搭建hadoop集群环境
Wmware搭建hadoop集群环境
搭建环境及软件:window7、VMware10、centOS、jdk1.7、hadoop-1.2.1、hbase-0.94.7、hive-0.9、zookeeper-3.4.5
Linux系统环境配置
Vmware中的三台机器
hadoop-manager:NameNode、JobTracker、SecondaryNameNode
hadoop-client1:dataNode、taskTracker
hadoop-client2:dataNode、taskTracker
1.启动hadoop_manager机器
2.鼠标右键点击右上角电脑的图标,如图
![]()
3.在弹出的列表选择Editconnections
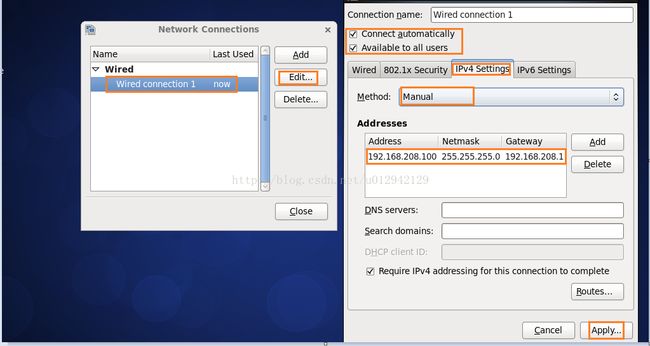
4.按如下步骤,修改ip地址,子网掩码,网关,填写好之后点击Apply,修改完之后重启网卡service network restart,如重启报错可以将wired下的连接全部delete,重新add一个新的配置就可以了。建也可以使用命令修改(vi /etc/sysconfig/network-scripts/ifcfg-eth0)议用root用户操作。
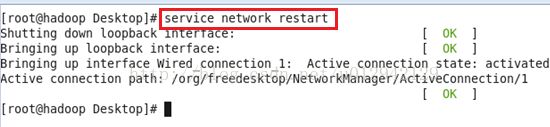
重启网卡service network restart
注:ip地址,子网掩码,网关要根据自己windows的环境填写,可通过cmdàipconfig命令查看,本人windows环境为
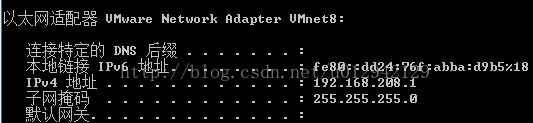
5.在其他机器上做同样操作,我三个节点ip分别为:
Hadoop-manager :192.168.208.100
Hadoop-client1: 192.168.208.101
Hadoop-client2: 192.168.208.102
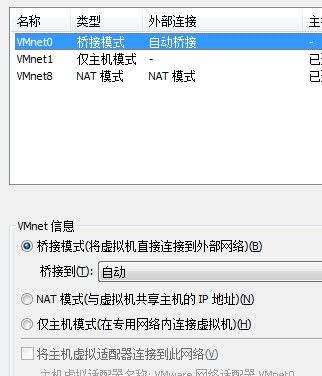
完成之后在windows上分别ping这三个ip是否能ping通,如ping不通到虚拟机设置中将网络连接改成NAT模式,再在linux中ping windows,如果ping不通需要关闭windows防火墙,家庭或工作和公用网络位置两处都要关闭。

这里linux的ip和wmnet8在同一网段所以选择了NAT,如果linux的ip和wmnet1在同一网段那应该选择仅主机模式,这个对应关系可在vmware的安装目录vmnetcfg.exe查看或修改,(C:\Program Files (x86)\VMware\VMware Workstation\vmnetcfg.exe)这个完全是个人理解
6.修改机器名:vi/etc/sysconfig/network (root用户操作),修改完之后用输入hostname命令查看是否修改成功。
修改后发现hostname没有改变还是原来的localhost.localdomain,执行 source /etc/sysconfig/network和service network restart都不行。只有重启机器了。
![]()
重启之后三台机器分别是:
![]()
![]()
![]()
7.为以后操作方便修改每台机器hosts文件,vi/etc/hosts(用root用户修改),修改如图

