linux系统调用poll
I/O复用技术是:把我们关注的描述符组成一个描述符表(通常不止一个描述符),调用I/O复用函数(select/poll/epoll),当描述符表中有可进行非阻塞I/O操作的描述符时,复用函数返回;否则阻塞复用函数,直到描述符表中有可进行非阻塞I/O操作的描述符出现时,才唤醒进程继续执行复用函数;当复用函数正常返回时,就可以知道哪些描述符可进行非阻塞I/O操作。
I/O复用的描述符通常包括:终端/伪终端,pipes,socket等
I/O复用函数主要过程:
1.遍历描述符表,判断该描述符表中是否有描述符可进行非阻塞I/O操作(读、写、异常等);
2.如果描述符表中有描述符可进行非阻塞I/O操作,I/O复用函数通知用户进程这些描述符;
3.如果描述符表中没有描述符可进行非阻塞I/O操作,那么I/O复用函数被阻塞,并将进程添加到描述符表中所有描述符的poll等待队列中
4.当有描述符可进行非阻塞I/O操作时,内核唤醒该描述符poll等待队列中的阻塞进程;进程唤醒后继续执行I/O复用函数,I/O复用函数将进程从描述符表中所有描述符的poll等待队列中移除;然后重新遍历描述符表
I.poll
poll是I/O复用函数之一,其原型为:
int poll(struct pollfd fds[], nfds_t nfds, int timeout);
39 /* Data structure describing a polling request. */
40 struct pollfd
41 {
42 int fd; /* File descriptor to poll. */
43 short int events; /* Types of events poller cares about. */
44 short int revents; /* Types of events that actually occurred. */
45 };
输入参数:
fds:描述符及事件组成的pollfd数组
nfds:pollfd数组大小
timeout:超时时间,单位为毫秒
输出参数:
1、pollfd.events中发生的事件pollfd.revents
返回值:
>0:pollfd.events事件发生的文件描述符的个数
0:超时,所有文件描述中pollfd.events事件都未发生
-1:错误返回
poll与select功能近似,差异主要是:
1.poll的事件更为精确,select的事件只能为POLLIN_SET,POLLOUT_SET,POLLEX_SET,而这三个事件均是由poll事件组成的集合;
2.poll的描述符表没有大小限制;select描述符表最大不能超过FD_SET_SIZE(fd_set类型的比特位数)
3.poll的描述符及事件不用每次调用poll都重新赋值(输入为pollfd.events,输出为pollfd.revents),但是select每次调用都必须重新赋值(输入输出均为readfds,writefds,errorfds);
II.数据结构
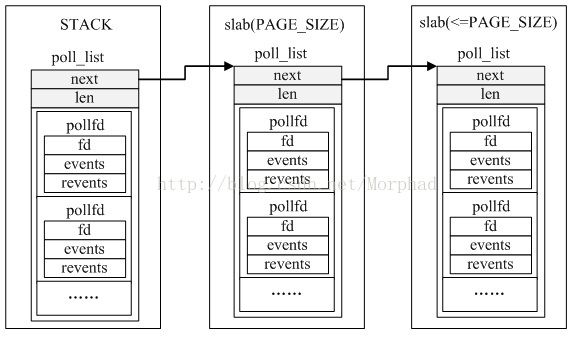
i.poll_list
694 struct poll_list {
695 struct poll_list *next;
696 int len;
697 struct pollfd entries[0];
698 };
808 #define N_STACK_PPS ((sizeof(stack_pps) - sizeof(struct poll_list)) / \
809 sizeof(struct pollfd))
poll_list主要用于将pollfd数据存储在内核空间中,内存取自内核堆栈和slab;只有内核堆栈预分配给pollfd的内存使用完(pollfd数据大于N_STACK_PPS)后才会从slab中获取额外的内存
ii.poll_list之间关系图
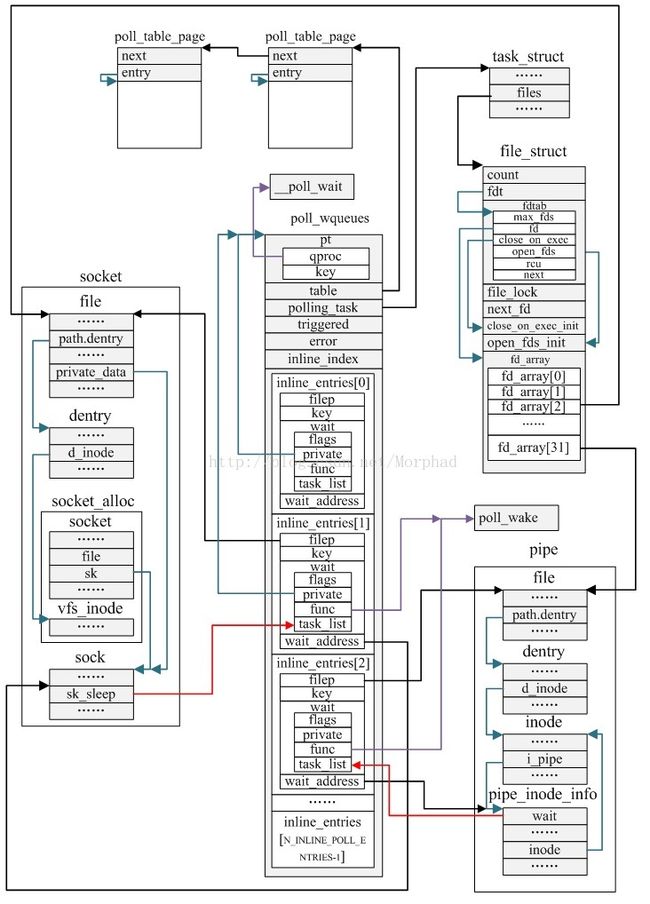
iii.poll_wqueues
33 typedef struct poll_table_struct {
34 poll_queue_proc qproc;
35 unsigned long key;
36 } poll_table;
50 struct poll_table_entry {
51 struct file *filp;
52 unsigned long key;
53 wait_queue_t wait;
54 wait_queue_head_t *wait_address;
55 };
56
57 /*
58 * Structures and helpers for sys_poll/sys_poll
59 */
60 struct poll_wqueues {
61 poll_table pt;
62 struct poll_table_page *table;
63 struct task_struct *polling_task;
64 int triggered;
65 int error;
66 int inline_index;
67 struct poll_table_entry inline_entries[N_INLINE_POLL_ENTRIES];
68 };
poll_table:对每个文件进行poll操作时,判断是否能够非阻塞的进行key值(poll事件组成)标识的I/O操作;如果不能,调用回调函数qproc将进程添加到文件的poll等待队列中
