Scrapy与Mongodb结合爬虫
Scrapy与Mongodb结合爬虫
在学习爬虫的时候,突然发现国外的一篇关于scrapy与mongodb结合起来的爬虫,正好我也在学习scrapy与mongodb,正好将学习的过程记录下来,供以后参考,本文就从最基本的环境搭建开始做爬虫,环境为ubuntu 14.04,亲测有效。。。
- 安装scrapy
- 构建scrapy爬虫项目
- 设置DNS服务器
- 安装mongodb
- 安装robomongo可视化客户端
安装scrapy
在Ubuntu中安装各种软件在也简单不过了:
pip install scrapy让我们新建一个爬虫项目:
scrapy startproject stack通过这段代码我们生成了爬虫项目,会在当前文件夹下面创建stack目录。
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py接下来我们来修改其中的代码,因为我们需要爬的网页为stackoverflow.com,
获取提问问题的名称与url,所以需要两个字段,所以修改后的item.py为:
from scrapy.item import Item, Field
class StackItem(Item): title = Field() url = Field()现在我们来创建一个蜘蛛来爬网页,我们建立一个stack_spider.py在spiders文件夹下:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]- name :这是爬虫的名称
- allowed_domains:这是爬虫所爬的区域
- start_urls:这是爬虫开始爬的地方
HTML解析
这段代码特别令人头疼,我还没有完全搞明白,先贴上代码:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')代码大概意思就是,从当前网页标签中获取div class名称为summary的所有标签。
我们想要的内容就在标签里面,于是代码就变成这样:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item大功告成,我们先来体验一下:
scrapy crawl stack如果不出意外的话,应该会有50个问答输出。但是我们需要将问题存储起来,需要使用非关系型数据库,我们这里使用mongodb,一种非常流行的非关系型数据库。
安装mongodb
在安装mongodb时,国内网不好,于是首先更换阿里DNS服务器:
223.5.5.5
223.6.6.6安装mongodb,根据官网的顺序:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv EA312927
echo "deb http://repo.mongodb.org/apt/ubuntu trusty/mongodb-org/3.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.2.list
sudo apt-get update
sudo apt-get install -y mongodb-org
echo "mongodb-org hold" | sudo dpkg --set-selections
echo "mongodb-org-server hold" | sudo dpkg --set-selections
echo "mongodb-org-shell hold" | sudo dpkg --set-selections
echo "mongodb-org-mongos hold" | sudo dpkg --set-selections
echo "mongodb-org-tools hold" | sudo dpkg --set-selections到此为止,mongodb安装完成,下面就是启动:
sudo service mongod start如果不出意外的话,mongodb的端口为:27017
将数据存储到mongodb
到此为止,所有的准备工作已经完成,我们开始编写代码来实现,首先修改setting.py指定数据库:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"最后修改pipeline.py:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item我们来测试一下吧:
scrapy crawl stack结果为:
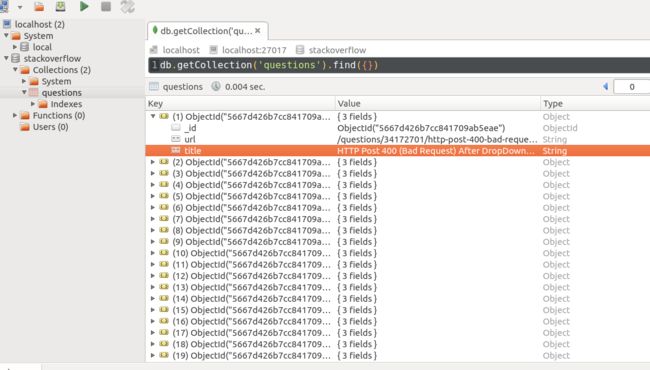
总结
通过这次实验,我们学会了scrapy来爬虫,并将爬到的数据存储到mongodb非关系型数据库中,这是非常令人激动的。下面来系统的学习一下xpath与mongodb数据库的操作。