8.配置ssh免密码登陆
8.1.需要切换到hadoop用户操作:suhadoop
8.2切换到用户根目录:cd ~
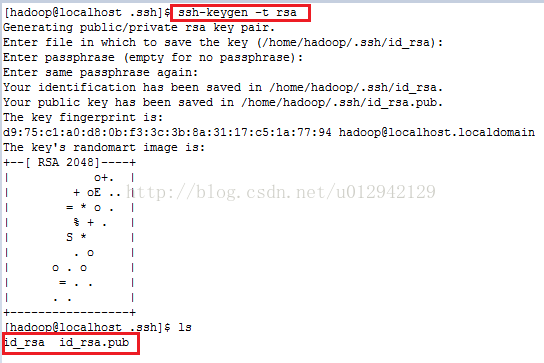
8.3进入每台机器的.ssh目录(.ssh是隐藏目录,可使用ls –a查看)cd .ssh执行命令ssh-keygen–t rsa(用rsa方式生成密钥),再敲三下回车,然后会生成两个文件id_rsa(私钥)和id_rsa.pub(公钥),如图:
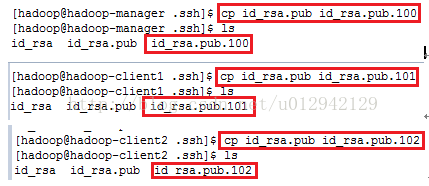
8.4将各机器将生成的 id_rsa.pub复制并重命名:如图
8.5将hadoop-client1的id_rsa.pub.101和hadoop-client2的id_rsa.pub.102复制到hadoop-manager机器上
在hadoop-client1:机器如图:
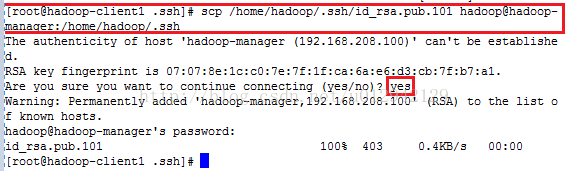
在hadoop-client2:机器如图:

8.6在hadoop-manager机器上执行cd/home/hadoop/.ssh,再ls可以看见scp过来的两个文件
![]()
8.7执行:将id_rsa.pub.100、id_rsa.pub.101、id_rsa.pub.102文件的内容写到authorized_keys文件。如图:
![]()
8.8 修改authorized_keys文件的权限

8.9.将authorized_key复制另外两台机器
在hadoop-manager机器上执行:
scp /home/hadoop/.ssh/authorized_keyshadoop@hadoop-client1:/home/hadoop/.ssh/
scp /home/hadoop/.ssh/authorized_keyshadoop@hadoop-client2:/home/hadoop/.ssh/
8.10测试:ssh localhost、sshhadoop-client1、ssh hadoop-client2 ,每台机器都可以免密码登陆到其他机器。
安装hadoop环境
为了以后安装方便现将所有的安装都上传到Linux,我用的linux用户是hadoop
安装jdk
1.cd /home/hadoop/Downloads
2解压jdk: tar -zxvf jdk-7u67-linux-i586.tar.gz
3 将解压后的文件夹移动到 /home/hadoop/目录下:mv jdk1.7.0_67 ../
4 添加环境变量
4.1 切换到root用户:su root
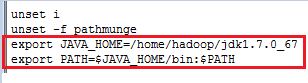
4.2 vi /etc/profile在最下面加入:
exportJAVA_HOME=/home/hadoop/jdk1.7.0_67
export PATH=$JAVA_HOME/bin:$PATH
如图:
注:刚设置环境变量时第二行的最后没有写“:$PATH”,保存之后导致ls,ifconfig,vi等命令无法使用,出现这种情况需要执行命令:exportPATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin可恢复,但不确定是不是因为环境变量没有加:$PATH导致。
4.3保存之后让profile文件立即生效,source /etc/profile
4.4测试jdk环境变量是否正确,命令:java、javac、java –version
安装hadoop
1. cd到cd/home/hadoop/Downloads解压hadoop:tar -zxvf hadoop-1.2.1.tar.gz
2. 更改安装目录:mv hadoop-1.2.1 ../
3. vi /etv/profile增加hadoop的环境变量(root用户),如图