poll_table_entry:用于阻塞进程并将进程添加到文件的poll等待队列中,一个文件对应一个poll_table_entry
poll_wqueues:用于在select/poll时,如果需要阻塞进程,将进程添加到描述符表标识的所有文件的poll等待队列中,以便任意一个文件可进行非阻塞I/O操作时唤醒进程
iv.进程、打开文件、poll等待队列之间关系图
III.复用函数阻塞/唤醒
i.poll_wqueues的初始化
44 static inline void init_poll_funcptr(poll_table *pt, poll_queue_proc qproc)
45 {
46 pt->qproc = qproc;
47 pt->key = ~0UL; /* all events enabled */
48 }
116 void poll_initwait(struct poll_wqueues *pwq)
117 {
118 init_poll_funcptr(&pwq->pt, __pollwait);
119 pwq->polling_task = current;
120 pwq->triggered = 0;
121 pwq->error = 0;
122 pwq->table = NULL;
123 pwq->inline_index = 0;
124 }
1.将阻塞回调函数设置成__pollwait
2.将阻塞进程设置成当前进程
ii.文件poll阻塞
1.poll阻塞
当对单个文件执行poll操作时,如果文件不能非阻塞的进行key标识的I/O操作,会将当前进程添加到该文件的poll等待队列中
tcp阻塞f_op->poll:socket_file_ops->sock_poll->inet_stream_ops->tcp_poll->sock_poll_wait->poll_wait
pipe阻塞f_op->poll:write_pipefifo_fops->pipe_poll->poll_wait
38 static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
39 {
40 if (p && wait_address)
41 p->qproc(filp, wait_address, p);
42 }
216 static void __pollwait(struct file *filp, wait_queue_head_t *wait_address,
217 poll_table *p)
218 {
219 struct poll_wqueues *pwq = container_of(p, struct poll_wqueues, pt);
220 struct poll_table_entry *entry = poll_get_entry(pwq);
221 if (!entry)
222 return;
223 get_file(filp);
224 entry->filp = filp;
225 entry->wait_address = wait_address;
226 entry->key = p->key;
227 init_waitqueue_func_entry(&entry->wait, pollwake);
228 entry->wait.private = pwq;
229 add_wait_queue(wait_address, &entry->wait);
230 }
a.poll_wait中的qproc在poll_initwait时设置成__pollwait;如果poll_table与wait_address非NULL,则调用__poll_wait
b.将poll等待队列的waiter唤醒函数设置成pollwake
c.将poll_table_entry放入wait_address(socket为sock->sk_sleep,pipe为pipe_inode_info->wait)的等待队列中
3.poll_get_entry
98 #define POLL_TABLE_FULL(table) \
99 ((unsigned long)((table)->entry+1) > PAGE_SIZE + (unsigned long)(table))
155 static struct poll_table_entry *poll_get_entry(struct poll_wqueues *p)
156 {
157 struct poll_table_page *table = p->table;
158
159 if (p->inline_index < N_INLINE_POLL_ENTRIES)
160 return p->inline_entries + p->inline_index++;
161
162 if (!table || POLL_TABLE_FULL(table)) {
163 struct poll_table_page *new_table;
164
165 new_table = (struct poll_table_page *) __get_free_page(GFP_KERNEL);
166 if (!new_table) {
167 p->error = -ENOMEM;
168 return NULL;
169 }
