Caffe BaseDataLayer.cpp BasePrefetchingDataLayer.cpp DataLayer.cpp 学习
本文是自己在学习Caffe源码做的笔记,结合自己的理解。但是水平有限,特别是多线程编程方面,还需要继续学习。如有错误或者疑问,欢迎指正,希望不会带来误解。后续也会即使修改更新!
先贴几张图来说明继承关系:

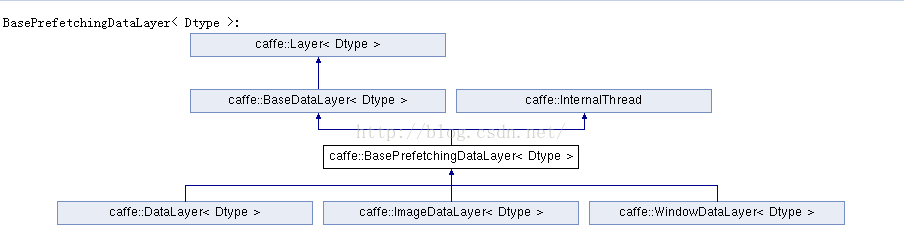

data_layers.hpp中定义了如下模板类:BaseDataLayer, Batch, BasePrefetchingDataLayer DataLayer DummyDataLayer HDF5DataLayer HDF5OutputLayer ImageDataLayer MemoryDataLayer WindowDataLayer
主要分析下BaseDataLayer BasePrefetchingDataLayer DataLayer。
=======================BaseDataLayer==================================
着重分析下其成员函数
//调用模板类layer的构造函数,将param传递给模板类layer的构造函数,同时用param.transform_param()初始化BaseDataLayer的transform_param_成员
template <typename Dtype>
BaseDataLayer<Dtype>::BaseDataLayer(const LayerParameter& param)
: Layer<Dtype>(param),
transform_param_(param.transform_param()) {
}
template <typename Dtype>
void BaseDataLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
if (top.size() == 1) {
output_labels_ = false;
} else {
output_labels_ = true;
}
data_transformer_.reset(
new DataTransformer<Dtype>(transform_param_, this->phase_));//reset data_transformer_, 为其重新分配内存
data_transformer_->InitRand();
// The subclasses should setup the size of bottom and top
DataLayerSetUp(bottom, top);
}
=============================BasePrefetchingDataLayer=========================
template <typename Dtype>
BasePrefetchingDataLayer<Dtype>::BasePrefetchingDataLayer(
const LayerParameter& param)
: BaseDataLayer<Dtype>(param),
prefetch_free_(), prefetch_full_() {
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_free_.push(&prefetch_[i]);//压入batch的地址
}
}
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
//1. 调用父类BaseDataLayer构造方法,因为BasePrefetchingDataLayer没有覆盖BaseDataLayer的DataLayerSetUp方法,所有他仍然调用父类的DataLayerSetUp方法
BaseDataLayer<Dtype>::LayerSetUp(bottom, top);//回避虚函数的机制,通过作用域符来限定调用的虚函数版本。由于C++的多态性,BaseDataLayer<Dtype>::LayerSetUp(bottom, top)会调用Datalayer的ataLayerSetUp方法,该方法会Reshape prefetch_的batch的data_ blob、label_ blob
// Before starting the prefetch thread(预取线程), we make cpu_data and gpu_data
// calls so that the prefetch thread does not accidentally make simultaneous
// cudaMalloc calls when the main thread is running. In some GPUs this
// seems to cause failures if we do not so.
for (int i = 0; i < PREFETCH_COUNT; ++i) {
//2. 访问预取数据空间,这里是为了提前分配预取数据的存储空间
prefetch_[i].data_.mutable_cpu_data();//由于C++的多态性,BaseDataLayer<Dtype>::LayerSetUp(bottom, top)会调用Datalayer的ataLayerSetUp方法,该方法会Reshape prefetch_的batch的data_ blob、label_ blob
if (this->output_labels_) {
prefetch_[i].label_.mutable_cpu_data();
}
}
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_[i].data_.mutable_gpu_data();
if (this->output_labels_) {
prefetch_[i].label_.mutable_gpu_data();
}
}
}
#endif
//3. 创建用于预取数据的线程
DLOG(INFO) << "Initializing prefetch";
this->data_transformer_->InitRand();//调用 DataTransformer类的InitRand方法生成一个随机数生成器。注意,DataTransformer类中有一个成员是shared_ptr<Caffe::RNG> rng_
StartInternalThread();//会调用InternalThreadEntry方法,因为Datalayer类没有覆盖InternalThreadEntry方法,所以如果真实的对象类型是Data_layer的话,也只会调用其基类的方法,即BasePrefetchingDataLayer<Dtype>::InternalThreadEntry()。
DLOG(INFO) << "Prefetch initialized.";
}
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::InternalThreadEntry() {
#ifndef CPU_ONLY
cudaStream_t stream;
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK(cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking));
}
#endif
try {
while (!must_stop()) {
Batch<Dtype>* batch = prefetch_free_.pop();//batch是指针
//load_batch(Batch<Dtype>* batch)方法Reshape了其中的data_ Blob,为其重新分配所需的内存。做到这一点已经足够,因为prefetch_free_中存储的也只是指针
load_batch(batch);//实际上会调用DataLayer的load_batch方法,因为它是个纯虚函数
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
batch->data_.data().get()->async_gpu_push(stream);
CUDA_CHECK(cudaStreamSynchronize(stream));
}
#endif
prefetch_full_.push(batch);//batch在经过load_batch(batch)后发生了变化
}
} catch (boost::thread_interrupted&) {
// Interrupted exception is expected on shutdown
}
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK(cudaStreamDestroy(stream));
}
#endif
}
//数据层作为网络的最底层,其forward功能只需要将设置top[0] top[1]的数据,即拷贝。
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
Batch<Dtype>* batch = prefetch_full_.pop("Data layer prefetch queue empty");
// Reshape to loaded data.