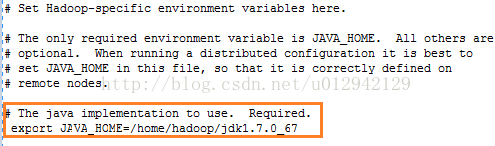
4.vi /home/hadoop/hadoop-1.2.1/conf/hadoop-env.sh
5 vi /home/hadoop/hadoop-1.2.1/conf/core-site.xml,如图
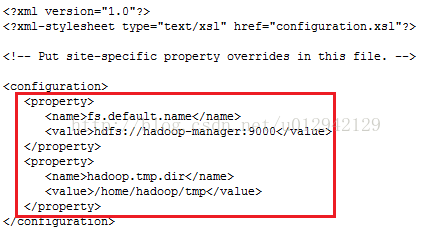
6. vi /home/hadoop/hadoop-1.2.1/conf/hdfs-site.xml
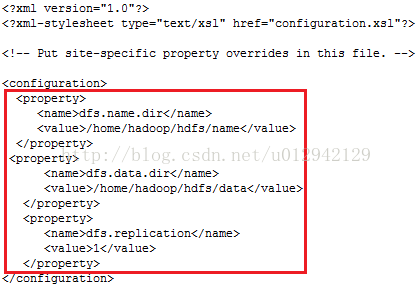
dfs.replication是hdfs的副本数,一般会设置成3,这个只是学习测试先写1。
7. vi /home/hadoop/hadoop-1.2.1/conf/mapred-site.xml
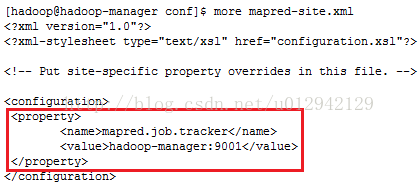
8.修改完配置文件后格式化namenode:hadoop namenode –format,可能会报异常Warning: $HADOOP_HOME is deprecated,不过没关系,不用理他。
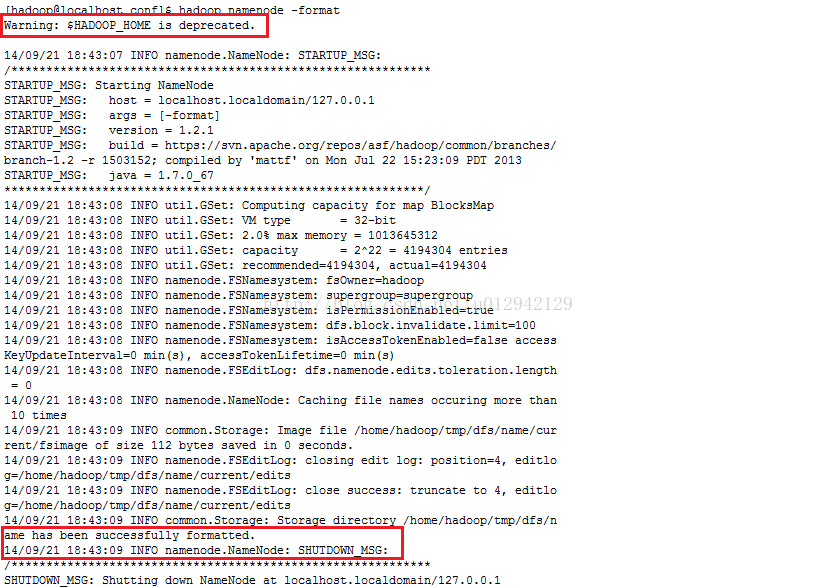
9.启动hadoop:start-all.sh输入jps验证是否启动成功,启动成功会有5个进程。分别是jobtracker、tasktracker、datanode、namenote、secondarynamenode
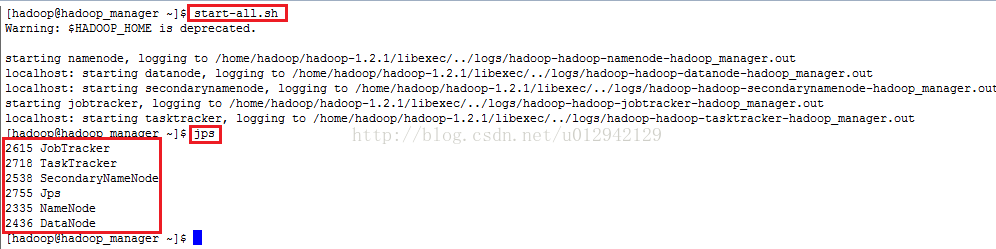
到此单机模式已经搭建完成。
10.集群搭建
10.1修改masters和slaves文件
vi /home/hadoop/hadoop-1.2.1/conf/masters,填写主节点的主机名hadoop-manager,也可以使用ip
![]()
vi /home/hadoop/hadoop-1.2.1/conf/masters,填写主节点的主机名hadoop-client1、hadoop-client2
![]()
10.2复制jdk、hadoop和profile文件到另外两台机器
在hadoop-manager机器上输入命令:
scp -r /home/hadoop/hadoop-1.2.1/hadoop@hadoop-client1:/home/hadoop/
scp -r /home/hadoop/hadoop-1.2.1/hadoop@hadoop-client2:/home/hadoop/
scp -r /home/hadoop/jdk1.7.0_67/hadoop@hadoop-client1:/home/hadoop/
scp -r /home/hadoop/jdk1.7.0_67/hadoop@hadoop-client2:/home/hadoop/
scp -r /etc/profile root@hadoop-client1:/etc/
scp -r /etc/profile root@hadoop-client2:/etc/
10.3格式化:hadoop namenode –format
10.4启动:start-all.sh
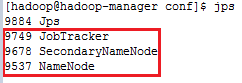
10.5测试:
在主节点hadoop-manager机器上输入jps:
在从节点的两台机器上输入jps:
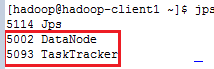
到此hadoop集群安装已经完成。
安装hive
1.登陆hadoop-manager机器cd到安装包所在目录并解压
2.将解压后的文件夹移动到用户根目录下: mvhive-0.9.0 ../
3.增加环境变量 vi/etc/profile(root用户),修改完成后要执行source /etc/profile,然后切换到hadoop用户。