170 new_table->entry = new_table->entries;
171 new_table->next = table;
172 p->table = new_table;
173 table = new_table;
174 }
175
176 return table->entry++;
177 }
a.poll_get_entry用于获取poll_wqueues中的poll_table_entry
b.如果poll_wqueues的INLINE空间有空闲entry,则从INLINE空间中分配entry
c.如果INLINE空间没有空闲entry,则分配新页帧作为poll_table_page;新poll_table_page插入链表头,以便下次分配只查看首结点就能知道是否有空闲entry
iii.文件poll唤醒
当复用函数被阻塞后,如果有异步事件出现而使文件能非阻塞的进行key标识的I/O操作时,会调用wake_up_interruptible_sync_poll唤醒被阻塞的复用函数
tcp数据接收事件唤醒复用函数:tcp_protocol->tcp_v4_rcv->tcp_v4_do_rcv->tcp_rcv_established->sk_data_ready->sock_def_readable->wake_up_interruptible_sync_poll
pipe写事件唤醒复用函数:pipe_write->wake_up_interruptible_sync_poll
164 #define wake_up_interruptible_sync(x) __wake_up_sync((x), TASK_INTERRUPTIBLE, 1)
5897 /*
5898 * The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
5899 * wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
5900 * number) then we wake all the non-exclusive tasks and one exclusive task.
5901 *
5902 * There are circumstances in which we can try to wake a task which has already
5903 * started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
5904 * zero in this (rare) case, and we handle it by continuing to scan the queue.
5905 */
5906 static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
5907 int nr_exclusive, int wake_flags, void *key)
5908 {
5909 wait_queue_t *curr, *next;
5910
5911 list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
5912 unsigned flags = curr->flags;
5913
5914 if (curr->func(curr, mode, wake_flags, key) &&
5915 (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
5916 break;
5917 }
5918 }
5954 /**
5955 * __wake_up_sync_key - wake up threads blocked on a waitqueue.
5956 * @q: the waitqueue
5957 * @mode: which threads
5958 * @nr_exclusive: how many wake-one or wake-many threads to wake up
5959 * @key: opaque value to be passed to wakeup targets
5960 *
5961 * The sync wakeup differs that the waker knows that it will schedule
5962 * away soon, so while the target thread will be woken up, it will not
5963 * be migrated to another CPU - ie. the two threads are 'synchronized'
5964 * with each other. This can prevent needless bouncing between CPUs.
5965 *
5966 * On UP it can prevent extra preemption.
5967 *
5968 * It may be assumed that this function implies a write memory barrier before
5969 * changing the task state if and only if any tasks are woken up.