top[0]->ReshapeLike(batch->data_);
// Copy the data
caffe_copy(batch->data_.count(), batch->data_.cpu_data(),
top[0]->mutable_cpu_data());//将数据从batch拷贝到top[0]
DLOG(INFO) << "Prefetch copied";
if (this->output_labels_) {
// Reshape to loaded labels.
top[1]->ReshapeLike(batch->label_);
// Copy the labels.
caffe_copy(batch->label_.count(), batch->label_.cpu_data(),
top[1]->mutable_cpu_data());//将数据从batch拷贝到top[1]
}
prefetch_free_.push(batch);
}
========================DataLayer===========================
template <typename Dtype>
DataLayer<Dtype>::DataLayer(const LayerParameter& param)
: BasePrefetchingDataLayer<Dtype>(param),
reader_(param) {
}
template <typename Dtype>
DataLayer<Dtype>::~DataLayer() {
this->StopInternalThread();
}
//主要工作是:Reshape top blob 和 prefetch得到的batch的data_ blob、label_ blob
template <typename Dtype>
void DataLayer<Dtype>::DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int batch_size = this->layer_param_.data_param().batch_size();
// Read a data point, and use it to initialize the top blob.
Datum& datum = *(reader_.full().peek());
// Use data_transformer to infer the expected blob shape from datum.
vector<int> top_shape = this->data_transformer_->InferBlobShape(datum);
this->transformed_data_.Reshape(top_shape);//transformed_data_只是存储一张图片的数据,所以'0'维度依旧保持默认值'1'
// Reshape top[0] and prefetch_data according to the batch_size.
top_shape[0] = batch_size;//InferBlobShape(datum)返回的top_shape[0]为1
top[0]->Reshape(top_shape);
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {
this->prefetch_[i].data_.Reshape(top_shape);
}
LOG(INFO) << "output data size: " << top[0]->num() << ","
<< top[0]->channels() << "," << top[0]->height() << ","
<< top[0]->width();
// label
if (this->output_labels_) {
vector<int> label_shape(1, batch_size);
top[1]->Reshape(label_shape);
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {
this->prefetch_[i].label_.Reshape(label_shape);
}
}
}
// This function is called on prefetch thread
// 经过load_batch后,batch所指的数据显然发生了变化——> 虽然是以&(this->transformed_data_作为实参传递给Transform但是该地址与batch的data_ blob中每张图片的地址是相吻合的。
// load_batch(Batch<Dtype>* batch)方法Reshape了其中的data_ Blob,并且更新了数据成员transformed_data_。
// 因为Batch<Dtype>* batch仅仅是个指针,对其Reshape已经为这个Blob分配了所需要的内存,做到这一点已经足够了,毕竟prefetch_free_成员里存储的也只是指针。
template<typename Dtype>
void DataLayer<Dtype>::load_batch(Batch<Dtype>* batch) {
CPUTimer batch_timer;
batch_timer.Start();
double read_time = 0;
double trans_time = 0;
CPUTimer timer;
//返回count_。count_表示Blob存储的元素个数(shape_所有元素乘积). 如果是默认构造函数构造Blob,count_ capacity_为0。
//但是,经过Datalayer::DataLayerSetup函数的调用后,btach中data_/label_ blob都已经Reshape了,所以cout_,capacity_就不再为0了。
CHECK(batch->data_.count());
CHECK(this->transformed_data_.count());
// Reshape according to the first datum of each batch
// on single input batches allows for inputs of varying dimension.
const int batch_size = this->layer_param_.data_param().batch_size();
Datum& datum = *(reader_.full().peek());
// Use data_transformer to infer the expected blob shape from datum.
vector<int> top_shape = this->data_transformer_->InferBlobShape(datum);//从reader_中获取一个datum来猜测top_shape。
this->transformed_data_.Reshape(top_shape);
// Reshape batch according to the batch_size.