4. 修改hive配置文件
4.1 cd /home/hadoop/hive-0.9.0/conf
4.2 执行命令:
cp hive-default.xml.template hive-site.xml
cp hive-env.sh.template hive-env.sh
4.3 vi hive-env.sh
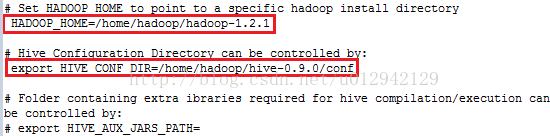
4.3 启动hive,有warning但不影响使用,可输入一些命令测试。
4.4 默认情况下hive使用derby数据库存储,现将改成mysql存储
vi /home/hadoop/hive-0.9.0/conf/hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.22.1.235:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for aJDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for aJDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use againstmetastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use againstmetastore database</description>
</property>
将本地(Linux系统)数据导入hive表:LOAD DATA LOCAL INPATH '/home/work/test.txt' INTO TABLE XXX_TABLE;
将HDFS数据导入hive表:LOAD DATA INPATH '/data/test/test.txt' INTO TABLE XXX_TABLE;
导入数据时,数据文件的格式要和hive表的结构相同。
到此hive安装结束。
安装zookeeper
1. 解压zookeeper安装包tar -zxvf zookeeper-3.4.5.tar.gz
2. 用root用户添加环境变量vi /etc/profile,添完之后执行source /etc/profile