5970 */
5971 void __wake_up_sync_key(wait_queue_head_t *q, unsigned int mode,
5972 int nr_exclusive, void *key)
5973 {
5974 unsigned long flags;
5975 int wake_flags = WF_SYNC;
5976
5977 if (unlikely(!q))
5978 return;
5979
5980 if (unlikely(!nr_exclusive))
5981 wake_flags = 0;
5982
5983 spin_lock_irqsave(&q->lock, flags);
5984 __wake_up_common(q, mode, nr_exclusive, wake_flags, key);
5985 spin_unlock_irqrestore(&q->lock, flags);
5986 }
5987 EXPORT_SYMBOL_GPL(__wake_up_sync_key);
5988
5989 /*
5990 * __wake_up_sync - see __wake_up_sync_key()
5991 */
5992 void __wake_up_sync(wait_queue_head_t *q, unsigned int mode, int nr_exclusive)
5993 {
5994 __wake_up_sync_key(q, mode, nr_exclusive, NULL);
5995 }
5996 EXPORT_SYMBOL_GPL(__wake_up_sync); /* For internal use only */
wake_up_interruptible_sync同步唤醒一个等待进程
__wake_up_common中的func是由__pollwait设置成的pollwake
179 static int __pollwake(wait_queue_t *wait, unsigned mode, int sync, void *key)
180 {
181 struct poll_wqueues *pwq = wait->private;
182 DECLARE_WAITQUEUE(dummy_wait, pwq->polling_task);
183
184 /*
185 * Although this function is called under waitqueue lock, LOCK
186 * doesn't imply write barrier and the users expect write
187 * barrier semantics on wakeup functions. The following
188 * smp_wmb() is equivalent to smp_wmb() in try_to_wake_up()
189 * and is paired with set_mb() in poll_schedule_timeout.
190 */
191 smp_wmb();
192 pwq->triggered = 1;
193
194 /*
195 * Perform the default wake up operation using a dummy
196 * waitqueue.
197 *
198 * TODO: This is hacky but there currently is no interface to
199 * pass in @sync. @sync is scheduled to be removed and once
200 * that happens, wake_up_process() can be used directly.
201 */
202 return default_wake_function(&dummy_wait, mode, sync, key);
203 }
204
205 static int pollwake(wait_queue_t *wait, unsigned mode, int sync, void *key)
206 {
207 struct poll_table_entry *entry;
208
209 entry = container_of(wait, struct poll_table_entry, wait);
210 if (key && !((unsigned long)key & entry->key))
211 return 0;
212 return __pollwake(wait, mode, sync, key);
213 }
1.如果唤醒进程的事件不是复用函数所关心的事件,则不会去唤醒复用函数;如果是关心的事件,则调用__pollwake唤醒复用函数
2.将triggered置1 ;在遍历完复用函数所提供的文件描述符表后,如果没有满足的描述符时会阻塞进程;但是如果已经遍历的文件在遍历的过程中,有异步事件出现而使文件能非阻塞的进行key标识的I/O操作时,则不会去阻塞进程;阻塞进程时会检查triggered标识,如果是0才会去阻塞进程 ,否则不会去阻塞。
3.通过default_wake_function->try_to_wake_up唤醒复用函数的调用进程(当进程已经是TASK_RUNNING时,则直接返回)
iv.poll_wqueues释放
127 static void free_poll_entry(struct poll_table_entry *entry)
128 {
129 remove_wait_queue(entry->wait_address, &entry->wait);
130 fput(entry->filp);
131 }
132
133 void poll_freewait(struct poll_wqueues *pwq)
134 {
135 struct poll_table_page * p = pwq->table;
136 int i;
137 for (i = 0; i < pwq->inline_index; i++)
138 free_poll_entry(pwq->inline_entries + i);
139 while (p) {
140 struct poll_table_entry * entry;
141 struct poll_table_page *old;
142
143 entry = p->entry;
144 do {
145 entry--;
146 free_poll_entry(entry);
147 } while (entry > p->entries);
148 old = p;
149 p = p->next;
150 free_page((unsigned long) old);
151 }
152 }
1.由于在遍历描述符表中文件的过程中,不知道未遍历到的文件能否非阻塞的进行key标识的I/O操作;所以当前文件不能非阻塞的进行key标识的I/O操作时,就会将进程添加到文件的poll等待队列中,以便后续文件不能非阻塞的进行I/O操作时不用再遍历描述符表去将进程添加到文件的poll等待队列中。
2.不管是阻塞被唤醒(进程添加到描述符表中所有文件的poll队列中)还是未阻塞(进程已经添加到描述符表中可进行非阻塞I/O操作文件之前的所有文件的poll队列中),在复用函数退出时,都会调用poll_freewait将poll_wqueues中所有的waiter从文件的等待队列中清空,及释放相应的文件及内存
IV.poll实现
i.poll
fs/select.c:
898 SYSCALL_DEFINE3(poll, struct pollfd __user *, ufds, unsigned int, nfds,
899 long, timeout_msecs)
900 {
901 struct timespec end_time, *to = NULL;
902 int ret;
903
904 if (timeout_msecs >= 0) {
905 to = &end_time;
906 poll_select_set_timeout(to, timeout_msecs / MSEC_PER_SEC,
907 NSEC_PER_MSEC * (timeout_msecs % MSEC_PER_SEC));