top_shape[0] = batch_size;
batch->data_.Reshape(top_shape);//reshape data_ blob的大小
Dtype* top_data = batch->data_.mutable_cpu_data();
Dtype* top_label = NULL; // suppress warnings about uninitialized variables
if (this->output_labels_) {
top_label = batch->label_.mutable_cpu_data();
}
for (int item_id = 0; item_id < batch_size; ++item_id) {
timer.Start();
// get a datum
Datum& datum = *(reader_.full().pop("Waiting for data"));//从reader_获取一张图片的Datum.
read_time += timer.MicroSeconds();
timer.Start();
// Apply data transformations (mirror, scale, crop...)
int offset = batch->data_.offset(item_id);//获取一张图片的offset,然后transform
//设置this->transformed_data_这个Blob的data_成员所指向的SyncedMemory类型对象的CPU内存指针cpu_ptr_设置为"top_data + offset"。
this->transformed_data_.set_cpu_data(top_data + offset);//简言之,将cpu_ptr定位到batch的data_ blob的"top_data + offset"位置处,使其指向当前即将要处理的一张图片,其实真实的过程是拷贝datum中的数据(或经过处理)至this->transformed_data_所指处。通过for循环,处理每张图片,从而更新transformed_data_。
this->data_transformer_->Transform(datum, &(this->transformed_data_));//调用后,this->transformed_data_所指向的内存会发生变化,即经过变换后的数据。如此更新数据成员transformed_data_,该成员是BasePrefetchingDataLayer类及其子类的数据成员
// Copy label.
if (this->output_labels_) {
top_label[item_id] = datum.label();
}
trans_time += timer.MicroSeconds();
reader_.free().push(const_cast<Datum*>(&datum));
}
timer.Stop();
batch_timer.Stop();
DLOG(INFO) << "Prefetch batch: " << batch_timer.MilliSeconds() << " ms.";
DLOG(INFO) << " Read time: " << read_time / 1000 << " ms.";
DLOG(INFO) << "Transform time: " << trans_time / 1000 << " ms.";
}
关于DataReader类,具体的代码、函数的功能也没搞明白,主要是多线程编程这一方面,以后再来学习。只有一个大概的理解:DataReader类的功能是从源数据文件读取数据,存储在队列中,并且为data layer所用。比如在load_batch方法中,从reader_中获取一个datum来猜测top_shape。因为caffe从数据库文件(lmdb,leveldb)读取数据,以datum为中转点。
INSTANTIATE_CLASS(DataLayer);REGISTER_LAYER_CLASS(Data):网上有说法:INSTANTIATE_CLASS(DataLayer)被用来实例化DataLayer的类模板,REGISTER_LAYER_CLASS(Data)被用来向layer_factory注册DataLayer的构造方法,方便直接通过层的名称(Data)直接获取层的对象。Caffe中内置的层在实现的码的最后都会加上这两个宏。http://imbinwang.github.io/blog/inside-caffe-code-layer/
下面从Caffe的整个流程控制来看一下Blob Layer Net Solver之间的联系。按Solver--->Net--->Layer--->Blob的顺序。
In Slover.cpp,在Init方法中,会调用InitTrainNet和InitTestNet方法来初始化TrainNet和TestNet,反正就是初始化Net,管它是Train的还是Test的,也就是Net.cpp中的Init方法。
In Net.cpp, 在Init方法中,"Creating Layer"————利用工厂函数来生成指向模板类layer的只能指针shared_ptr<Layer<Dtype> >(在share_from_root为False的情况下)。然后,AppendBottom,AppendTop,AppendParam。接着,"Setting up"————调用模板类的SetUp方法。
Caffe中layer有明显的继承关系,现在,以datalayer为例,来梳理一下layer的继承关系,以及Solver--->Net--->Layer--->Blob关系。直接进入Net.cpp,利用工厂函数根据LayerParameter可以得到一个指向基类Layer的智能指针shared_ptr<Layer<Dtype>>,这里使用指针是为了利用C++的多态性————基类指针既可以与基类绑定,也可以绑定派生类对象,如果在这里真正用到的是DataLayer,那么该指针应该与DataLayer对象绑定。
===>SetUp(), 调用LayerSetUp(),因为DataLayer没有覆盖其基类的LayerSetUp函数,所以直接调用从父类继承而来的LayerSetUp函数。
===>直接基类BasePrefetchingDataLayer的LayerSetUp(),先调用BaseDataLayer::LayerSetUp()
===>BaseDataLayer::LayerSetUp(), 在这个函数中,会调用DataLayerSetUp(),由于C++的多态性,这里实际调用的是DataLayer类的DataLayerSetUp()方法。
记得在Layer<Dtype>::SetUp()方法中,还会调用Reshape(),主要是为了修改top blob的shape,使得跟bottom blob能够accommodated,但是这些工作在DataLayer类的DataLayerSetUp()方法中已经完成。
===>SetUp()的最后一个步骤,就是SetLossWeights(top)
至于load_batch() InternalThreadEntry()也类似分析。