Huffman编码解压缩的通俗讲解
前言
好久没写博客了,主要是各种事缠着,难以抽出时间。这两个月以来,由于项目需要,我也逼着自己学到了很多,什么java后台,web前端,还有万恶的OpenCV图形处理……,呵呵,全栈:( 。但对Android的学习我始终不肯放下。但是今天这篇博客不是关于Android的,而是算法的相关应用–哈夫曼压缩。这是数据结构与算法实验里面的一个项目,网上关于这方面的资料很多,但大多数博客都是随便讲讲然后扔下代码。同时有同学请教我,所以就有了写一篇关于这个知识点的高质量博文的想法。
你应该知道
读这篇博客前你应该掌握如下的基本知识:
- 最基本的常识,一个字节有8位,int一般占4个字节,即32位。
- vector动态数组的基本用法
- 利用FILE类对二进制文件的基本读写操作
- fgetc(fin);方法虽然返回的是int,但实际上是由一个字节转换而来的,所以其范围也是0~255;同样地,fputc(int,fout);方法也是一样,写入一个字节到二进制文件当中,所以传入的int的范围也在0~255。
- 计算机存储文件都是以二进制流的形式来存的,图片也不例外。
- 值得吐槽的是,C++读写操作的最小单位是字节,要想以bit为单位读写文件只能通过读写字节然后进行移位运算。Java就很人性化啦,提供了bit流的IO操作函数。
- 利用fwrite()、fread()方法可以将数据块读写文件,权值数组的读写就是这两个方法进行。这两个方法的使用请查阅文档。 -
哈夫曼编码
其实哈夫曼编码并不是本篇的重点,所以下面我只进行粗略的讲述。
压缩的原理
计算机文件是由01串组成的。那么举个栗子,有一个文件,头几个二进制串:
01000010010011010001011011011111……..
那么,C++就是每8位(bit)来读,就是以字节为单位来读取,每个字节被转化成整型int。
读取代码如下:
int c;
vector<int> binaryData;
while (true) {
c = fgetc(fin);
if (feof(fin)) break;
weight[c]++;
binaryData.push_back(c);
cout<<c<<endl;
}输出为:66 77 22 223 ………
这是定长的编码方式。而Huffman编码不定长的编码方式,是通过出现字节的频率的不同编程长度不同的01码字。假如,这里66这个字节出现了1万次,77这个字节出现了只5次,那我们当然想把66尽可能用短一点的码字来编,而77就用长一点的码字来编也无所谓,毕竟它出现的次数少。这样不就能有效地缩短了文件整体的bit数吗?
具体代码的实现
根据各个字节出现的频率(权值)来构建Huffman树离不开对权值进行排序。而我们发现,用最小堆来构建Huffman树是最优雅的方式了。
核心代码:
//传入权值数组形成最小堆
MinHeap heap(n, h);
HuffmanTreeNode *n1 = NULL;
HuffmanTreeNode *n2 = NULL;
HuffmanTreeNode *parent = NULL;
//进行n-1次操作后,堆已空,哈夫曼树构建完成
for (int i = 0; i < n - 1; i++) {
//从堆中取出最小两个的节点,
n1 = heap.pop();
n2 = heap.pop();
//new一个父节点,父节点的值为两个子节点的值之和
parent = new HuffmanTreeNode(n1->weight + n2->weight);
//连接刚才取出的两个节点,合并两棵子树
mergeTree(*n1, parent, *n2);
//把父节点添加到堆中
heap.push(*parent);
}别急~完整的代码会在博文的最后给出,请耐心往下看 : )
Huffman压缩
看到这,你可能会想,原理原来这么简单!我会送你一句话,too young too simple! 其实实现起来还是有几处棘手的地方。
首先大体的步骤:
- 读入源文件,统计字符出现的次数(即统计权重)
//将权值数组初始化
memset(weight, 0, sizeof(weight));
int c;
//将读取的直接存入动态可调数组内
vector<int> binaryData;
while (true) {
c = fgetc(fin);
if (feof(fin)) break;
weight[c]++;
binaryData.push_back(c);
}
fclose(fin);- 以字符的权重(权重为0的字符除外)为依据建立哈夫曼树
HuffmanTreeNode **treeNodes = new HuffmanTreeNode *[256 + 1];
//数组从i=1开始,方便最小堆的建立
for (int i = 0; i < 256; i++) {
if (weight[i] == 0) continue;
treeNodes[++count] = new HuffmanTreeNode(weight[i], i);
}
//建立哈夫曼树
HuffmanTree tree(treeNodes, count);- 依据哈夫曼树,得到每一个字符的编码
这一步通过简单而优雅的前序遍历递归方式,获得每个叶节点的编码。从左子树走,编码末尾加0;从右子树走,编码末尾加1。
void HuffmanTree::buildCodeBook() {
buildCode(*root, "");
}
void HuffmanTree::buildCode(HuffmanTreeNode node, string s) {
if (node.isLeaf()) {
codeBook.insert(map<int, string>::value_type(node.data, s));
return;
}
buildCode(*node.left, s + '0');
buildCode(*node.right, s + '1');
}新建压缩文件,写入压缩数据
这一步是难点,也是关键点所在。需要解决的问题:- 现在哈夫曼编码表有了,怎么把它写入到压缩文件中,以便以后解压呢
- 刚才已经提过了,C++IO操作的最小单位是字节(byte)。但是我们的哈夫曼编码是不定长的,并不都是8的倍数,怎么把它存进去呢?