3. 修改配置文件
3.1 cd /home/hadoop/zookeeper-3.4.5/conf
3.2 cp zoo_sample.cfg zoo.cfg
3.3 vi zoo.cfg,修改DataDir的值:DataDir=/home/hadoop/zookeeper-3.4.5/data,同时创建/home/hadoop/zookeeper-3.4.5/data
3.4 在zoo.cfg最后增加:
server.0=hadoop-manager:2888:3888
server.1=hadoop-client1:2888:3888
server.2=hadoop-client2:2888:3888
3.5在/home/hadoop/zookeeper-3.4.5/data目录下创建文件名为myid的文件并写0,
3.6配置其它机器,
scp -r/home/hadoop/zookeeper-3.4.5/ hadoop@hadoop-client1:/home/hadoop/
scp -r /home/hadoop/zookeeper-3.4.5/ hadoop@hadoop-client2:/home/hadoop/
复制完后修改myid文件hadoop-client1机器改成1,hadoop-client2机器改成2
增加hadoop-client1和hadoop-client2机器的环境变量,和hadoop-manager机器一样,hadoop-manager机器有hive的环境变量,hadoop-client1和hadoop-client2没有安装hive所以不需要hive的环境变量。如图:
3.7启动zookeeper:
分别在每台机器上执行zkServer.sh start启动zookeeper,启动之后输入jps会增加一个QuorumPeerMain进程,或分别在每台机器上执行命令zkServer.sh status,其中两台机器会出现Mode: follower,一台机器会出现Mode: leader。启动zookeeper之前要先启动hadoop。
zookeeper安装结束
安装hbase
1. 解压安装包 tar –zxvf tar -zxvf hbase-0.94.7-security.tar.gz,将解压后的文件夹名改成hbase-0.94.7
2. 添加环境变量

3. 修改配置文件cd /home/hadoop/hbase-0.94.7/conf
3.1 vi hbase-env.sh添加:
export JAVA_HOME=/home/hadoop/jdk1.7.0_67
export HBASE_MANAGES_ZK=false
3.2 vi hbase-site.xml,hbase.rootdir属性值必需和Hadoop集群的core-site.xml文件配置保持完全一致
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-manager:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-manager,hadoop-client1,hadoop-client2</value>
</property>
3.3 vi regionservers,写从节点的两台主机名
hadoop-client1
hadoop-client2
4. 将hbase-0.94.7文件夹复制到其它机器上
scp -r /home/hadoop/hbase-0.94.7/hadoop@hadoop-client1:/home/hadoop/
scp -r /home/hadoop/hbase-0.94.7/ hadoop@hadoop-client2:/home/hadoop/
5. 修改另外两台机器的环境变量

6. 启动hbase集群,要在主节点启动:start-hbase.sh,启动hbase集群前确保hadoop和zookeeper集群已经启动,启动之后主节点jps会增加一个HMaster进程,从节点jps会增加HRegionServer进程,也可以在浏览器访问http://hadoop-manager:60010/master.jsp和http://hadoop-client1:60030/master.jsp,能访问说明已经安装成功。在windows中测试要修改windows的hosts文件或使用ip访问。安装成功后使用命令hbase shell进入hbase的命令行。
Sqoop安装
1. 解压sqoop安装包
2. 设置环境变量

3. 修改配置文件
3.1 进入配置文件目录:cd /home/hadoop/sqoop-1.4.3/conf
3.2 cp sqoop-env-template.shsqoop-env.sh并修改sqoop-env.sh
#Setpath to where bin/hadoop is available
exportHADOOP_COMMON_HOME=/home/hadoop/hadoop-1.2.1
#Setpath to where hadoop-*-core.jar is available
exportHADOOP_MAPRED_HOME=/home/hadoop/hadoop-1.2.1
#set thepath to where bin/hbase is available
exportHBASE_HOME=/home/hadoop/hbase-0.94.7
#Set thepath to where bin/hive is available
exportHIVE_HOME=/home/hadoop/hive-0.9.0
#Set thepath for where zookeper config dir is
exportZOOCFGDIR=/home/hadoop/zookeeper-3.4.5
4. 运行:从hdfs将数据导入到mysql数据库叫ip的一张表里,part-r-00000是mapreduce生产的文件,最后面的“’\t’”是part-r-00000文件数据项的分隔符。“--”是sqoop的语法不是注释。
sqoop export --connect"jdbc:mysql://172.22.1.46:3306/hive?useUnicode=true&characterEncoding=utf-8"--username root --password 123456 --table ip --export-dir'/out/ipDistribute/2014_04_01/part-r-00000' --fields-terminated-by '\t'