m: #遍历本月天数
- if not j in v:
- d[k].insert(m.index(j),0) #补0
-
- for k,v in d.items():
- if D.has_key(k):
- D[k].append({'idc':v})
- d={} #清空
- d1={} #清空数组
- self.cursor.execute(sql_4)
- rows=self.cursor.fetchall()
- for r in rows:
- try:
- d[r[0:2]].append(r[2])
- d1[r[0:2]].append(r[3])
- except KeyError,e:
- d[r[0:2]]=[]
- d1[r[0:2]]=[]
- d[r[0:2]].append(r[2])
- d1[r[0:2]].append(r[3])
-
- for k,v in d1.items():
- for j in m: #遍历本月天数
- if not j in v:
- d[k].insert(m.index(j),0) #补0
-
-
- for k,v in d.items():
- if D.has_key(k):
- D[k].append({'avgload':v})
- d={}
- #########################事件处理#####
- p=subprocess.Popen('''mysql -h xx -u xx -pxx3 -D xxxx -e "%s" ''' % sql_5,shell=True,stdout=subprocess.PIPE)
- out=p.stdout.readlines()
- for line in out[1::]:#掐去数据库字段
- G=line.strip('\n').split()
- try:
- g[G[0]].append(time.strftime('%Y-%m-%d',time.localtime(float(G[1]))))
- except KeyError,e:
- g[G[0]]=[time.strftime('%Y-%m-%d',time.localtime(float(G[1])))]
- ##事故可能一天发生一件事,也有可能一天发生N次,故处理下
- for k,v in g.items():
- for i in v:
- try:
- d_evs[i]+=1
- except KeyError:
- d_evs[i]=1 #这天内只发生一起事故
-
- for j in m: #添加缺失的天数
- if str(j) not in d_evs.keys():
- d_evs[str(j)]=0
-
- #d_evs.keys().sort(key=lambda d:(d.month,d.day)) #按月份,日期sort datatime 对象
- g[k]=[d_evs[x] for x in sorted(d_evs.keys())]#排序日期
- d_evs={} #清空字典
-
- for k,v in D.items():
- if g.has_key(k[1]):
- D[k].append({'events':g[k[1]]}) # 如果项目中有出现事故的项目
-
-
- return D #返回字典
-
-
- def _reconstruct(self,stime,etime):
- #stime 开始日期
- #etime 结束日期
- d=self._construct(stime,etime)
- for k,v in d.items():
- for a in v:
- if a.has_key('cdn'):
- p=drawpic(data=a['cdn'],name=k[1]+'_cdn'+'.jpeg',sdate=stime,edate=etime) #生成图片
- p._Gpic('date','traffic(MB)',u'%s年%s月CDN流量趋势图' %(stime.split('-')[0],stime.split('-')[1]))
- a['cdn']=k[1]+'_cdn'+'.jpeg'
- if a.has_key('idc'):
- p=drawpic(data=a['idc'],name=k[1]+'_idc'+'.jpeg',sdate=stime,edate=etime)
- p._Gpic('date','traffic(MB)',u'%s年%s月IDC流量趋势图' %(stime.split('-')[0],stime.split('-')[1]))
- a['idc']=k[1]+'_idc'+'.jpeg'
- if a.has_key('avgload'):
- p=drawpic(data=a['avgload'],name=k[1]+'_avgload'+'.jpeg',sdate=stime,edate=etime)
- p._Gpic('date','avgload(%)',u'%s年%s月平均负载趋势图' %(stime.split('-')[0],stime.split('-')[1]))
- a['avgload']=k[1]+'_avgload'+'.jpeg'
-
- #重新构造数据
- return d
ReportPDF.py
点击(此处)折叠或打开
- #/usr/bin/python
- #coding:utf-8
-
- import datetime
- import reportlab.rl_config
- reportlab.rl_config.warnOnMissingFontGlyphs = 0
- from reportlab.pdfbase import pdfmetrics
- from reportlab.pdfgen.canvas import Canvas
- import calendar
- from reportlab.pdfbase.ttfonts import TTFont
- from reportlab.lib import fonts,colors
- from reportlab.pdfgen import canvas
- from reportlab.platypus import Paragraph, SimpleDocTemplate,Table,Image,PageTemplate,Spacer
- from reportlab.lib.styles import getSampleStyleSheet
- from reportlab.platypus.doctemplate import *
- from GerData import *
- import copy
-
- ##注册中文字体
- pdfmetrics.registerFont(TTFont('song',"/home/xxx/stsong.ttf")) #路径
- pdfmetrics.registerFont(TTFont('hei','/home/xxxx/simhei.ttf')) #粗体
- fonts.addMapping('song',0,0,'song')
- fonts.addMapping('song',0,1,'song')
- fonts.addMapping('song',1,0,'hei')
- fonts.addMapping('song',1,1,'hei')
-
- class MyPDFdoc:
- class MyPageTemp(PageTemplate):
- '''
- 定义一个页面模板
- '''
- def __init__(self):
- F6=Frame(x1=0.5*inch, y1=0.5*inch, width=7.5*inch, height=2.0*inch,showBoundary=0)
- F5=Frame(x1=0.5*inch, y1=2.5*inch, width=7.5*inch, height=2.0*inch,showBoundary=0)
- F4=Frame(x1=0.5*inch, y1=4.5*inch, width=7.5*inch, height=2.0*inch,showBoundary=0)
- F3=Frame(x1=0.5*inch, y1=6.5*inch, width=7.5*inch, height=2.0*inch,showBoundary=0)
- F2=Frame(x1=0.5*inch, y1=8.5*inch, width=7.5*inch, height=2.0*inch,showBoundary=0)
- F1=Frame(x1=0.5*inch, y1=10.5*inch, width=7.5*inch, height=0.5*inch,showBoundary=0)
- PageTemplate.__init__(self,"MyTemplate",[F1,F2,F3,F4,F5,F6])
-
- def beforeDrawPage(self,canvas,doc): #在页面生成之前做什么画logo
- pass
-
- def __init__(self,filename):
- self.filename=filename
- self.objects=[] ##story
- self.doc=BaseDocTemplate(self.filename)
- self.doc.addPageTemplates(self.MyPageTemp())
- self.Style=getSampleStyleSheet()
- #设置中文,设置四种格式
- #self.nor=self.Style['Normal']
- self.cn=self.Style['Normal']
- self.cn.fontName='song'
- self.cn.fontSize=9
- self.t=self.Style['Title']
- self.t.fontName='song'
- self.t.fontSize=15
- self.h=self.Style['Heading1']
- self.h.fontName='song'
- self.h.fontSize=10
- self.end=copy.deepcopy(self.t)
- self.end.fontSize=7
-
-
-
- def _str3tocoma(self,num):#每三个数字加一个逗号
- e = list(str(num).split(".")[0])
- for i in range(len(e))[::-3][1:]:
- e.insert(i+1,",")
- return "".join(e)+"."+str(num).split(".")[1]
-
-
-
- def _CreatePDF(self,year,month,dep,pro,data,path=''): #
- #dep 部门
- #pro 项目
- d={}
- sum_num=0
- sum_cost=0
- data_1=[]
- tmp_arr=[]
- col=[u'模块',u'数量',u'费用(¥)',u'成本占比']
- '''
- 遍历字典
-
- {(dep,pro):[{'cost':[]},{'cdn':xxx.jpeg}.......]}
- data=[{'cost': [[1L, 56L, 23772.0], [3L, 15L, 11478.4200439453]]},
- {'cdn': '\xe6\x8d\x95\xe9\xb1\xbc\xe5\xa4\xa7\xe4\xba\xa8_cdn.jpeg'},
- {'idc': '\xe6\x8d\x95\xe9\xb1\xbc\xe5\xa4\xa7\xe4\xba\xa8_idc.jpeg'},
- {'avgload': '\xe6\x8d\x95\xe9\xb1\xbc\xe5\xa4\xa7\xe4\xba\xa8_avgload.jpeg'}]#data数据格式
- '''
- for i in data: # 遍历data
- d[i.keys()[0]]=i.values()[0]
- #生成对应关系
-
-
- #生成table Style
- S1=[('INNERGRID', (0,0), (-1,-1), 0.25, colors.black),('BOX', (0,0), (-1,-1), 0.25, colors.black)]
- S2=[('INNERGRID', (0,0), (-1,-1), 0.4, colors.black),('BOX', (0,0), (-1,-1), 0.25, colors.black),('ALIGN',(0,0),(-1,-1),'CENTER')]
- #T=self._CreateTable(data=d['cost'],col=[u'模块',u'数量',u'费用(¥)',u'占比'],style=S1,w=1.5*inch,h=0.2*inch)
- #添加标题
- self.objects.append(Paragraph('''%s%s%s月份业务报告''' % (dep,pro,month),self.t))
- self.objects.append(FrameBreak()) #切换到第二个FORM
- self.objects.append(Paragraph('''成本概况''',self.h))
- if d.has_key('cost'):
- for i in d['cost']:
- sum_num +=i[1]
- sum_cost +=i[2]
- for y in col:
- tmp_arr.append(Paragraph('''%s''' % y,self.cn))
-
- for i in d['cost']:
- if str(i[0])=='1':
- t=Paragraph('''设备''' ,self.cn)
- try:
- rate=i[2]/sum_cost
- #rate="%.2f" % rate
- rate="%5.2f%%" % (rate*100)
