Zeppelin 安装部署实验
一、实验目的
1. 使用Zeppelin运行SparkSQL访问Hive表
2. 动态表单SQL
二、实验环境:
12个节点的Spark集群,以standalone方式部署,各个节点运行的进程如表1所示。
操作系统:CentOS release 6.4
Hadoop版本:2.7.0
Hive版本:2.0.0
Spark版本:1.6.0
本实验在nbidc-agent-04上安装部署Zeppelin
Hadoop集群的安装配置参考 http://blog.csdn.net/wzy0623/article/details/50681554
hive的安装配置参考 http://blog.csdn.net/wzy0623/article/details/50685966
Spark集群的安装配置参考 http://blog.csdn.net/wzy0623/article/details/50946766
三、安装Zeppelin
前提:nbidc-agent-04需要能够连接互联网。
1. 安装Git
在nbidc-agent-04上执行下面的指令:
在nbidc-agent-03机器上执行下面的指令拷贝Java安装目录到nbidc-agent-04机器上。
在nbidc-agent-04上执行下面的指令:
在nbidc-agent-03机器上执行下面的指令拷贝Hadoop安装目录到nbidc-agent-04机器上。
在nbidc-agent-03机器上执行下面的指令拷贝Spark安装目录到nbidc-agent-04机器上。
在nbidc-agent-03机器上执行下面的指令拷贝Hive安装目录到nbidc-agent-04机器上。
在nbidc-agent-04上执行下面的指令:
在nbidc-agent-04上执行下面的指令:
在nbidc-agent-04上执行下面的指令:
vi /home/work/.bashrc
在nbidc-agent-04上执行下面的指令:
四、配置zeppelin
1. 配置zeppelin-env.sh文件
在nbidc-agent-04上执行下面的指令:
在nbidc-agent-04上执行下面的指令:
在nbidc-agent-04上执行下面的指令:
五、启动zeppelin
在nbidc-agent-04上执行下面的指令:
六、测试
从浏览器输入http://nbidc-agent-04:9090/,如图1所示。
这是一个动态表单SQL,SparkSQL语句为:
参考:
https://zeppelin.incubator.apache.org/docs/0.5.6-incubating/
1. 使用Zeppelin运行SparkSQL访问Hive表
2. 动态表单SQL
二、实验环境:
12个节点的Spark集群,以standalone方式部署,各个节点运行的进程如表1所示。
| 主机名 |
运行进程 |
| nbidc-agent-03 |
Hadoop NameNode Spark Master |
| nbidc-agent-04 |
Hadoop SecondaryNameNode |
| nbidc-agent-11 |
Hadoop ResourceManager Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-12 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-13 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-14 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-15 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-18 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-19 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-20 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-21 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
| nbidc-agent-22 |
Hadoop DataNode、Hadoop NodeManager、Spark Worker |
表1
操作系统:CentOS release 6.4
Hadoop版本:2.7.0
Hive版本:2.0.0
Spark版本:1.6.0
本实验在nbidc-agent-04上安装部署Zeppelin
Hadoop集群的安装配置参考 http://blog.csdn.net/wzy0623/article/details/50681554
hive的安装配置参考 http://blog.csdn.net/wzy0623/article/details/50685966
Spark集群的安装配置参考 http://blog.csdn.net/wzy0623/article/details/50946766
三、安装Zeppelin
前提:nbidc-agent-04需要能够连接互联网。
1. 安装Git
在nbidc-agent-04上执行下面的指令:
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel yum install gcc perl-ExtUtils-MakeMaker yum remove git cd /home/work/tools/ wget https://github.com/git/git/archive/v2.8.1.tar.gz tar -zxvf git-2.8.1.tar.gz cd git-2.8.1.tar.gz make prefix=/home/work/tools/git all make prefix=/home/work/tools/git install2. 安装Java
在nbidc-agent-03机器上执行下面的指令拷贝Java安装目录到nbidc-agent-04机器上。
scp -r jdk1.7.0_75 nbidc-agent-04:/home/work/tools/3. 安装Apache Maven
在nbidc-agent-04上执行下面的指令:
cd /home/work/tools/ wget ftp://mirror.reverse.net/pub/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz tar -zxvf apache-maven-3.3.9-bin.tar.gz4. 安装Hadoop客户端
在nbidc-agent-03机器上执行下面的指令拷贝Hadoop安装目录到nbidc-agent-04机器上。
scp -r hadoop nbidc-agent-04:/home/work/tools/5. 安装Spark客户端
在nbidc-agent-03机器上执行下面的指令拷贝Spark安装目录到nbidc-agent-04机器上。
scp -r spark nbidc-agent-04:/home/work/tools/6. 安装Hive客户端
在nbidc-agent-03机器上执行下面的指令拷贝Hive安装目录到nbidc-agent-04机器上。
scp -r hive nbidc-agent-04:/home/work/tools/7. 安装phantomjs
在nbidc-agent-04上执行下面的指令:
cd /home/work/tools/ tar -jxvf phantomjs-2.1.1-linux-x86_64.tar.bz28. 下载最新的zeppelin源码
在nbidc-agent-04上执行下面的指令:
cd /home/work/tools/ git clone https://github.com/apache/incubator-zeppelin.git9. 设置环境变量
在nbidc-agent-04上执行下面的指令:
vi /home/work/.bashrc
# 添加下面的内容 export PATH=.:$PATH:/home/work/tools/jdk1.7.0_75/bin:/home/work/tools/hadoop/bin:/home/work/tools/spark/bin:/home/work/tools/hive/bin:/home/work/tools/phantomjs-2.1.1-linux-x86_64/bin:/home/work/tools/incubator-zeppelin/bin; export JAVA_HOME=/home/work/tools/jdk1.7.0_75 export HADOOP_HOME=/home/work/tools/hadoop export SPARK_HOME=/home/work/tools/spark export HIVE_HOME=/home/work/tools/hive export ZEPPELIN_HOME=/home/work/tools/incubator-zeppelin # 保存文件,并是设置生效 source /home/work/.bashrc10. 编译zeppelin源码
在nbidc-agent-04上执行下面的指令:
cd /home/work/tools/incubator-zeppelin mvn clean package -Pspark-1.6 -Dspark.version=1.6.0 -Dhadoop.version=2.7.0 -Phadoop-2.6 -Pyarn -DskipTests
四、配置zeppelin
1. 配置zeppelin-env.sh文件
在nbidc-agent-04上执行下面的指令:
cp /home/work/tools/incubator-zeppelin/conf/zeppelin-env.sh.template /home/work/tools/incubator-zeppelin/conf/zeppelin-env.shvi /home/work/tools/incubator-zeppelin/conf/zeppelin-env.sh
# 添加下面的内容 export JAVA_HOME=/home/work/tools/jdk1.7.0_75 export HADOOP_CONF_DIR=/home/work/tools/hadoop/etc/hadoop export MASTER=spark://nbidc-agent-03:70772. 配置zeppelin-site.xml
在nbidc-agent-04上执行下面的指令:
cp /home/work/tools/incubator-zeppelin/conf/zeppelin-site.xml.template /home/work/tools/incubator-zeppelin/conf/zeppelin-site.xmlvi /home/work/tools/incubator-zeppelin/conf/zeppelin-site.xml
# 修改下面这段的value值,设置zeppelin的端口为9090 <property> <name>zeppelin.server.port</name> <value>9090</value> <description>Server port.</description> </property>3. 将hive-site.xml拷贝到zeppelin的配置目录下
在nbidc-agent-04上执行下面的指令:
cd /home/work/tools/incubator-zeppelin cp /home/work/tools/hive/conf/hive-site.xml .
五、启动zeppelin
在nbidc-agent-04上执行下面的指令:
zeppelin-daemon.sh start
六、测试
从浏览器输入http://nbidc-agent-04:9090/,如图1所示。
图1
点击'Interpreter'菜单,配置并保存spark和hive解释器,分别如图2、图3所示。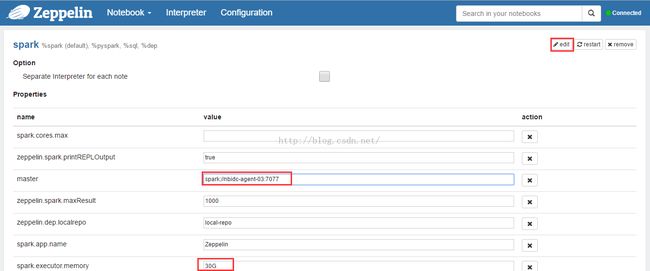
图2
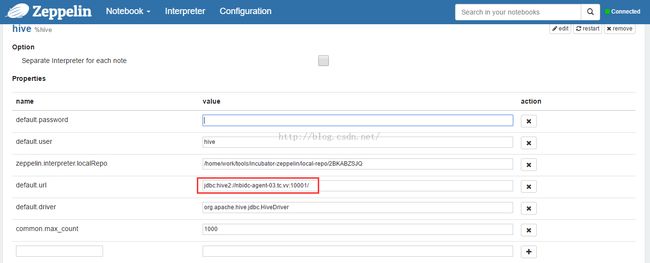
图3
点击'NoteBook'->'Create new note'子菜单项,建立一个新的查询并执行,结果如图4所示。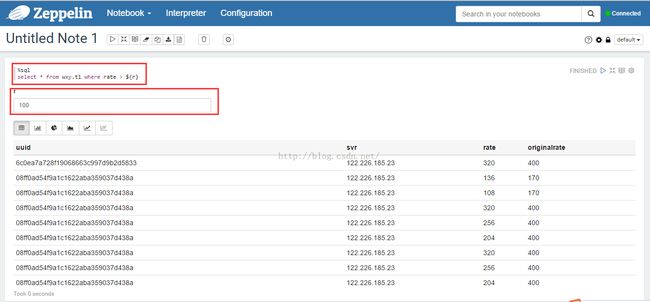
图4
说明:这是一个动态表单SQL,SparkSQL语句为:
%sql
select * from wxy.t1 where rate > ${r}第一行指定解释器为SparkSQL,第二行用${r}指定一个运行时参数,执行时页面上会出现一个文本编辑框,输入参数后回车,查询会按照指定参数进行,如图会查询rate > 100的记录。
参考:
https://zeppelin.incubator.apache.org/docs/0.5.6-incubating/