908 }
909
910 ret = do_sys_poll(ufds, nfds, to);
911
912 if (ret == -EINTR) {
913 struct restart_block *restart_block;
914
915 restart_block = ¤t_thread_info()->restart_block;
916 restart_block->fn = do_restart_poll;
917 restart_block->poll.ufds = ufds;
918 restart_block->poll.nfds = nfds;
919
920 if (timeout_msecs >= 0) {
921 restart_block->poll.tv_sec = end_time.tv_sec;
922 restart_block->poll.tv_nsec = end_time.tv_nsec;
923 restart_block->poll.has_timeout = 1;
924 } else
925 restart_block->poll.has_timeout = 0;
926
927 ret = -ERESTART_RESTARTBLOCK;
928 }
929 return ret;
930 }
1.转换超时时间,由ms转换成timespec
2.调用do_sys_poll
3.如果在poll调用被阻塞时收到signal,do_sys_poll则产生EINR错误;此时返回ERESTART_RESTARTBLOCK,通知内核处理完信号后自动通过sys_restart_syscall重启poll调用(这个过程对用户进程而言是透明的)
ii.do_sys_poll
811 int do_sys_poll(struct pollfd __user *ufds, unsigned int nfds,
812 struct timespec *end_time)
813 {
814 struct poll_wqueues table;
815 int err = -EFAULT, fdcount, len, size;
816 /* Allocate small arguments on the stack to save memory and be
817 faster - use long to make sure the buffer is aligned properly
818 on 64 bit archs to avoid unaligned access */
819 long stack_pps[POLL_STACK_ALLOC/sizeof(long)];
820 struct poll_list *const head = (struct poll_list *)stack_pps;
821 struct poll_list *walk = head;
822 unsigned long todo = nfds;
823
824 if (nfds > current->signal->rlim[RLIMIT_NOFILE].rlim_cur)
825 return -EINVAL;
826
827 len = min_t(unsigned int, nfds, N_STACK_PPS);
828 for (;;) {
829 walk->next = NULL;
830 walk->len = len;
831 if (!len)
832 break;
833
834 if (copy_from_user(walk->entries, ufds + nfds-todo,
835 sizeof(struct pollfd) * walk->len))
836 goto out_fds;
837
838 todo -= walk->len;
839 if (!todo)
840 break;
841
842 len = min(todo, POLLFD_PER_PAGE);
843 size = sizeof(struct poll_list) + sizeof(struct pollfd) * len;
844 walk = walk->next = kmalloc(size, GFP_KERNEL);
845 if (!walk) {
846 err = -ENOMEM;
847 goto out_fds;
848 }
849 }
850
851 poll_initwait(&table);
852 fdcount = do_poll(nfds, head, &table, end_time);
853 poll_freewait(&table);
854
855 for (walk = head; walk; walk = walk->next) {
856 struct pollfd *fds = walk->entries;
857 int j;
858
859 for (j = 0; j < walk->len; j++, ufds++)
860 if (__put_user(fds[j].revents, &ufds->revents))
861 goto out_fds;
862 }
863
864 err = fdcount;
865 out_fds:
866 walk = head->next;
867 while (walk) {
868 struct poll_list *pos = walk;
869 walk = walk->next;
870 kfree(pos);
871 }
872
873 return err;
874 }
1.nfds检查,是否大于最大打开文件限制signal->rlim[RLIMIT_NOFILE].rlim_cur
2.将用户空间的pollfd数组复制到内核态的poll_list中
3.初始化poll_wqueues
4.调用do_poll
5.释放poll_wqueues
6.将返回事件从内核态的poll_list复制到用户空间的pollfd数组中
7.释放poll_list所占用的slab内存,内核堆栈上的内存会在do_sys_poll返回后自动释放
iii.do_poll
740 static int do_poll(unsigned int nfds, struct poll_list *list,
741 struct poll_wqueues *wait, struct timespec *end_time)
742 {
743 poll_table* pt = &wait->pt;
744 ktime_t expire, *to = NULL;
745 int timed_out = 0, count = 0;
746 unsigned long slack = 0;
747
748 /* Optimise the no-wait case */
749 if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
750 pt = NULL;
751 timed_out = 1;
752 }
753
754 if (end_time && !timed_out)
755 slack = estimate_accuracy(end_time);
756
757 for (;;) {
758 struct poll_list *walk;
759
760 for (walk = list; walk != NULL; walk = walk->next) {
761 struct pollfd * pfd, * pfd_end;
762
763 pfd = walk->entries;
764 pfd_end = pfd + walk->len;
765 for (; pfd != pfd_end; pfd++) {
766 /*
767 * Fish for events. If we found one, record it
768 * and kill the poll_table, so we don't
769 * needlessly register any other waiters after
770 * this. They'll get immediately deregistered
771 * when we break out and return.