- except ZeroDivisionError:
- rate=0
- i[1]="%.2f" % i[1]
- i[2]="%.2f" % i[2]
- data_1.append([t,i[1],self._str3tocoma(i[2]),rate])
- if str(i[0])=='2':
- t=Paragraph('''CDN流量''' ,self.cn)
- try:
- rate=i[2]/sum_cost
- rate="%5.2f%%" % (rate*100)
- except ZeroDivisionError:
- rate=0
- i[1]="%.2f" % i[1]
- i[2]="%.2f" % i[2]
- data_1.append([t,i[1],self._str3tocoma(i[2]),rate])
- if str(i[0])=='3':
- t=Paragraph('''IDC流量''' ,self.cn)
- try:
- rate=i[2]/sum_cost
- rate="%5.2f%%" % (rate*100)
- except ZeroDivisionError:
- rate=0
- i[1]="%.2f" % i[1]
- i[2]="%.2f" % i[2]
- data_1.append([t,i[1],self._str3tocoma(i[2]),rate])
- data_1.insert(0,tmp_arr)
- t=Table(data_1,style=S1,colWidths=1.5*inch,rowHeights=0.2*inch)
- self.objects.append(t)
- self.objects.append(FrameBreak())
- self.objects.append(Paragraph('''本月负载趋势''',self.h))
- self.objects.append(Spacer(0,0))
- if d.has_key('avgload'):
- self.objects.append(Image('%s/%s' % (path,d['avgload']),500,102))
- else:
- self.objects.append(Paragraph('本图缺失',self.end))
- self.objects.append(FrameBreak())
- self.objects.append(Paragraph('''CDN流量趋势''',self.h))
- if d.has_key('cdn'):
- self.objects.append(Image('%s/%s' % (path,d['cdn']),500,102))
- else:
- self.objects.append(Paragraph('本图缺失',self.end))
- self.objects.append(FrameBreak())
- self.objects.append(Paragraph('''IDC流量趋势''',self.h))
- if d.has_key('idc'):
- self.objects.append(Image('%s/%s' % (path,d['idc'] ),500,102))
- else:
- self.objects.append(Paragraph('本图缺失',self.end))
- self.objects.append(FrameBreak())
- self.objects.append(Paragraph('''事故事件数''',self.h))
- if d.has_key('events'):
- c1=Paragraph('''日期''' ,self.cn)
- c2=Paragraph('''数量''' ,self.cn)
- c3=Paragraph('''总计''' ,self.cn)
- all_num=reduce(lambda x,y:int(x)+int(y),d['events'])
- d['events'].insert(0,c2)
- t1=[x for x in range(1,len(d['events']))]
- t1.insert(0,c1)
- m=[0.6]
- for i in range(len(d['events'])):
- m.append(0.2)
- t1=Table([t1,d['events']],style=S2,colWidths=[x*inch for x in m],rowHeights=0.2*inch)
- t2=Table([[c3,all_num]],style=S2,colWidths=reduce(lambda x,y:float(x)+float(y),m[:-1])*0.5*inch,rowHeights=0.2*inch)
- self.objects.append(t1)
- self.objects.append(Spacer(0,0))
- self.objects.append(t2)
- else:
- self.objects.append(Paragraph('本时间段内没有事故!',self.end))
- self.objects.append(Spacer(0.1*inch,0.1*inch))
- self.objects.append(Paragraph('''以上数据仅为参考,不能作为结算用!''',self.end))
- self.doc.build(self.objects)
-
- if __name__== "__main__":
- #生成PDF对象
- #取当月的第一天
- fd=datetime.date(datetime.date.today().year,datetime.date.today().month,1)
- ld=datetime.date(datetime.date.today().year,datetime.date.today().month+1,1)-datetime.timedelta(1)
- I=GatherData('xx','xxx','xx','xx')
- k=I._reconstruct(str(fd),str(ld))
- for k,v in k.items():
- filename=k[1]+'.pdf'
- pdf=MyPDFdoc(filename)
- pdf._CreatePDF(fd.year,fd.month,k[0],k[1],v,path='/tmp/test')
这绝对不是你copy 以后就能直接运行生成相关东西的,因为包安装这块我没有列出了我一直用的是python 2.5的版本 ,PIL,numpy(我用到了吗?貌似没有),脚本功能是实现了,个人感觉很烂,邮件这块数据库的字段没有,以后加上去了,我再更新下,改进的应该还蛮多,欢迎大家拍砖!最后再插一张样式PDF

http://blog.chinaunix.net/uid-17291169-id-3241613.html