下面来对以上问题逐个击破
第一个问题,我们可以通过将刚刚提到的权值数组写入到压缩文件当中,当解压时先把这个权值数组读取还原出来,然后通过这个权值数组重新构建哈夫曼树即可。当然还有一种更优的办法,就是将哈夫曼树写入到文件当中,因为C++对bit的读写非常坑爹而恶心,所以C++不太好实现,但是用Java可以轻松实现。
这里值得注意的是,千万不能用fputc来写入权值,因为权值的int值会超过255而溢出,实际写入到文件的只是一个字节,即8位。
void HuffmanTree::writeWeight(int *weight, FILE *fout) {
int weightCopy[256];
for (int i = 0; i < 256; ++i) {
weightCopy[i]=weight[i];
}
fwrite(&weightCopy, sizeof(weight[0]), 256, fout);
//for (int i = 0; i < 256; ++i) {
// // fputc(weight[i], fout);
//}
}
HuffmanTree *HuffmanTree::readWeightAndBuildTree(FILE *fin) {
int count = 0;
HuffmanTreeNode **treeNodes = new HuffmanTreeNode *[256 + 1];
int weight[256];
fread(&weight, sizeof(weight[0]), 256, fin);
//从i=1开始,方便最小堆的建立
for (int i = 0; i < 256; i++) {
//int weight = fgetc(fin);
if (weight[i] == 0) continue;
treeNodes[++count] = new HuffmanTreeNode(weight[i], i);
}
return new HuffmanTree(treeNodes, count);
}第二个问题,可以这样,我们可以满8位再以字节的形式写入文件。举个栗子,加入说66对应的哈夫曼编码是011, 77对应的编码是1011100101,那么因为011三位不足8位,所以要加上10111这五位构成一个字节写入到文件中。现在又有一个新问题了,假如到了最后还剩几位不足8位呢,怎么处理写入的最后一个字节呢?这里,我们还需要写入剩余的bit数,假如剩余010这3位,那就还要写入一个值为3的字节和一个值为2(00000 010)的字节(这个字节只有后三位是有效编码,前5位是无用的,解压时只需取后三位译码即可)。
注释已经非常详细了,如果还不懂就对不起我了 - -。
void HuffmanTree::writeCode(vector<int> binaryData, FILE *fout) {
if (binaryData.size() == 0) return;
fpos_t startPos;//记录初始写入的位置
fgetpos(fout, &startPos);
//计数,满八位则写入文件;写java惯坏了,c++所有变量一定先要初始化
long bits = 0;//记录写入压缩文件的比特数
int buffer = 0;//把它当成一个缓存字节,不要被它的int类型迷惑
//需要写入到压缩文件的字节数组
vector<int> codes;
//遍历待编码的数组
for (int i = 0; i < binaryData.size(); ++i) {
//根据码表编码,这个codeBook其实是一个map,key是字节,value是string,即01字符数组
string code = codeBook[binaryData.at(i)];
//对字符数组code遍历,转化成0或1,放入缓存字节当中
for (int j = 0; j < code.size(); j++) {
buffer <<= 1;
if (code[j] == '1')
buffer += 1;
bits++;
if (bits % 8 == 0) {//满8位,则将字节存入codes数组,将缓存字节置零
//cout << buffer << endl;
codes.push_back(buffer);
buffer = 0;
}
}
}
//刚好没有剩余的bit
if (bits % 8 == 0) {
//存入8表示最后一个字节8位都是有用的编码
fputc(8, fout);
int lastCodeBitsCount = bits % 8;
fputc(lastCodeBitsCount, fout);
//写入编码后的数据
for (int i = 0; i < codes.size(); i++){
