Spark学习一
Spark学习一
标签(空格分隔): Spark
- Spark学习一
- 一概述
- 二spark的安装
- 三spark的初步使用
- 四spark的standalone模式的配置
一,概述
- 列表项
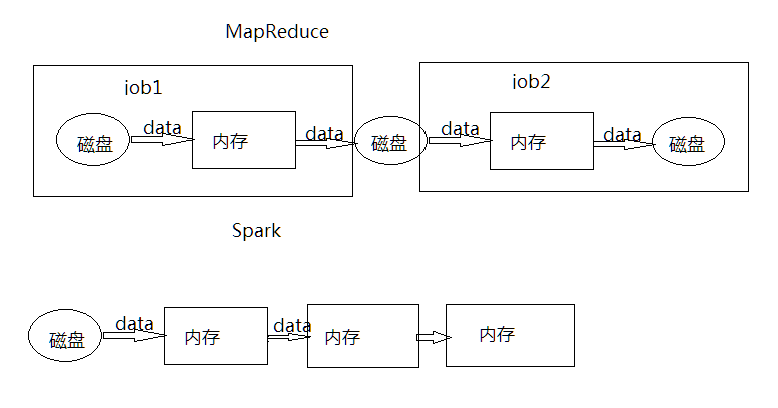
和mapreduce计算的比较

- what is spark
Apache Spark™ is a fast and general engine for large-scale data processing.
1,Speed:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk
2,Ease of Use:Write applications quickly in Java, Scala, Python,Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells.
3,Generality:Combine SQL, streaming, and complex analytics.
4,Runs Everywhere:Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3

学好spark的路径:
*,http://spark.apache.org/
*,spark源码:https://github.com/apache/spark
*,https://databricks.com/blog
二,spark的安装
- 解压scala安装包
[hadoop001@xingyunfei001 app]$ chmod u+x scala-2.10.4.tgz
[hadoop001@xingyunfei001 app]$ tar -zxf scala-2.10.4.tgz -C /opt/app- 修改/etc/profile配置文件
export SCALA_HOME=/opt/app/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin[hadoop001@xingyunfei001 app]$ scala -version
[hadoop001@xingyunfei001 scala-2.10.4]$ source /etc/profile- 解压spark安装包
[hadoop001@xingyunfei001 app]$ chmod u+x spark-1.3.0-bin-2.5.tar.gz
[hadoop001@xingyunfei001 app]$ tar -zxf spark-1.3.0-bin-2.5.tar.gz -C /opt/app- 配置spark的配置文件(spark-env.sh.template—>spark-env.sh)
JAVA_HOME=/opt/app/jdk1.7.0_67
SCALA_HOME=/opt/app/scala-2.10.4
HADOOP_CONF_DIR=/opt/app/hadoop_2.5.0_cdh- 启动spark
bin/spark-shell
三,spark的初步使用
- 第一个案例
var rdd=sc.textFile("/opt/datas/beifeng.log")
rdd.count //显示总条数
rdd.first //显示第一条数据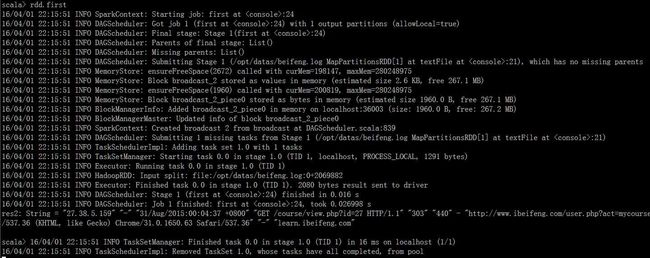
rdd.take(2) //获取头2条数据
rdd.filter(x=>x.contains("yarn")).collect
rdd.filter(_.contains("yarn")).collect
rdd.cache //将数据放到内存中
rdd.count
rdd.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>(x+y)).collect
四,spark的standalone模式的配置
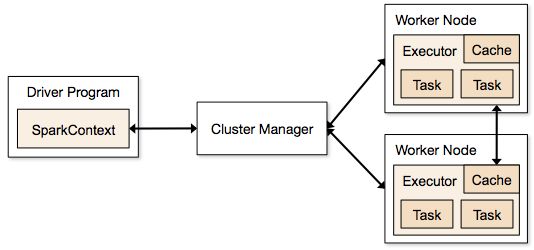
sparkcpntext:
1,application申请资源
2,读取数据,创建rdd
- 修改配置文件spark-env.sh
SPARK_MASTER_IP=xingyunfei001.com.cn
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_INSTANCES=1- 修改配置文件slaves
# A Spark Worker will be started on each of the machines listed below.
xingyunfei001.com.cn- 启动standalone模式
[hadoop001@xingyunfei001 spark-1.3.0-bin-2.5.0]$ sbin/start-master.sh
[hadoop001@xingyunfei001 spark-1.3.0-bin-2.5.0]$ sbin/start-slaves.sh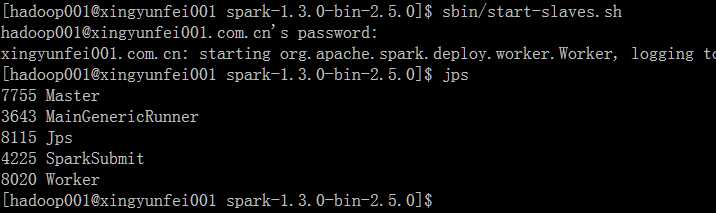

- 提交应用
bin/spark-shell --master spark://xingyunfei001.com.cn:7070
var rdd=sc.textFile("/opt/datas/input.txt")
val wordcount=rdd.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>(x+y)).collect sc.stop 

[hadoop001@xingyunfei001 spark-1.3.0-bin-2.5.0]$ bin/spark-shell local[2] //本地模式启动2个线程
[hadoop001@xingyunfei001 spark-1.3.0-bin-2.5.0]$ bin/spark-shell local[*] //根据本地配置自动设置线程数目- web监控界面:http://xingyunfei001.com.cn:4040/jobs/