hadoop-2.2.0+hbase-0.96.0测试集群搭建
1、环境介绍:ubuntu13.04虚拟机3台:master、s1、s2;jdk1.7.0_40;hadoop-2.2.0;hbase-0.96.0;
2、分别配置好三台机器的JAVA_HOME,hosts,hostname配置分别为master、s1、s2。
3、解压hadoop包,配置$HADOOP_HOME/ect/hadoop/hadoop-env.sh

4,、配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/opt/hadoop-2.2.0/temp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>5、配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/opt/hadoop-2.2.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/opt/hadoop-2.2.0/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
6、配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
<description>host is the hostname of the resource manager and
port is the port on which the NodeManagers contact the Resource Manager.
</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
<description>host is the hostname of the resourcemanager and port is the port
on which the Applications in the cluster talk to the Resource Manager.
</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
<description>In case you do not want to use the default scheduler</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
<description>the host is the hostname of the ResourceManager and the port is the port on
which the clients can talk to the Resource Manager. </description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>${hadoop.tmp.dir}/nodemanager/local</value>
<description>the local directories used by the nodemanager</description>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>master:8034</value>
<description>the nodemanagers bind to this port</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>10240</value>
<description>the amount of memory on the NodeManager in GB</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>${hadoop.tmp.dir}/nodemanager/remote</value>
<description>directory on hdfs where the application logs are moved to </description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>${hadoop.tmp.dir}/nodemanager/logs</value>
<description>the directories used by Nodemanagers as log directories</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run </description>
</property>
</configuration>7、配置yarn-env.sh里面的JAVA_HOME
8、配置slaves.写入s1、s2。
此时需求的工作差不多已经完成。以上所有步骤在master机器上进行。接下来配置3台机器之间的ssh免密码登录。
1、在master执行命令 ssh-keygen -t rsa -P '',继续回车。之后在.ssh/下生成id_rsa.pub和id_rsa。然后将id_rsa.pub发送到s1的.ssh/下,并执行cat id_rsa.pub >>authorized_keys,设置authorized_keys权限为600。
2、从master直接ssh到s1,第一次要确认下,输入yes。此时就可以从master免密码登录s1。如果要互相免密码登录,就在不同的机器做以上操作,登录机器的公钥要被追加到被登录机器。
经过以上工作之后,scp发送配置好的hadoop到s1和s2.然后在master上启动hadoop。
1、首先格式化文件系统,./hdfs namenode -format。
2、启动 ./sbin/start-yarn.sh,./sbin/start-dfs.sh,成功之后会有namenode 和secondarynamenode的进程,在s1和s2会有datanode的进程。
接下来安装hbase-0.96.0
1、解压hbase-0.96.0-hadoop2-bin.tar.gz,配置$HBASE_HOME/conf/hbase-env.sh
export JAVA_HOME=/usr/local/opt/jdk1.7.0_40
export HBASE_MANAGES_ZK=true,这里使用hbase内部zookeeper,也可自行安装
2、配置hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,s1,s2</value> </property> <property> <name>hbase.master</name> <value>master:60000</value> <description>The host and port that the HBase master runs at.</description> </property> </configuration>3、配置regionservers,内容为s1、s2
4、替换hbase下的
hadoop-common-2.1.0-beta.jar
hadoop-hdfs-2.1.0-beta.jar
hadoop-auth-2.1.0-beta.jar
为hadoop下的
hadoop-common-2.2.0.jar
hadoop-hdfs-2.2.0.jar
hadoop-auth-2.2.0.jar
否则会启动报错,或者HMaster进程挂掉。
5、scp配置好的hbase到s1和s2
6、在master执行启动命令:./start-hbase.sh 成功后通过jps查看如下
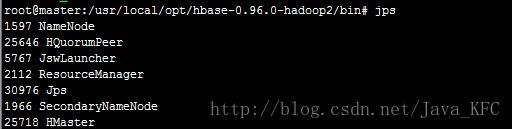
可通过master:60010查看web界面