fputc(codes.at(i), fout);
}
return;
}
//存入lastCodeBitsCount表示最后一个字节只有后lastCodeBitsCount位才是有用的编码
int lastCodeBitsCount = bits % 8;
fputc(lastCodeBitsCount, fout);
//写入编码后的数据
for (int i = 0; i < codes.size(); i++){
fputc(codes.at(i),fout);
}
fputc(buffer, fout);
}
至此压缩完成,下面给一张压缩文件的结构图。
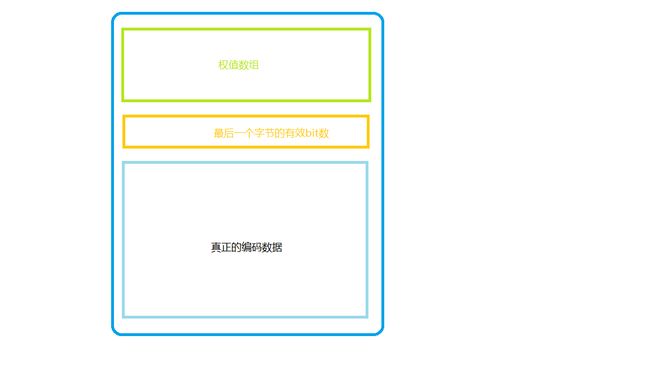
解压
压缩了不能解压是没有意义的。解压就是压缩的逆过程(你这不是废话么),按照写入的顺序读取相应的数据。
- 读取权值数组,构造哈夫曼编码数
HuffmanTree *HuffmanTree::readWeightAndBuildTree(FILE *fin) {
int count = 0;
HuffmanTreeNode **treeNodes = new HuffmanTreeNode *[256 + 1];
int weight[256];
//从压缩文件读取权值数组
fread(&weight, sizeof(weight[0]), 256, fin);
//建树
//从i=1开始,方便最小堆的建立
for (int i = 0; i < 256; i++) {
//int weight = fgetc(fin);
if (weight[i] == 0) continue;
treeNodes[++count] = new HuffmanTreeNode(weight[i], i);
}
return new HuffmanTree(treeNodes, count);
}- 读取最后一个字节对应的有效bit数
- 读取真正数据编码的bit流
这里有一个问题:在真正数据编码的bit流中,原文件的每个字节所对应的哈夫曼码字之间在压缩文件中是连续无间隔的。那该怎么读取呢?
我们可以用一个工作指针,从哈夫曼树的根节点开始,每次从压缩文件中读取一个bit,如果是0,指针指向左孩子,如果是1,指针指向右孩子。一旦指针指向了叶结点,立刻将该节点对应的字节数据写入到解压后的文件中,指针重新回到根节点,循环执行上面步骤,直到读到文件尾。
有人可能会马上站出来说,“这不是坑爹么?你不是说C++的读写操作最小单位是字节,怎么能每次只读一个bit呢?”作为一个面向对象的程序员,完全可以很优雅地把读取bit的功能封装到一个类当中,在C++的文件IO流基础上包装一层。我把这个类起名为BitStream,这个类内部维护了一个队列,queue< bool> stream,储存读取的bit流。当被调用getBit()方法时,从队列中取出一个bit并返回。如果队列为空,自动从压缩文件的io流读取一个字节,将这个字节分解成01串压到队列当中。
void HuffmanTree::decode(FILE *fin, FILE *fout) {
if (fin == NULL) {
cout << "file not found" << endl;
return;
}
HuffmanTree *tree = readWeightAndBuildTree(fin);
int lastCodeBitsCount = fgetc(fin);
BitStream stream(fin, lastCodeBitsCount);
bool bit;
HuffmanTreeNode *p = tree->getRoot();
while (stream.getBit(bit)) {
if (bit == 0) p = p->left;
else p = p->right;
if (p != NULL && p->isLeaf()) {
fputc(p->data, fout);
p = tree->getRoot();
}
}
fclose(fin);
fclose(fout);
}这个压缩算法适合像txt、bmp位图这样的文件,对于一些矢量图如jpg压缩效果并不好,甚至会压缩文件出现比原文件还大的情况。
至此Huffman解压缩主体内容就讲解完毕了。下面吐槽几句:
本次代码我是用CLion写的,原因是它比VS好用10倍以上,但它的调试功能远远比不上VS,所以代码调试是用VS2013。然而我还是想不明白,为什么Visual Studio会被称为宇宙第一IDE,它那代码编写功能我觉得连eclipse都比不上。- -
听说留下源码也是一种美德。— Github地址(内含C++函数文档)
如果你发现有什么不清楚或不妥的地方欢迎留言讨论。