772 */
773 if (do_pollfd(pfd, pt)) {
774 count++;
775 pt = NULL;
776 }
777 }
778 }
779 /*
780 * All waiters have already been registered, so don't provide
781 * a poll_table to them on the next loop iteration.
782 */
783 pt = NULL;
784 if (!count) {
785 count = wait->error;
786 if (signal_pending(current))
787 count = -EINTR;
788 }
789 if (count || timed_out)
790 break;
791
792 /*
793 * If this is the first loop and we have a timeout
794 * given, then we convert to ktime_t and set the to
795 * pointer to the expiry value.
796 */
797 if (end_time && !to) {
798 expire = timespec_to_ktime(*end_time);
799 to = &expire;
800 }
801
802 if (!poll_schedule_timeout(wait, TASK_INTERRUPTIBLE, to, slack))
803 timed_out = 1;
804 }
805 return count;
806 }
1.遍历poll_list,对每个pollfd进行do_pollfd操作
a.如果pollfd不能满足poll要求,poll会自动将进程添加到文件的poll等待队列中(见poll阻塞);
b.如果pollfd满足poll要求,将计数count加1,poll_table置成NULL,即后续的遍历不用再将进程添加到文件的poll等待队列中竺;即使该文件不能进行非阻塞的I/O操作也不用将进程添加到文件的等待队列中,因为复用函数只需要有一个文件可进行非阻塞I/O操作即可
2.遍历结束后
A.如果poll_list中有pollfd满足poll,则返回满足poll的个数
B.如果poll_list中没有pollfd满足poll
a.如果有信号产生,则返回EINTR;内核会先处理信号,再重新恢复poll系统调用
b.如果超时,则超时返回
c.如果未超时,则超时阻塞poll系统调用;当有异步事件出现而满足文件poll(如tcp收到数据,满足读poll),唤醒进程,跳到1重新遍历poll_list
iv.do_pollfd
702 /*
703 * Fish for pollable events on the pollfd->fd file descriptor. We're only
704 * interested in events matching the pollfd->events mask, and the result
705 * matching that mask is both recorded in pollfd->revents and returned. The
706 * pwait poll_table will be used by the fd-provided poll handler for waiting,
707 * if non-NULL.
708 */
709 static inline unsigned int do_pollfd(struct pollfd *pollfd, poll_table *pwait)
710 {
711 unsigned int mask;
712 int fd;
713
714 mask = 0;
715 fd = pollfd->fd;
716 if (fd >= 0) {
717 int fput_needed;
718 struct file * file;
719
720 file = fget_light(fd, &fput_needed);
721 mask = POLLNVAL;
722 if (file != NULL) {
723 mask = DEFAULT_POLLMASK;
724 if (file->f_op && file->f_op->poll) {
725 if (pwait)
726 pwait->key = pollfd->events |
727 POLLERR | POLLHUP;
728 mask = file->f_op->poll(file, pwait);
729 }
730 /* Mask out unneeded events. */
731 mask &= pollfd->events | POLLERR | POLLHUP;
732 fput_light(file, fput_needed);
733 }
734 }
735 pollfd->revents = mask;
736
737 return mask;
738 }
1.根据pollfd中的文件描述符取出文件file对象
2.调用文件的poll方法;如果满足poll操作,则返回对应的poll事件;否则将进程添加到文件的poll等待队列中(具体过程见poll阻塞)
3.将返回事件取pollfd->events|POLLERR|POLLHUP子集后,放入pollfd->revents中