MapReduce练习(一)
MapReduce练习(一)
路由日志:
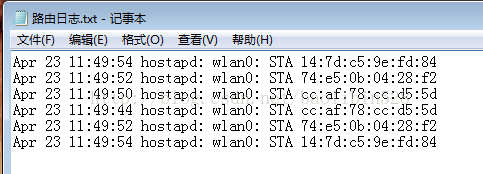
如下:
Apr 23 11:49:54 hostapd: wlan0: STA14:7d:c5:9e:fd:84
Apr 23 11:49:52 hostapd: wlan0: STA74:e5:0b:04:28:f2
Apr 23 11:49:50 hostapd: wlan0: STAcc:af:78:cc:d5:5d
Apr 23 11:49:44 hostapd: wlan0: STAcc:af:78:cc:d5:5d
Apr 23 11:49:52 hostapd: wlan0: STA74:e5:0b:04:28:f2
Apr 23 11:49:54 hostapd: wlan0: STA14:7d:c5:9e:fd:84
要求:
提取时间和MAC地址,删除其它部分。
代码解析:
package hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Luyou extends Configured implements Tool{
//Counter即是一个计数器,可以记录这个程序的一些数据用于统计
enum Counter{
LINESKIP, //出错的行
}
public static class Map extends Mapper<LongWritable,Text,NullWritable,Text>{
public void map(LongWritable key,Text value,Context context) throws IOException{
//读取源文件,line得到的就是输入文件的一行数据
String line=value.toString();
try{
//对源数据进行分割和重组
String [] lineSplit=line.split(" ");
String month =lineSplit[0];
String time=lineSplit[1];
String mac=lineSplit[6];
Text out=new Text(month+' '+time+' '+mac);
//把两个参数分别作为KEY和VALUE输出
context.write(NullWritable.get(), out);
}catch(Exception e){
//如果发生异常,则指定计数器中的LINESKIP自增
context.getCounter(Counter.LINESKIP).increment(1);
return;
}
}
}
public int run(String[] args) throws Exception {
Configuration conf=getConf();
//任务名
Job job=new Job(conf,"Luyou");
//指定Class,必须是当前所在的Class名
job.setJarByClass(Luyou.class);
//输入路径
FileInputFormat.addInputPath(job,new Path(args[0]));
//输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//调用上面Map类作为Map任务代码
job.setMapperClass(Map.class);
job.setOutputFormatClass(TextOutputFormat.class);
//指定输出KEY格式
job.setOutputKeyClass(NullWritable.class);
//指定输出VALUE格式
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
//输出任务完成情况
System.out.println("任务名称"+job.getJobName());
System.out.println("任务成功"+(job.isSuccessful()?"是":"否"));
System.out.println("跳过的行"+job.getCounters().findCounter(Counter.LINESKIP).getValue());
return job.isSuccessful()?0:1;
}
public static void main(String args[]) throws Exception{
//在main函数调用run方法,启动一个mr任务
int res=ToolRunner.run(new Configuration(), new Luyou(),args);
System.exit(res);
}
}
启动hadoop:

路由日志上传到hdfs:
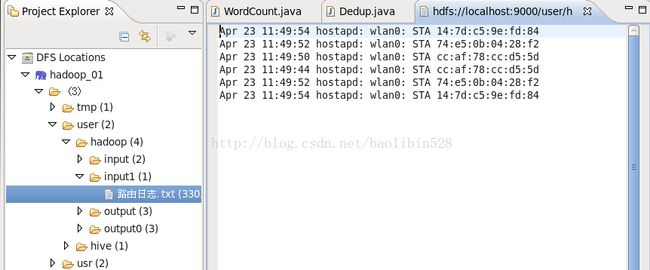
导入的包:

Map函数:

Run方法:

主函数:

类名和记录出错的小函数:

设置hdfs输入输出路径:

运行结果:
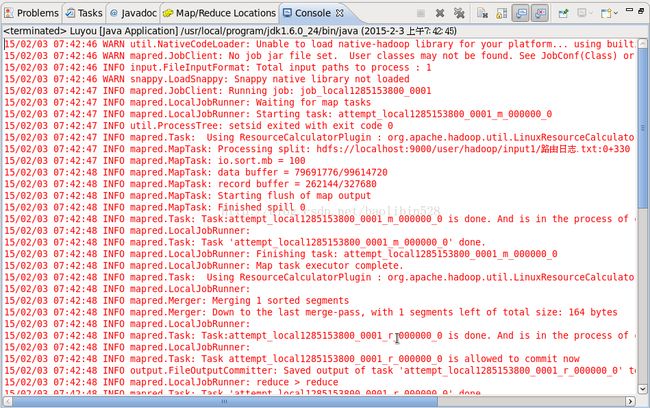
如下:
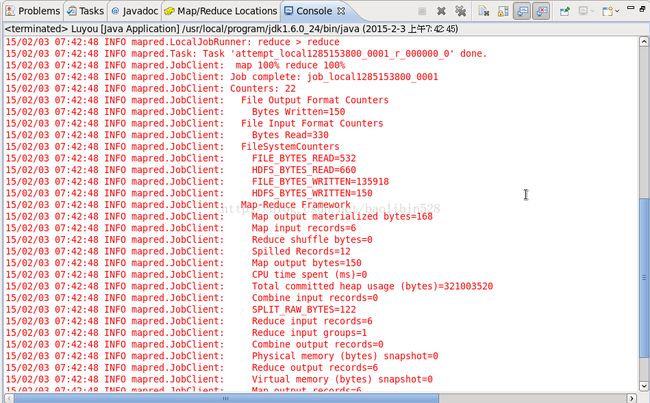
如下:
结果:
